论文全文中英对照翻译。
论文原文:点击此处
论文期刊:ICCV
论文年份:2015
论文被引:1141(4/17/20)
文章目录
Multi-view Convolutional Neural Networks for 3D Shape Recognition
Abstract
A longstanding question in computer vision concerns the representation of 3D shapes for recognition: should 3D shapes be represented with descriptors operating on their native 3D formats, such as voxel grid or polygon mesh, or can they be effectively represented with view-based descriptors? We address this question in the context of learning to recognize 3D shapes from a collection of their rendered views on 2D images. We first present a standard CNN architecture trained to recognize the shapes’ rendered views independently of each other, and show that a 3D shape can be recognized even from a single view at an accuracy far higher than using state-of-the-art 3D shape descriptors. Recognition rates further increase when multiple views of the shapes are provided. In addition, we present a novel CNN architecture that combines information from multiple views of a 3D shape into a single and compact shape descriptor offering even better recognition performance. The same architecture can be applied to accurately recognize human hand-drawn sketches of shapes. We conclude that a collection of 2D views can be highly informative for 3D shape recognition and is amenable to emerging CNN architectures and their derivatives.
计算机视觉中一个长期存在的问题是三维形状的识别表示:三维形状应该用基于其原始三维格式(如体素网格或多边形网格)的描述来表示,还是用基于视图的描述来有效地表示?我们在学习从二维图像的渲染视图集合中识别三维形状的背景下解决了这个问题。我们首先提出了一个标准的CNN体系结构,该体系结构能够独立地识别形状的渲染视图,并且表明,即使从单个视图也可以识别出三维形状,其精度远远高于使用最先进的三维形状描述。 当提供形状的多个视图时,识别率进一步提高。此外,我们还提出了一种新的CNN结构,它将来自3D形状的多个视图的信息组合成一个单一而紧凑的形状描述,从而提供更好的识别性能。 同样的架构也可以应用于准确识别人类手绘的形状草图。我们的结论是,二维视图的集合可以为三维形状识别提供高度的信息,并且适合于新兴的CNN体系结构及其衍生物。
1. Introduction
计算机视觉的基本挑战之一是从二维图像中推断出三维空间的信息。由于很少有人能够访问三维对象模型,因此通常必须学会从不同的角度根据三维对象的二维外观识别和推理三维对象。因此,计算机视觉研究人员通常从二维图像的二维特征中发展出目标识别算法,并利用它们对这些目标的新二维图像进行分类。
但是,如果一个人可以访问每个感兴趣的对象的三维模型呢?在这种情况下,可以直接训练三维特征的识别算法,如体素占有率(voxel occupancy)或曲面曲率(surface curvature)。最近,随着3D Warehouse、TurboSquid和Shapeways等大型3D形状存储库的引入,直接从3D表示中构建3D形状分类器的可能性已经显现出来。例如,Wu等人[37]介绍了ModelNet 3D shape database,他们提出了一种基于体素表示的深度信念网络结构的三维形状分类器。
虽然直观地说,直接从三维模型构建三维形状分类器似乎是合乎逻辑的,但在本文中,我们给出了一个看似违反直觉的结果:通过从这些形状的二维图像渲染中构建三维形状分类器,我们实际上可以显著优于直接基于三维表示构建的分类器。特别是,卷积神经网络(CNN)训练在一组固定的3D形状的渲染视图(views)上,并且在测试时仅提供一个视图(single view),与训练在3D表示上的最佳模型[37]相比,类别识别准确率显著提高了8%(77% 85%)。随着在测试时提供更多视图,它的性能进一步提高。
这一结果的一个原因是二维表示与三维表示的相对效率。特别是,虽然全分辨率三维表示包含有关对象的所有信息,但为了在使用可用样本并在合理时间内进行训练的深度网络中使用基于体素的表示,似乎需要显著降低分辨率。例如,三维形状网使用形状的粗略表示,即30×30×30的二元体素网格。相比之下,具有相同输入大小的3D模型的单个投影对应于164×164像素的图像,如果使用多个投影,则该投影会稍微小一些。实际上,在增加显式深度信息量(3D模型)和提高空间分辨率(投影2D模型)之间存在着内在的权衡。

图1。用于3D形状识别的多视图CNN(使用第一个摄像机设置图示)。在测试时,从12个不同的视图渲染一个3D形状,并通过 cnn1 来提取基于视图的特征。然后在视图之间进行合并,并通过 cnn2 获得一个紧凑的形状描述符。
使用2D表示的另一个优点是,我们可以利用(i)图像描述符(image descriptors)的优势[22,26]和(ii)海量图像数据库(如ImageNet[9])来预先训练我们的CNN架构。由于图像是普遍存在的,并且大的标记数据集是丰富的,我们可以学习大量关于二维图像分类的一般特征,然后对三维模型投影的细节进行微调。虽然有可能有一天会有尽可能多的三维训练数据,但就目前而言,这是我们的表现的一个显著优势。
尽管对视图进行独立分类的简单策略非常有效(3.2),我们提出了新的想法,如何“编译”一个对象的多个二维视图中的信息到一个紧凑的对象描述符使用一个新的架构称为多视图CNN(图1和3.3)。与对象的基于视图的描述符的完整集合相比,该描述符至少在分类方面具有信息性(检索方面的信息性略强)。此外,它有助于使用类似的三维对象或简单的手绘草图进行有效检索,而无需借助基于图像描述符成对比较的较慢方法。本文介绍了三维对象分类、三维对象检索和草图三维对象检索方面的最新研究成果(4)。
我们的多视图CNN与“抖动(jittering)”有关,即在训练期间添加数据的转换副本,以学习对旋转或平移等转换的不变性。在三维识别的背景下,视图可以看作是抖动的副本。多视图CNN学习组合视图而不是平均视图,因此可以使用对象的更多信息视图进行预测,而忽略其他视图。我们的实验表明,这提高了性能(4.1)还允许我们通过将网络的梯度反向传播到视图中来可视化对象的信息视图(图3)。即使在传统的图像分类任务中,多视图CNN也可以更好地替代抖动。例如,在草图识别基准[11]上,使用抖动副本训练的多视图CNN比使用相同抖动副本训练的标准CNN表现更好(4.2)。
预先训练的CNN模型、数据和复制论文结果的完整源代码:http://vis-www.cs.umass.edu/mvcnn。
2. Related Work
我们的方法与先前的三维物体形状描述和基于图像的cnn相关。接下来我们讨论这些领域的代表性工作。
Shape descriptors. A large corpus of shape descriptors has been developed for drawing inferences about 3D objects in both the computer vision and graphics literature. Shape descriptors can be classified into two broad categories: 3D shape descriptors that directly work on the native 3D representations of objects, such as polygon meshes, voxel-based discretizations, point clouds, or implicit surfaces, and viewbased descriptors that describe the shape of a 3D object by “how it looks” in a collection of 2D projections.
