自顶向下的原地归并排序
归并排序是一种简单的递归排序算法。
思路:归并排序即是将两个有序的数组归并成一个更大的有序数组。那么我们要将一个数组排序,我们可以先将这个数组分成两半分别排序,然后将结果归并起来。
其:
- 对任意长度的为N的数组的排序时间和NlogN成正比
- 需要额外的空间,所需的空间大小和N成正比
归并排序的速度非常快,但是却需要额外的空间。为什么需要额外的空间尼?
因为我们使用归并排序时是将两个不同的有序数组归并到第三个数组中去,这就导致了如果我们对一个大数组进行归并,会进行很多次归并,而每次归并的时候都会创建一个新的数组来存储结果。
如何解决?
我们希望做到一种原地归并的方法。即对数组的前后两部分分别排序,然后就在数组中对元素进行移动,而不需要创建新的数组,来节省创建数组的空间。
自顶向下是什么意思?
从原数组开始,对原数组进行递归的拆分排序,一直拆到最下层。在最下层排序完成之后,又从最下层开始,一步一步的归并回来。
实例:
public class Merge {
private static Comparable[] aux;//辅助数组
public static void sort(Comparable[] a) {
aux = new Comparable[a.length];
sort(a, 0, a.length - 1);
}
public static void sort(Comparable[] a, int start, int end) {
if (end <= start)
return;
int mid = start + (end - start) / 2;
sort(a, start, mid); //对左边排序
sort(a, mid + 1, end); //对右边排序
merge(a, start, mid, end);
}
private static void merge(Comparable[] a, int start, int mid, int end) {
//将a[start-mid]和a[(mid+1)-end]归并
int i = start;
int j = mid + 1;
for (int k = start; k <= end; k++) {
aux[k] = a[k]; //先复制数组
}
for (int k = start; k <= end; k++) { //进行归并操作,将左右归并
if (i > mid)
a[k] = aux[j++];
else if (j > end)
a[k] = aux[i++];
else if (less(aux[i], aux[j]))
a[k] = aux[i++];
else
a[k] = aux[j++];
}
}
//less(),each(),show()以及测试代码见博主其他排序文章,篇幅有限,这里不给出
//https://blog.csdn.net/qq_41906510/article/details/105590998
}
在代码中我们可以看见,最关键的归并方法merge()中,有四个判断。这四个判断代表的意义和产生的效果分别是:
- 左半部分用尽:取右半部分的元素
- 右半部分用尽,取左半部分的元素
- 左半部分的当前元素小于右半部分的当前元素:取左半部分的元素
- 左半部分的当前元素大于右半部分的当前元素:取右半部分的元素
根据这样的取值归并之后,就可以成功的将两个小数组归并成一个大数组。
上文提到,我们整个流程是将大数组拆分成小数组,然后将小数组排序,最后归并。在代码中的sort()方法里可以看见,我们每次是将数组进行对半拆分,这样拆分会不断的将数组缩小,直到缩小到数组只有两个元素(一个元素时就直接返回)。对这只有两个元素的数组进行merge()方法,其实就相当于对两个只有一个元素的数组进行归并。在这个过程中,通过上文提到的四个判断,让这个有两个元素的小数组达到有序。
假如有一个长度为16的数组,那么整个拆分过程如下:
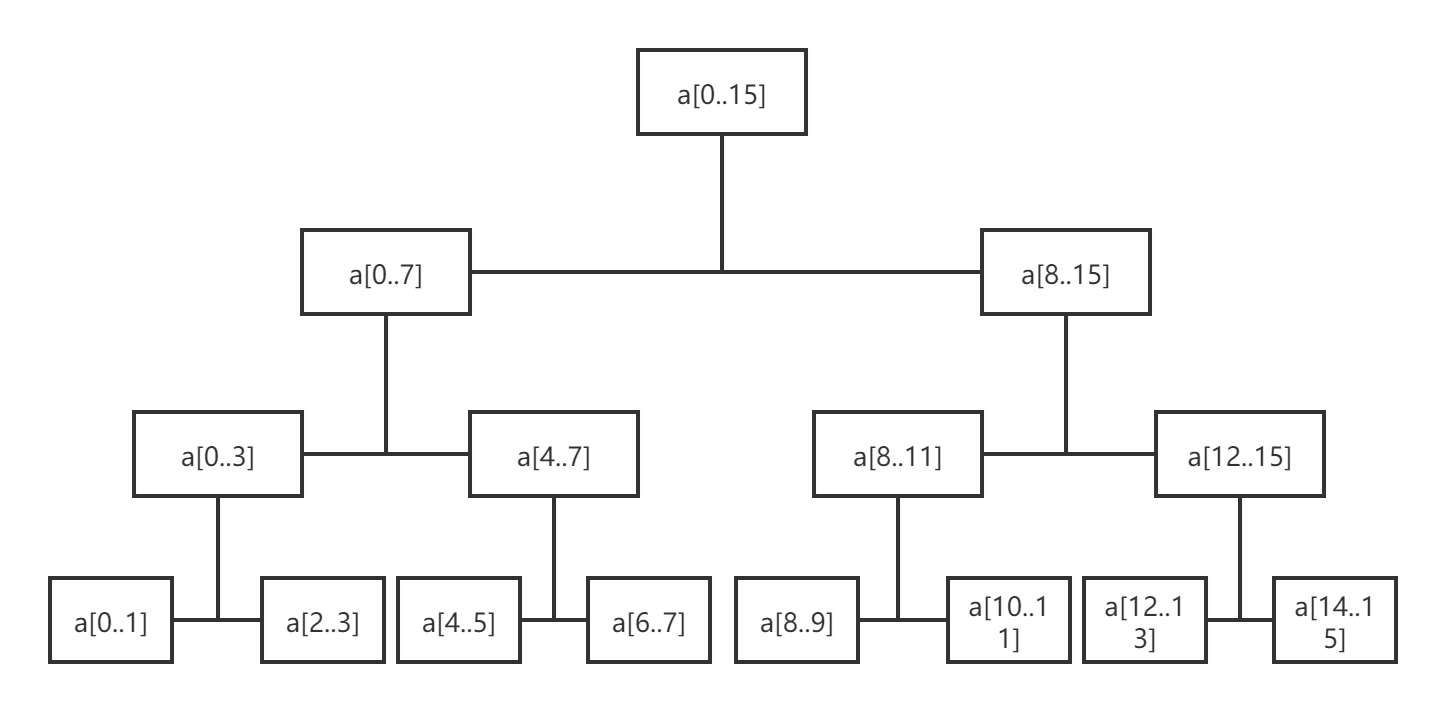
我们可以看到,拆分到最后一层时,每个小数组已经只有两个元素。我们对最下层的每个小数组进行归并时,是将数组中的两个元素分成两部分,通过排序归并到原数组中。最下层完成排序之后,两两归并成倒数第二层…一直到最上层,即完成排序过程。
