自顶向下的分析(Top-Down Parsing)
- 从分析树的顶部(根节点)向底部(叶节点)方向构造分析树。
- 可以看成是从文法开始符号
S推导出词串
w的过程。
文法:
-
E→E+E
-
E→E∗E
-
E→−E
-
E→(E)
-
E→id
推导过程:
E⇒−E⇒−(E)⇒−(E+E)⇒−(id+E)⇒−(id+id)
分析树:

- 每一步推导中,都需要做两个选择:
- 替换当前句型中的哪个非终结符
- 用该非终结符的哪个候选式进行替换
最左推导(Left-most Derivation)
在最左推导中,总是选择每个句型的最左非终结符进行替换
例如:
文法:
-
E→E+E
-
E→E∗E
-
E→−E
-
E→(E)
-
E→id
输入:
id+(id+id)
推导过程:
扫描二维码关注公众号,回复:
5487366 查看本文章

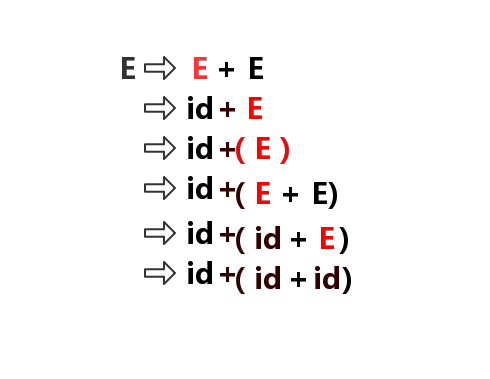
注:1. 最左推导的逆过程称为最右规约。
2. 如果
S⇒lm∗α,则称
α为当前文法的最左句型(left-sentential form)。(lm意为left most)
最右推导
在最右推导中,总是选择每个句型的最右非终结符进行替换。
例如:
文法:
-
E→E+E
-
E→E∗E
-
E→−E
-
E→(E)
-
E→id
输入:
id+(id+id)
推导过程:
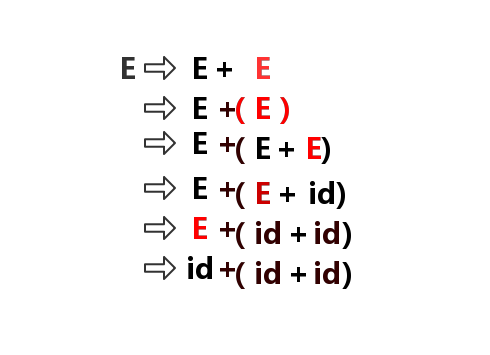
注: 1.最右推导的逆过程称为最左规约。
2. 在自底向上的分析中,总是采用最左规约的方式因此把最左规约称为规范规约,而最右推导相应地称为规范推导。
最左推导和最右推导的唯一性
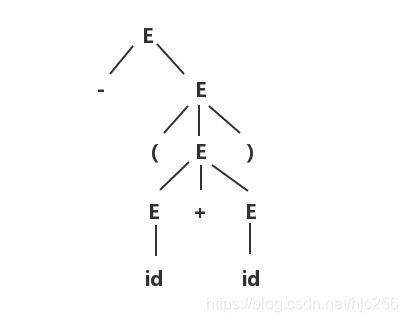
给定一棵如上图所示分析树,其推导过程不是唯一的。因为可以选择句型中任意非终结符来进行替换。但是,一个分析树的最左和最右推导都是唯一的。因为在推导的每一步,当前句型的最左或最右非终结符都是唯一的。
因为分析器是自左向右的扫描字符串,所以自顶向下的语法分析采用最左推导方式。
最左推导例子
文法:
-
E→TE′
-
E′→TE′∣ϵ
-
T→FT′
-
T′→∗FT′∣ϵ
-
F→(E)∣id
输入:
id+id∗id
分析树:
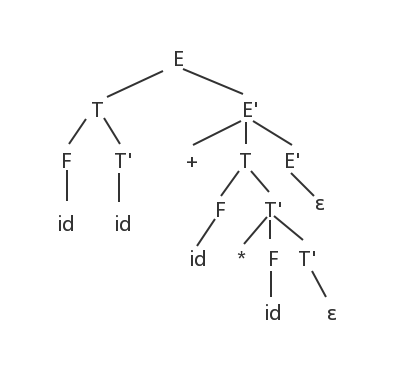
因为该分析树的叶节点从左到右排列与输入相同,所以输入是这个文法的一个句子。
自顶向下语法分析的通用形式
递归下降分析(Recursive-Descent Parsing)
- 由一组过程组成,每个过程对应一个非终结符
- 从文法开始符号
S对应的过程开始,其中递归调用文法中其他非终结符对应的过程。如果
S对应的过程体恰好扫描了整个输入串,则成功完成语法分析。
伪代码形式,以下即为一个过程:
C++voidA()//选择一个A产生式,根据当前输入的终结符来选for(i=1tok)if(xi是一个非终结符号)调用过程xi();//xi()就是这一候选式对应的方法类似于A()elseif(xi等于当前的输入符号)读入下一个输入符号;
在递归下降分析的过程中,可能会出现有多个以当前输入的终结符开头的产生式,所以就要一个一个试,这就可能要回溯的情况,效率较低。
需要回溯的分析器,称作不确定的分析器。
预测分析(Predictive Parsing)
预测分析是递归下降分析的一个特例,它不需要回溯(通过剪枝),是一种确定的自顶向下分析方法,通过在输入中向前看固定个数(通常为1)个符号来选择正确的A-产生式。
可以对某些文法构造出向前看k个输入符号的预测分析器,该类文法又是也称为 LL(k) 文法类。