形状描述符。 为了在计算机视觉和图形学文献中对三维物体进行推理,我们开发了一个庞大的形状描述符语料库。形状描述符可以分为两大类:直接处理对象的本地三维表示的三维形状描述符,如多边形网格、基于体素的离散化、点云或隐式曲面,以及基于视图的描述符,通过二维投影集合中的“外观”来描述三维对象的形状。
With the exception of the recent work of Wu et al. [37] which learns shape descriptors from the voxel-based representation of an object through 3D convolutional nets, previous 3D shape descriptors were largely “hand-designed” according to a particular geometric property of the shape surface or volume. For example, shapes can be represented with histograms or bag-of-features models constructed out of surface normals and curvatures [15], distances, angles, triangle areas or tetrahedra volumes gathered at sampled surface points [25], properties of spherical functions defined in volumetric grids [16], local shape diameters measured at densely sampled surface points [4], heat kernel signatures on polygon meshes [2, 19], or extensions of the SIFT and SURF feature descriptors to 3D voxel grids [17]. Developing classifiers and other supervised machine learning algorithms on top of such 3D shape descriptors poses a number of challenges. First, the size of organized databases with annotated 3D models is rather limited compared to image datasets, e.g., ModelNet contains about 150K shapes (its 40 category benchmark contains about 4K shapes). In contrast, the ImageNet database [9] already includes tens of millions of annotated images. Second, 3D shape descriptors tend to be very high-dimensional, making classifiers prone to overfitting due to the so-called ‘curse of dimensionality’.
除了Wu等人最近的工作。[37]通过三维卷积网络从基于体素的物体表示中学习形状描述符,以前的三维形状描述符主要是根据形状表面或体积的特定几何特性“手工设计”的。例如,形状可以用柱状图或特征袋来表示,这些特征模型是由曲面法线和曲率[15]、距离、角度、三角形区域或在采样曲面点处收集的四面体体积[25]、在体积网格[16]中定义的球函数的特性构成的,在密集采样表面点处测量的局部形状直径[4],多边形网格上的热核特征[2,19],或将SIFT和SURF特征描述符扩展到三维体素网格[17]。在这些三维形状描述符的基础上开发分类器和其他有监督的机器学习算法带来了许多挑战。首先,与图像数据集相比,带注释三维模型的有组织数据库的大小相当有限,例如,ModelNet包含约150K个形状(其40个类别基准包含约4K个形状)。相比之下,ImageNet数据库[9]已经包含了数千万个带注释的图像。其次,三维形状描述符往往是非常高维的,这使得分类器由于“维数灾难”而过拟合。
On the other hand view-based descriptors have a number of desirable properties: they are relatively low-dimensional, efficient to evaluate, and robust to 3D shape representation artifacts, such as holes, imperfect polygon mesh tesselations, noisy surfaces. The rendered shape views can also be directly compared with other 2D images, silhouettes or even hand-drawn sketches. An early example of a view-based approach is the work by Murase and Nayar [24] that recognizes objects by matching their appearance in parametric eigenspaces formed by large sets of 2D renderings of 3D models under varying poses and illuminations. Another example, which is particularly popular in computer graphics setups, is the LightField descriptor [5] that extracts a set of geometric and Fourier descriptors from object silhouettes rendered from several different viewpoints. Alternatively, the silhouette of an object can be decomposed into parts and then represented by a directed acyclic graph (shock graph) [23]. Cyr and Kimia [8] defined similarity metrics based on curve matching and grouped similar views, called aspect graphs of 3D models [18]. Eitz et al. [12] compared human sketches with line drawings of 3D models produced from several different views based on local Gabor filters, while Schneider et al. [30] proposed using Fisher vectors [26] on SIFT features [22] for representing human sketches of shapes. These descriptors are largely “hand-engineered” and some do not generalize well across different domains.
另一方面,基于视图的描述子具有许多令人满意的特性:它们具有相对低的维度、高效的评估和对三维形状表示伪影(如孔洞、不完善的多边形网格镶嵌、有噪声的曲面)的鲁棒性。渲染的形状视图也可以直接与其他二维图像、轮廓甚至手绘草图进行比较。基于视图的方法的一个早期例子是Murase和Nayar的工作[24],他们通过匹配对象在参数特征空间中的外观来识别对象,参数特征空间是由在不同姿势和照明下的大量3D模型的2D渲染形成的。另一个在计算机图形学设置中特别流行的例子是LightField描述符[5],它从从从几个不同的视点渲染的对象轮廓中提取一组几何和傅里叶描述符。或者,可以将对象的轮廓分解成部分,然后用有向无环图(shock图)表示。Cyr和Kimia[8]定义了基于曲线匹配和分组相似视图的相似性度量,称为3D模型的方面图[18]。Eitz等人。[12] 将人体草图与基于局部Gabor滤波器的不同视图生成的三维模型线图进行比较,Schneider等。[30]建议在SIFT特征[22]上使用Fisher向量[26]来表示形状的人类草图。这些描述符基本上是“手工设计”的,有些描述符在不同的领域没有很好的通用性。
Convolutional neural networks. Our work is also related to recent advances in image recognition using CNNs [20]. In particular CNNs trained on the large datasets such as ImageNet have been shown to learn general purpose image descriptors for a number of vision tasks such as object detection, scene recognition, texture recognition and finegrained classification [10, 13, 28, 7]. We show that these deep architectures can be adapted to specific domains including shaded illustrations of 3D objects, line drawings, and human sketches to produce descriptors that have superiorperformancecomparedtootherview-basedor3Dshape descriptors in a variety of setups. Furthermore, they are compact and efficient to compute. There has been existing work on recognizing 3D objects with CNNs [21] using two concatenated views (binocular images) as input. Our network instead learns a shape representation that aggregates information from any number of input views without any specific ordering, and always outputs a compact shape descriptor of the same size. Furthermore, we leverage both image and shape datasets to train our network.
卷积神经网络。 我们的工作还与使用CNNs的图像识别的最新进展有关[20]。特别是,在ImageNet等大型数据集上训练的cnn已经被证明能够学习用于许多视觉任务的通用图像描述符,例如对象检测、场景识别、纹理识别和细粒度分类[10、13、28、7]。我们表明,这些深层架构可以适应特定的领域,包括三维对象的阴影插图、线条图和人体草图,以生成在各种设置中与基于视图的或三维形状的描述符相比具有更好性能的描述符。此外,它们是紧凑和有效的计算。已有的工作是使用CNNs[21]以两个连接视图(双目图像)作为输入来识别3D对象。相反,我们的网络学习一个形状表示,它从任意数量的输入视图聚合信息,而无需任何特定的顺序,并且总是输出相同大小的紧凑形状描述符。此外,我们利用图像和形状数据集来训练我们的网络。
Although there is significant work on 3D and 2D shape descriptors, and estimating informative views of the objects (or, aspect graphs), there is relatively little work on learning to combine the view-based descriptors for 3D shape recognition. Most methods resort to simple strategies such as performing exhaustive pairwise comparisons of descriptors extracted from different views of each shape, or concatenating descriptors from ordered, consistent views. In contrast our multi-view CNN architecture learns to recognize 3D shapes from views of the shapes using image-based CNNs but in the context of other views via a view-pooling layer. As a result, information from multiple views is effectively accumulated into a single, compact shape descriptor.
