A New Representation of Skeleton Sequences for 3D Action Recognition
Qiuhong Ke, Mohammed Bennamoun, Senjian An, Ferdous Sohel, Farid Boussaid
(v1: 3/9/2017)cs.CV
CVPR 2017
论文精度:
NTU-RGBD
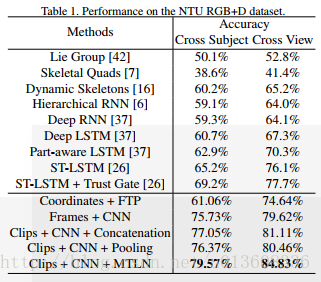
SBU:93.57%
CMU:93.22% ,88.30%
主要方法:
用3D骨架的轨迹来做动作识别
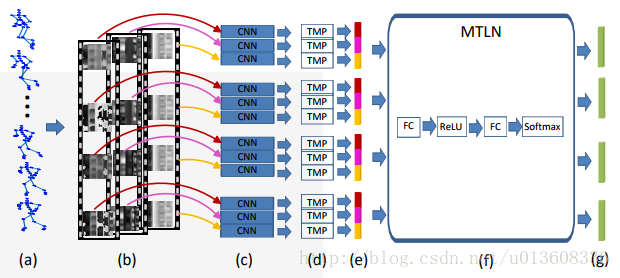
每一段video都转换成四张图片。
根据节点的位置关系,生成四个矩阵,再把这四个矩阵归一化到0-255之间,变成灰度图片,再送入网络提特征。
1.New Representation:四张图片如何来:
以左肩 右肩左臀右臀作为基准点,计算和其他节点的相对位置,由此得到四个矩阵,四个图片维度(m-1)X t
m:关节点个数,t:帧数
因为每张图片都是针对同一个节点的,因此同一张图片都是 spatial invariarant的,所以描述出来的temporal dynaminc都很鲁棒。
2.网络结构:
先用VGG的前五层提特征,得到14X14x512的特征向量
再在行上(时间上)做池化,池化kernel 14x1
再将得到的14X512个feature map串联
4个feature map得到四个prediction,这4个task的得分用来计算一个总的损失函数,学习网络参数。