尽管在三维和二维形状描述符以及估计对象(或方面图)的信息视图方面有大量工作,但是在学习将基于视图的描述符组合用于三维形状识别方面的工作相对较少。大多数方法都使用简单的策略,例如对从每个形状的不同视图中提取的描述符执行穷举的成对比较,或者将有序一致视图中的描述符连接起来。相比之下,我们的多视图CNN体系结构使用基于图像的CNN从形状视图中学习识别3D形状,但是在其他视图的上下文中通过视图池层。最后将来自多个视图的信息有效地累积到一个紧凑的形状描述符中。
3. Method
As discussed above, our focus in this paper is on developing view-based descriptors for 3D shapes that are trainable, produce informative representations for recognition and retrieval tasks, and are efficient to compute.
如上所述,本文的重点是为可训练的三维形状开发基于视图的描述符,为识别和检索任务生成信息表示,并有效地进行计算。
Our view-based representations start from multiple views of a 3D shape, generated by a rendering engine. A simple way to use multiple views is to generate a 2D image descriptor per each view, and then use the individual descriptors directly for recognition tasks based on some voting or alignment scheme. For example, a na¨ ıve approach would be to average the individual descriptors, treating all the views as equally important. Alternatively, if the views are rendered in a reproducible order, one could also concatenate the 2D descriptors of all the views. Unfortunately, aligning a 3D shape to a canonical orientation is hard and sometimes ill-defined. In contrast to the above simple approaches, an aggregated representation combining features from multiple views is more desirable since it yields a single, compact descriptor representing the 3D shape.
我们基于视图的表示是从由渲染引擎生成的三维形状的多个视图开始的。使用多个视图的一种简单方法是,为每个视图生成一个二维图像描述符,然后根据某种投票或对齐方案,直接使用各个描述符进行识别任务。例如,一种简单的方法是平均每个描述符,将所有视图都视为同等重要。或者,如果视图以可复制的顺序呈现,则还可以连接所有视图的2D描述符。不幸的是,将三维形状与规范方向对齐很困难,有时定义不清。与上述简单方法相比,组合来自多个视图的特征的聚合表示更为可取,因为它生成表示3D形状的单个紧凑描述符。
Our approach is to learn to combine information from multiple views using a unified CNN architecture that includes a view-pooling layer (Fig. 1). All the parameters of our CNN architecture are learned discriminatively to produce a single compact descriptor for the 3D shape. Compared to exhaustive pairwise comparisons between singleview representations of 3D shapes, our resulting descriptors can be directly used to compare 3D shapes leading to significantly higher computational efficiency.
我们的方法是学习使用包括视图池层的统一CNN架构来组合来自多个视图的信息(图1)。我们的CNN结构的所有参数都是通过分别学习来产生一个三维形状的紧凑描述符。与三维形状的单视图表示之间的穷举成对比较相比,我们得到的描述符可以直接用于比较三维形状,从而显著提高计算效率。
3.1. Input: A Multi-view Representation
3D models in online databases are typically stored as polygon meshes, which are collections of points connected with edges forming faces. To generate rendered views of polygon meshes, we use the Phong reflection model [27]. The mesh polygons are rendered under a perspective projection and the pixel color is determined by interpolating the reflected intensity of the polygon vertices. Shapes are uniformly scaled to fit into the viewing volume.
在线数据库中的三维模型通常存储为多边形网格,多边形网格是与形成面的边连接的点的集合。要生成多边形网格的渲染视图,我们使用Phong反射模型[27]。网格多边形在透视投影下渲染,像素颜色通过插值多边形顶点的反射强度来确定。形状被均匀地缩放以适应观察体积。
To create a multi-view shape representation, we need to setup viewpoints (virtual cameras) for rendering each mesh. We experimented with two camera setups. For the 1st camera setup, we assume that the input shapes are upright oriented along a consistent axis (e.g., z-axis). Most models in modern online repositories, such as the 3D Warehouse, satisfy this requirement, and some previous recognition methods also follow the same assumption [37]. In this case, we create 12 rendered views by placing 12 virtual cameras around the mesh every 30 degrees (see Fig. 1). The cameras are elevated 30 degrees from the ground plane, pointing towards the centroid of the mesh. The centroid is calculated as the weighted average of the mesh face centers, where the weights are the face areas. For the 2nd camera setup, we do not make use of the assumption about consistent upright orientation of shapes. In this case, we render from several more viewpoints since we do not know beforehand which ones yield good representative views of the object. The renderings are generated by placing 20 virtual cameras at the 20 vertices of an icosahedron enclosing the shape. All cameras point towards the centroid of the mesh. Then we generate 4 rendered views from each camera, using 0, 90, 180, 270 degrees rotation along the axis passing through the camera and the object centroid, yielding total 80 views.
要创建多视图形状表示,我们需要设置用于渲染每个网格的视点(虚拟摄影机)。我们试验了两种摄像装置。对于第一个相机设置,我们假设输入形状沿一致轴(例如,z轴)垂直定向。现代在线存储库中的大多数模型,比如3D仓库,都满足了这一要求,而之前的一些识别方法也遵循同样的假设[37]。在这种情况下,我们通过每30度在网格周围放置12个虚拟摄像机来创建12个渲染视图(见图1)。摄像机从地平面上升高30度,指向网格的质心。质心计算为网格面中心的加权平均值,其中权重为面区域。对于第二个相机的设置,我们不使用形状一致垂直方向的假设。在这种情况下,我们从多个角度进行渲染,因为我们事先不知道哪些角度可以生成对象的良好代表性视图。渲染是通过将20个虚拟摄影机放置在包围形状的二十面体的20个顶点上生成的。所有摄影机都指向网格的质心。然后,我们从每个相机生成4个渲染视图,使用0°、90°、180°、270°沿穿过相机和对象质心的轴旋转,生成总共80个视图。
We note that using different shading coefficients or illumination models did not affect our output descriptors due to the invariance of the learned filters to illumination changes, as also observed in image-based CNNs [20, 10]. Adding more or different viewpoints is trivial, however, we found that the above camera setups were already enough to achieve high performance. Finally, rendering each mesh from all the viewpoints takes no more than ten milliseconds on modern graphics hardware.
我们注意到,使用不同的阴影系数或照明模型并不影响我们的输出描述符,因为学习的滤波器对照明变化的不变性,这在基于图像的CNNs中也观察到了[20,10]。添加更多或不同的视点是很简单的,但是,我们发现上面的相机设置已经足以实现高性能。最后,在现代图形硬件上,从所有视点渲染每个网格所需的时间不超过10毫秒。
3.2. Recognition with Multi-view Representations
我们的多视图表示包含丰富的三维形状信息,可以应用于各种类型的任务。在第一个设置中,我们直接使用现有的二维图像特征,并为每个视图生成一个描述符。这是利用多视图表示的最直接的方法。然而,它会导致每个3D形状有多个2D图像描述符,每个视图一个,这些描述符需要以某种方式集成以用于识别任务。
Image descriptors. We consider two types of image descriptors for each 2D view: a state-of-the-art “hand-crafted” image descriptor based on Fisher vectors [29] with multiscale SIFT, as well as CNN activation features [10].
图像描述符。我们为每个二维视图考虑两种类型的图像描述符:基于Fisher向量的最新“手工制作”图像描述符[29]和多尺度SIFT,以及CNN激活特征[10]。
The Fisher vector image descriptor is implemented using VLFeat [36]. For each image multi-scale SIFT descriptors are extracted densely. These are then projected to 80 dimensions with PCA, followed by Fisher vector pooling with a Gaussian mixture model with 64 components, square-root and ℓ2 normalization.
Fisher矢量图像描述符是使用VLFeat[36]实现的。对于每个图像,多尺度SIFT描述子被密集地提取出来。然后用主成分分析法将其投影到80维,然后用64个分量的高斯混合模型进行Fisher向量池,平方根和l2归一化。
For our CNN features we use the VGG-M network from [3] which consists of mainly five convolutional layers conv1,…,5followed by three fully connected layers fc6,…,8 and a softmax classification layer. The penultimate layer fc7(after ReLU non-linearity, 4096-dimensional) is used as image descriptor. The network is pre-trained on ImageNet images from 1k categories, and then fine-tuned on all 2D views of the 3D shapes in training set. As we show in our experiments, fine-tuning improves performance significantly. Both Fisher vectors and CNN features yield very good performance in classification and retrieval compared with popular 3D shape descriptors (e.g., SPH [16], LFD [5]) as well as 3D ShapeNets [37].
我们的CNN架构使用来自[3]的VGG-M网络,它主要由五个卷积层conv1,…,5,然后是三个完全连接层fc6,…,8和一个softmax分类层组成。倒数第二层fc7(在ReLU非线性之后,4096维)用作图像描述符。该网络对来自1k个类别的ImageNet图像进行预训练,然后对训练集中3D形状的所有2D视图进行微调。 正如我们在实验中所显示的,微调可以显著提高性能。Fisher向量和CNN特征在分类和检索方面都比流行的3D形状描述符(如SPH[16]、LFD[5])和3D形状网[37]有很好的性能。
Classification. We train one-vs-rest linear SVMs (each view is treated as a separate training sample) to classify shapes using their image features. At test time, we simply sum up the SVM decision values over all 12 views and return the class with the highest sum. Alternative approaches, e.g., averaging image descriptors, lead to worse accuracy.
分类。我们训练一对静止线性支持向量机(每个视图都被视为一个单独的训练样本)来利用形状的图像特征进行分类。在测试时,我们只需对所有12个视图上的SVM决策值进行求和,然后返回求和最高的类。其他方法,例如平均图像描述符,会导致更差的准确性。
Retrieval. A distance or similarity measure is required for retrieval tasks. For shape x with nx image descriptors and shape y with ny image descriptors, the distance between them is defined in Eq. 1. Note that the distance between two 2D images is defined as the ℓ2 distance between their feature vectors, i.e. ||xi− yj||2.
检索。检索任务需要距离或相似性度量。对于具有
图像描述符的
形状和具有
图像描述符的
形状,它们之间的距离在公式1中定义。注意,两幅二维图像之间的距离定义为其特征向量之间的距离,即
。
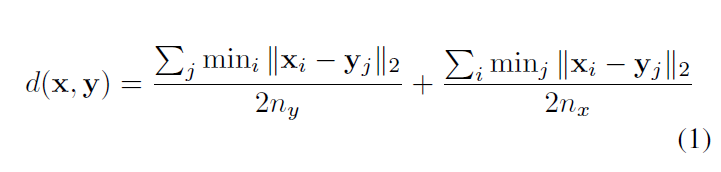
To interpret this definition, we can first define the distance between a 2D image and a 3D shape y as . Then given all distances between x’s 2D projections and y, the distance between these two shapes is computed by simple averaging. In Eq. 1, this idea is applied in both directions to ensure symmetry.
为了解释这个定义,我们首先可以将2D图像 与3D形状y之间的距离定义为 。然后,给定 x 的2D投影和 y 之间的所有 距离,可以通过简单的平均来计算这两个形状之间的距离。在等式中在图1中,此思想在两个方向上都应用以确保对称。
3.3. Multi-view CNN: Learning to Aggregate Views
Although having multiple separate descriptors for each 3D shape can be successful for classification and retrieval compared to existing 3D descriptors, it can be inconvenient and inefficient in many cases. For example, in Eq. 1, we need to compute all nx×ny pairwise distances between images in order to compute distance between two 3D shapes. Simply averaging or concatenating the image descriptors leads to inferior performance. In this section, we focus on the problem of learning to aggregate multiple views in order to synthesize the information from all views into a single, compact 3D shape descriptor.
尽管与现有3D描述符相比,每个3D形状具有多个单独的描述符可以成功进行分类和检索,但在许多情况下可能不方便且效率低下。例如,在等式1中。如图1所示,我们需要计算图像之间的所有 成对距离,以计算两个3D形状之间的距离。简单地对图像描述符进行平均或串联会导致性能下降。在本节中,我们关注于学习如何聚合多个视图以将来自所有视图的信息综合到一个紧凑的3D形状描述符中的问题。

表1. ModelNet40数据集上的分类和检索结果。最上方是使用最新3D形状描述符的结果。我们的基于视图的描述符包括Fisher向量(FV),即使在测试时只有一个视图可用(#Views = 1)时,它们的性能也大大优于这些描述符。当在测试时有多个视图(#Views = 12或80)可用时,基于视图的方法的性能将大大提高。多视图CNN(MVCNN)架构优于基于视图的方法,尤其是在检索方面。
We design the multi-view CNN (MVCNN) on top of image-based CNNs (Fig. 1). Each image in a 3D shape’s multi-view representation is passed through the first part of the network (CNN1) separately, aggregated at a viewpooling layer, and then sent through the remaining part of the network (CNN2). All branches in the first part of the network share the same parameters in CNN1. We use element-wise maximum operation across the views in the view-pooling layer. An alternative is element-wise mean operation, but it is not as effective in our experiments. The view-pooling layer can be placed anywhere in the network. We show in our experiments that it should be placed close to the last convolutional layer (conv5) for optimal classification and retrieval performance. View-pooling layers are closely related to max-pooling layers and maxout layers [14], with the only difference being the dimension that their pooling operations are carried out on. The MVCNN is a directed acyclic graphs and can be trained or fine-tuned using stochastic gradient descent with back-propagation.
我们在基于图像的CNN(图1)的基础上设计了多视图CNN(MVCNN)。三维形状的多视图表示中的每个图像分别通过网络的第一部分(CNN1),在视图池层聚合,然后通过网络的其余部分(CNN2)发送。网络第一部分的所有分支在CNN1中共享相同的参数。我们对视图池层中的视图使用元素最大化操作。另一种方法是基于元素的平均运算,但在我们的实验中并没有那么有效。视图池层可以放置在网络中的任何位置。我们的实验表明,为了获得最佳的分类和检索性能,应该将它放置在靠近最后一个卷积层(conv5)的位置。视图池层与max pooling层和max out层密切相关[14],唯一的区别是它们的池操作是在哪个维度上执行的。MVCNN是一个有向无环图,它可以用带反向传播的随机梯度下降来训练或微调。
Using fc7(after ReLU non-linearity) in an MVCNN as an aggregated shape descriptor, we achieve higher performance than using separate image descriptors from an image-based CNN directly, especially in retrieval (62.8% → 70.1%). Perhaps more importantly, the aggregated descriptor is readily available for a variety of tasks, e.g., shape classification and retrieval, and offers significant speed-ups against multiple image descriptors. An MVCNN can also be used as a general framework to integrate perturbed image samples (also known as data jittering). We illustrate this capability of MVCNNs in the context of sketch recognition in Sect. 4.2.
在MVCNN中使用fc7(经过ReLU非线性)作为聚合形状描述符,比直接从基于图像的CNN中使用单独的图像描述符获得了更高的性能,尤其是在检索方面(62.8% 70.1%)。也许更重要的是,聚合的描述符可以很容易地用于各种任务,例如形状分类和检索,并且对多个图像描述符提供了显著的速度提升。MVCNN也可以用作集成受干扰图像样本(也称为数据抖动)的通用框架。我们在4.2中的草图识别环境中说明了MVCNN的这种能力。
Low-rank Mahalanobis metric. Our MVCNN is finetuned for classification, and thus retrieval performance is not directly optimized. Although we could train it with a different objective function suitable for retrieval, we found that a simpler approach can readily yield a significant retrieval performance boost (see row 12 in Tab. 1). We learn a Mahalanobis metric W that directly projects MVCNN descriptors to , such that the distances in the projected space are small between shapes of the same category, and large otherwise. We use the large-margin metric learning algorithm and implementation from [32], with p < d to make the final descriptor compact (p=128 in our experiments). The fact that we can readily use metric learning over the output shape descriptor demonstrates another advantage of using MVCNNs.
低等级Mahalanobis指标。我们的MVCNN已针对分类进行了微调,因此无法直接优化检索性能。尽管我们可以使用适合检索的不同目标函数来训练它,但我们发现,更简单的方法可以轻松地显着提高检索性能(请参见表1中的第12行)。我们学习了一个Mahalanobis度量W,该度量直接将MVCNN描述符 投影到 ,使得在相同类别的形状之间,投影空间中的 距离较小,否则较大。我们使用[32]中的大幅度度量学习算法和实现,其中p=128。
4. Experiments

We evaluate our shape descriptors on the Princeton ModelNet dataset [1]. ModelNet currently contains 127,915 3D CAD models from 662 categories.1. A 40-class wellannotated subset containing 12,311 shapes from 40 common categories, ModelNet40, is provided on the ModelNet website. For our experiments, we use the same training and test split of ModelNet40 as in [37]2.
我们在Princeton ModelNet数据集上评估形状描述符[1]。 ModelNet当前包含来自662个类别的127,915个3D CAD模型1。 ModelNet网站上提供了一个40类带注释的子集,其中包含来自40个常见类别的12,311个形状。对于我们的实验,我们使用与[37] 2中相同的ModelNet40训练和测试拆分。
Our shape descriptors are compared against the 3D ShapeNets by Wu et al. [37], the Spherical Harmonics descriptor (SPH) by Kazhdan et al. [16], the LightField descriptor (LFD) by Chen et al. [5], and Fisher vectors extracted on the same rendered views of the shapes used as input to our networks.
我们的形状描述符与Wu等人的3D ShapeNets进行了比较。 [37],由Kazhdan等人撰写的球形谐波描述符(SPH)。 [16],Chen等人的LightField描述符(LFD)。 [5],并在相同形状的渲染视图中提取的Fisher向量用作我们网络的输入。
Results on shape classification and retrieval are summarized in Tab. 1. Precision-recall curves are provided in Fig. 2. Remarkably the Fisher vector baseline with just a single view achieves a classification accuracy of 78.8% outperforming the state-of-the-art learned 3D descriptors (77.3% [37]). When all 12 views of the shape are available at test time (based on our first camera setup), we can also average the predictions over these views. Averaging increases the performance of Fisher vectors to 84.8%. The performance of Fisher vectors further supports our claim that 3D objects can be effectively represented using viewbased 2D representations. The trends in performance for shape retrieval are similar.
表中汇总了形状分类和检索的结果。 1.图2中提供了精确调用曲线。值得注意的是,仅具有单个视图的Fisher向量基线的分类精度就达到了78.8%,优于最新学习的3D描述符(77.3%[37])。当形状的所有12个视图在测试时都可用时(基于我们的第一个摄像头设置),我们还可以对这些视图的预测取平均值。平均将Fisher向量的性能提高到84.8%。 Fisher向量的性能进一步支持了我们的主张,即可以使用基于视图的2D表示有效地表示3D对象。形状检索的性能趋势相似。
Using our CNN baseline trained on ImageNet in turn outperforms Fisher vectors by a significant margin. FinetuningtheCNNontherenderedviewsofthetrainingshapes of ModelNet40 further improves the performance. By using all 12 views of the shape, its classification accuracy reaches 88.6%, and mean average precision (mAP) for retrieval is also improved to 62.8%.
依次使用我们在ImageNet上训练的CNN基线,其性能大大优于Fisher向量。在ModelNet40的渲染视图软约束形状上微调CNN可以进一步提高性能。通过使用形状的所有12个视图,其分类精度达到88.6%,并且检索的平均平均精度(mAP)也提高到62.8%。
Our MVCNN outperforms all state-of-the-art descriptors as well as the Fisher vector and CNN baselines. With finetuning on the ModelNet40 training set, our model achieves 89.9% classification accuracy, and 70.1% mAP on retrieval using the first camera setup. If we do not make use of the assumption about consistent upright orientation of shapes (second camera setup), the performance remains still intact, achieving 90.1% classification accuracy and 70.4% retrieval mAP. MVCNN constitutes an absolute gain of 12.8% in classification accuracy compared to the state-ofthe-art learned 3D shape descriptor [37] (77.3% → 90.1%). Similarly, retrieval mAP is improved by 21.2% (49.2% → 70.4%). Finally, learning a low-rank Mahalanobis metric improves retrieval mAP further while classification accuracy remains almost unchanged, and the resulting shape descriptors become more compact (d = 4096, p = 128).
我们的MVCNN胜过所有最先进的描述符以及Fisher向量和CNN基线。通过对ModelNet40训练集进行微调,我们的模型在使用第一个摄像头设置进行检索时可达到89.9%的分类准确度和70.1%的mAP。如果我们不使用关于形状一致的垂直方向(第二个摄像头设置)的假设,则性能仍然保持不变,可以实现90.1%的分类精度和70.4%的检索mAP。与最新学习的3D形状描述符[37](77.3%→90.1%)相比,MVCNN的分类精度绝对提高了12.8%。同样,检索mAP也提高了21.2%(49.2%→70.4%)。最后,学习低等级的Mahalanobis度量可进一步改善检索mAP,而分类精度几乎保持不变,并且所得到的形状描述符变得更加紧凑(d = 4096,p = 128)。
We considered different locations to place the viewpooling layer in the MVCNN. Performance is not very sensitive among the later few layers (conv4∼fc7); however any location prior to conv4decreases classification accuracies significantly. We find conv5offers slightly better accuracies (∼1%), and thus use it for all our experiments.
我们考虑了将视图池层放置在MVCNN中的不同位置。在随后的几层(conv4〜fc7)中,性能不是很敏感。但是,在conv4之前的任何位置都会大大降低分类的准确性。我们发现conv5提供的精度更高(〜1%),因此可用于我们的所有实验。
Saliency map among views. For each 3D shape S, our multi-view representation consists of a set of K 2D views . We would like to rank pixels in the 2D views w.r.t. their influence on the output score Fc of the network (e.g. taken from fc8 layer) for its ground truth class c. Following [33], saliency maps can be defined as the derivatives of Fc w.r.t. the 2D views of the shape:
视图之间的显着性地图。对于每个3D形状S,我们的多视图表示由一组K个2D视图
。我们想在2D视图中对像素进行排名它们对于其基本的真实分类c对网络输出分数Fc的影响(例如,从fc8层获取)。在[33]中,显著性图可以定义为 Fc 对于形状的二维视图的导数:

对于MVCNN,公式2中的w可以在所有网络参数固定的情况下使用反向传播计算,然后可以重新排列以形成各个视图的显著性映射。显著图的例子如图3所示。

图3。最显著的前三个视图用蓝色突出显示,每个视图的梯度能量的相对大小显示在顶部。显著性映射是通过视图池层将类得分的梯度反向传播到图像上来计算的。注意梳妆台和桌子的把手是最有区别的特征。(增强图形的可见性。)
4.2. Sketch Recognition: Jittering Revisited
鉴于我们的聚合描述符在3D对象的多个视图上取得了成功,因此逻辑上提出以下问题:对2D图像的多个视图进行聚合是否也可以提高性能。在这里,我们通过在草图识别的上下文中探究数据抖动与数据抖动的联系来证明确实如此。
Data jittering, or data augmentation, is a method to generate extra samples from a given image. It is the process of perturbing the image by transformations that change its appearance while leaving the high-level information (class label, attributes, etc.) intact. Jittering can be applied at training time to augment training samples and to reduce overfitting, or at test time to provide more robust predictions. In particular, severalauthors[20,3,35] have used data jittering to improve the performance of deep representations on 2D image classification tasks. In these applications, jittering at training time usually includes random image translations (implemented as random crops), horizontal reflections, and color perturbations. At test time jittering usually only includes a few crops (e.g., four at the corners, one at the center and their horizontal reflections). We now examine whether we can get more benefit out of jittered views of an image by using the same feature aggregation scheme we developed for recognizing 3D shapes.
数据抖动或数据增强是一种从给定图像生成额外样本的方法。它是通过变换来扰动图像的过程,这些变换会更改其外观,同时保留完整的高级信息(类标签,属性等)。抖动可以在训练时应用,以增加训练样本并减少过度拟合,也可以在测试时应用,以提供更可靠的预测。特别是,几位作者[20,3,35]已经使用数据抖动来改善2D图像分类任务中深度表示的性能。在这些应用中,训练时的抖动通常包括随机图像平移(实现为随机裁剪),水平反射和颜色扰动。在测试时,抖动通常仅包括少数几种作物(例如,在角部有四个作物,在中心处有一个作物,且水平反射)。现在,我们检查通过使用为识别3D形状而开发的相同特征聚合方案,是否可以从图像的抖动视图中获得更多好处。
The human sketch dataset [11] contains 20,000 handdrawn sketches of 250 object categories such as airplanes, apples, bridges, etc. The accuracy of humans in recognizing these hand-drawings is only 73% because of the low quality of some sketches. Schneider and Tuytelaars [30] cleaned up the dataset by removing instances and categories that humans find hard to recognize. This cleaned dataset (SketchClean) contains 160 categories, on which humans can achieve 93% recognition accuracy. Using SIFT Fisher vectors with spatial pyramid pooling and linear SVMs, Schneider and Tuytelaars achieved 68.9% recognition accuracy on the original dataset and 79.0% on the SketchClean dataset. We split the SketchClean dataset randomly into training, validation and test set3, and report classification accuracy on the test set in Tab2.
人体素描数据集[11]包含2万幅手绘素描,包括飞机、苹果、桥梁等250个物体类别。由于某些素描质量较低,人类识别这些手绘的准确率仅为73%。Schneider和Tuytelaars[30]通过删除人类难以识别的实例和类别来清理数据集。这个清理过的数据集(SketchClean)包含160个类别,在这些类别上,人类可以达到93%的识别准确率。Schneider和Tuytelaars使用SIFT-Fisher矢量,结合空间金字塔池和线性支持向量机,在原始数据集和SketchClean数据集上分别达到68.9%和79.0%的识别精度。我们将SketchClean数据集随机分成训练集、验证集和测试集3,并在表2中的测试集上报告分类精度。
With an off-the-shelf CNN (VGG-M from [3]), we are able to get 77.3% classification accuracy without any network fine-tuning. With fine-tuning on the training set, the accuracy can be further improved to 84.0%, significantly surpassing the Fisher vector approach. These numbers are 3The dataset does not come with a standard training/val/test split. achieved by using the penultimate layer (fc7) in the network as image descriptors and linear SVMs.
有了现成的CNN(VGG-M from[3]),我们可以在没有任何网络微调的情况下获得77.3%的分类精度。通过对训练集进行微调,精度进一步提高到84.0%,明显优于Fisher向量方法。这些数字是3数据集没有标准的训练/val/测试分割。利用网络倒数第二层(fc7)作为图像描述符和线性支持向量机实现。
Although it is impractical to get multiple views from 2D images, we can use jittering to mimic the effect of views. For each hand-drawn sketch, we do in-plane rotation with three angles: −45°, 0°, 45°, and also horizontal reflections (hence 6 samples per image). We apply the two CNN variants (regular CNN and MVCNN) discussed earlier for aggregating multiple views of 3D shapes, and get 85.5% (CNN w/o view-pooling) and 86.3% (MVCNN w/ viewpooling on fc7) classification accuracy respectively. The latter also has the advantage of a single, more compact descriptor for each hand-drawn sketch.
虽然从二维图像中获取多个视图是不切实际的,但是我们可以使用抖动来模拟视图的效果。对于每个手绘草图,我们使用三个角度进行平面内旋转:-45°、0°、45°和水平反射(因此每个图像6个样本)。我们应用前面讨论的两种CNN变体(常规CNN和MVCNN)来聚集3D形状的多个视图,分别获得85.5%(CNN w/o视图池)和86.3%(MVCNN w/view pooling on fc7)的分类精度。后者还有一个优点,即每个手绘草图都有一个更紧凑的描述符。
With a deeper network architecture (VGG-VD, a network with 16 weight layers from [34]), we achieve 87.2% accuracy, further advancing the classification performance, and closely approaching human performance.
采用更深层次的网络结构(VGG-VD,一个来自[34]的16层权值的网络),我们达到了87.2%的准确率,进一步提高了分类性能,接近了人类的性能。
4.3. Sketch-based 3D Shape Retrieval

表2。SketchClean上的分类结果。微调后的CNN模型显著优于Fisher vectors[30]的显著优势。MVCNN比CNN训练的数据抖动要好。结果显示了两种不同的CNN结构-VGG-M(第2-5行)和VGG-VD(第6-9行)。

图4。从3D形状绘制线条的样式。
Due to the growing number of online 3D repositories, many approaches have been investigated to perform efficient 3D shape retrieval. Most online repositories (e.g. 3D Warehouse, TurboSquid, Shapeways) provide only textbased search engines or hierarchical catalogs for 3D shape retrieval. However, it is hard to convey stylistic and geometric variations using only textual descriptions, thus sketchbased shape retrieval [38, 31, 12] has been proposed as an alternative for users to retrieve shapes with an approximate sketch of the desired 3D shape in mind. Sketchbased retrieval is challenging since it involves two heterogeneous data domains (hand-drawn sketches and 3D shapes), and sketches can be highly abstract and visually different from target 3D shapes. Here we demonstrate the potential strength of MVCNNs in sketch-based shape retrieval.
随着在线三维存储库的不断增多,人们研究了许多有效的三维形状检索方法。大多数在线存储库(如3D Warehouse、TurboSquid、Shapeways)只提供基于文本的搜索引擎或用于3D形状检索的分层目录。然而,仅使用文本描述很难传达风格和几何变化,因此基于草图的形状检索[38、31、12]被提出作为用户检索形状的替代方法,用户可以在考虑所需三维形状的近似草图的情况下检索形状。基于草图的检索具有挑战性,因为它涉及两个异构数据域(手绘草图和三维形状),草图可以高度抽象,并且在视觉上与目标三维形状不同。这里我们展示了MVCNNs在基于草图的形状检索中的潜在优势。
For this experiment, we construct a dataset containing 193 sketches and 790 CAD models from 10 categories existing in both SketchClean and ModelNet40. Following [12], we produce renderings of 3D shapes with a style similar to hand-drawn sketches (see Fig. 4). This is achieved by detecting Canny edges on the depth buffer (also known as z-buffer) from 12 viewpoints. These edge maps are then passed through CNNs to obtain image descriptors. Descriptors are also extracted from 6 perturbed samples of each query sketch in the manner described in Sect. 4.2. Finally we rank 3D shapes w.r.t. “average minimum distance” (Eq. 1) to the sketch descriptors. Representative retrieval results are shown in Fig. 5.
对于这个实验,我们构建了一个包含193个草图和790个CAD模型的数据集,这些模型来自SketchClean和ModelNet40中的10个类别。在[12]之后,我们使用类似于手绘草图的样式生成三维形状的渲染(见图4)。这是通过从12个视点检测深度缓冲区(也称为z缓冲区)上的Canny边来实现的。然后,这些边缘映射通过CNNs获得图像描述符。描述符也以第节描述的方式从每个查询草图的6个扰动样本中提取(4.2)。最后,我们将三维形状的“平均最小距离”(公式1)与草图描述符进行排序。具有代表性的检索结果如图5所示。

图5。基于草图的3D形状检索示例。每个查询都会显示最匹配的内容,并以红色突出显示错误。
While the world is full of 3D shapes, as humans at least, we understand that world is mostly through 2D images. We query top 10 retrieved 3D shapes have shown that using images of shapes as inputs to modern learning architectures, we can achieve performance better than any previously published results, including those that operate on direct 3D representations of shapes.
尽管世界充满了3D形状,但我们了解到,人类认知世界主要是靠2D图像。我们查询了检索到的前10个3D形状,结果表明,使用形状图像作为现代学习体系结构的输入,我们可以比以前发布的任何结果(包括对形状的直接3D表示进行操作的结果)都更好地实现性能。
While even a näive usage of these multiple 2D projections yields impressive discrimination performance, by building descriptors that are aggregations of information from multiple views, we can achieve compactness, efficiency, and better accuracy. In addition, by relating the content of 3D shapes to 2D representations like sketches, we can retrieve these 3D shapes at high accuracy using sketches, and leverage the implicit knowledge of 3D shapes contained in their 2D views.
尽管这些多个二维投影的实际使用会产生令人印象深刻的辨别性能,但是通过构建从多个视图聚合信息的描述符,我们可以实现紧凑性、效率和更好的准确性。此外,通过将三维形状的内容与草图等二维表示相关联,我们可以使用草图以高精度检索这些三维形状,并利用其二维视图中包含的三维形状的隐式知识。
There are a number of directions to explore in future work. One is to experiment with different combinations of 2D views. Which views are most informative? How many views are necessary for a given level of accuracy? Can informative views be selected on the fly?
在今后的工作中有许多方向需要探索。一种是尝试不同的二维视图组合。哪些观点最能提供信息?对于给定的精度级别,需要多少视图?是否可以动态选择信息视图?
Another obvious question is whether our view aggregating techniques can be used for building compact and discriminative descriptors for real-world 3D objects from multiple views, or automatically from video, rather than merely for 3D polygon mesh models. Such investigations could be immediately applicable to widely studied problems such as object recognition and face recognition.
另一个明显的问题是,我们的视图聚合技术是否可以用于为来自多个视图的真实三维对象或自动从视频中构建紧凑且有区别的描述符,而不仅仅是用于三维多边形网格模型。这种研究可以立即应用于广泛研究的问题,如目标识别和人脸识别。
Acknowledgements We thank Yanjie Li for her help on rendering meshes. We thank NVIDIA for their generous donation of GPUs used in this research. Our work was partially supported by NSF (CHS-1422441).
References
[1] The Princeton ModelNet.
http://modelnet.cs.princeton.edu/. [Online; accessed March 2015]. 5
[2] A. Bronstein, M. Bronstein, M. Ovsjanikov, and L. Guibas.Shape Google: Geometric words and expressions for invariant shape retrieval. ACM Trans. Graph., 30, 2011. 2
[3] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman.Return of the devil in the details: Delving deep into convolutional nets. In Proc. BMVC, 2014. 4, 7
[4] S. Chaudhuri and V . Koltun. Data-driven suggestions for creativity support in 3D modeling. ACM Trans. Graph., 29(6),2010. 2
[5] D. Chen, X. Tian, Y . Shen, and M. Ouhyoung. On visual similarity based 3D model retrieval. Proc. Eurographics,22(3):223–232, 2003. 3, 4, 5, 6
[6] S. Chopra, R. Hadsell, and Y . LeCun. Learning a similarity metric discriminatively, with application to face verification. In Proc. CVPR, 2005. 8
[7] M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. V edaldi. Describing textures in the wild. In Proc. CVPR, 2014. 3
[8] C. M. Cyr and B. B. Kimia. A similarity-based aspect-graph approach to 3D object recognition. 57(1), 2004. 3
[9] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In Proc. CVPR, 2009.1, 2
[10] J. Donahue, Y . Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell. DeCAF: A deep convolutional activation feature for generic visual recognition. CoRR,abs/1310.1531, 2013. 3, 4
[11] M. Eitz, J. Hays, and M. Alexa. How do humans sketch objects? ACM Trans. Graph., 31(4):44:1–44:10, 2012. 2, 7
[12] M. Eitz, R. Richter, T. Boubekeur, K. Hildebrand, and M. Alexa. Sketch-based shape retrieval. ACM Trans. Graph.,31(4), 2012. 3, 7, 8
[13] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proc. CVPR, 2014. 3
[14] I. J. Goodfellow, D. Warde-Farley, M. Mirza, A. Courville, and Y . Bengio. Maxout networks. ArXiv e-prints, Feb. 2013.5
[15] B. K. P . Horn. Extended gaussian images. Proc. of the IEEE,72(12):1671–1686, 1984. 2
[16] M. Kazhdan, T. Funkhouser, and S. Rusinkiewicz. Rotation invariant spherical harmonic representation of 3D shape descriptors. Proc. Symposium of Geometry Processing, 2003.2, 4, 5, 6
[17] J. Knopp, M. Prasad, G. Willems, R. Timofte, and L. V an Gool. Hough transform and 3D SURF for robust three dimensional classification. In Proc. ECCV, 2010. 2
[18] J. J. Koenderink and A. J. V an Doorn. The singularities of the visual mapping. Biological cybernetics, 24(1):51–59, 1976.3
[19] I. Kokkinos, M. Bronstein, R. Litman, and A. Bronstein. Intrinsic shape context descriptors for deformable shapes. In Proc. CVPR, 2012. 2
[20] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In
Proc. NIPS. 2012. 3, 4, 7
[21] Y . LeCun, F. Huang, and L. Bottou. Learning methods for generic object recognition with invariance to pose and lighting. In Proc. CVPR, 2004. 3
[22] D. G. Lowe. Object recognition from local scale-invariant features. In Proc. ICCV, 1999. 1, 3
[23] D. Macrini, A. Shokoufandeh, S. Dickinson, K. Siddiqi, and S. Zucker. View-based 3-D object recognition using shock
graphs. In Proc. ICPR, volume 3, 2002. 3
[24] H. Murase and S. K. Nayar. Visual learning and recognition of 3-D objects from appearance. 14(1), 1995. 3
[25] R. Osada, T. Funkhouser, B. Chazelle, and D. Dobkin. Shape distributions. ACM Trans. Graph., 21(4), 2002. 2
[26] F. Perronnin, J. Sánchez, and T. Mensink. Improving the Fisher kernel for large-scale image classification. In Proc. ECCV, 2010. 1, 3
[27] B. T. Phong. Illumination for computer generated pictures.
Commun. ACM, 18(6), 1975. 3
[28] A. S. Razavin, H. Azizpour, J. Sullivan, and S. Carlsson.CNN features off-the-shelf: An astounding baseline for recognition. In DeepVision workshop, 2014. 3
[29] J. Sanchez, F. Perronnin, T. Mensink, and J. V erbeek. Image classification with the Fisher vector: Theory and practice.2013. 4
[30] R. G. Schneider and T. Tuytelaars. Sketch classification and classification-driven analysis using Fisher vectors. ACM Trans. Graph., 33(6):174:1–174:9, Nov. 2014. 3, 7, 8
[31] T. Shao, W. Xu, K. Yin, J. Wang, K. Zhou, and B. Guo.Discriminative sketch-based 3D model retrieval via robust shape matching. In Computer Graphics F orum, volume 30.Wiley Online Library, 2011. 7
[32] K. Simonyan, O. M. Parkhi, A. V edaldi, and A. Zisserman.Fisher vector faces in the wild. In Proc. BMVC, 2013. 5
[33] K. Simonyan, A. V edaldi, and A. Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. CoRR, abs/1312.6034, 2013.6
[34] K. Simonyan and A. Zisserman. V ery deep convolutional networks for large-scale image recognition. CoRR,abs/1409.1556, 2014. 7
[35] C. Szegedy, W. Liu, Y . Jia, P . Sermanet, S. Reed,D. Anguelov, D. Erhan, V . V anhoucke, and A. Rabinovich.Going deeper with convolutions. CoRR, abs/1409.4842,2014. 7
[36] A. V edaldi and B. Fulkerson. VLFeat: An open and portable library of computer vision algorithms. http://www.vlfeat.org/, 2008. 4
[37] Z. Wu, S. Song, A. Khosla, F. Y u, L. Zhang, X. Tang, and J. Xiao. 3D ShapeNets: A deep representation for volumetric shape modeling. In Proc. CVPR, 2015. 1, 2, 4, 5, 6
[38] S. M. Y oon, M. Scherer, T. Schreck, and A. Kuijper. Sketch-based 3D model retrieval using diffusion tensor fields of suggestive contours. In Proc. International Conference on Multimedia, 2010. 7
