- 上一节我们利用线性回归模型,预测了岩石和矿石的分类问题,但是我们发现训练集的预测效果比预测集的好,这就可能是过拟合导致的。
- 下面便介绍今天的学习内容:通过设置合适的惩罚系数 α 来控制回归系数 β 不至于过大, 其中有一种称为“岭回归”具体实现方案,其对应的数学表示:
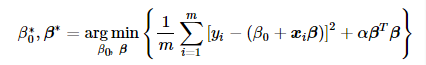
于是解决过拟合的问题变成对选择适合 α 进行训练,使测试集预测的误差最小。
注意:当 α=0时,就是普通的最小二乘法问题。
这里公式推导就不介绍了,具体的实现sklearn里面的Ridge()已经帮我们写好了,只需要传入 α 进行训练找到合适的 α 即可。
from sklearn import linear_model
linear_model.Ridge(alpha)
- 导入数据以及分测试集训练集和上一节一样,就不多啰嗦
target_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data"
#其中header和prefix的作用为在没有列标题时指定列名
df = pd.read_csv(target_url, header=None, prefix='V')
df['V60'] = df.iloc[:,-1].apply(lambda v:1.0 if v== 'M' else 0.0)
from sklearn.model_selection import train_test_split
train_X,test_X,train_y,test_y = train_test_split(df.iloc[:,:-1],df.iloc[:,-1],test_size=0.3,random_state=5)
- 选择合适的 α 喂入Ridge()函数进行训练,并将误差衡量标准进行比较,找到最合适的 α 。(这里我们先将 α 设置的值较分散,找到合适的 α 区间再将其值设置的细化一些)
# 选择alpha列表(一般先按10的倍数递减,在按小间隙找最优)
#alphaList = [0.1**i for i in range(-3, 6)]
alphaList = [1,2,3,4,5,6,7,8,9,10]
aucList = []
for alph in alphaList:
model = linear_model.Ridge(alpha = alph)
model.fit(train_X, train_y)
#fpr为假阳性率:FP / (FP+TN)--所有N负例中预测错的
#tpr为真阳性率:TP/ (TP + FN)--所有P正例中预测对的
fpr, tpr, thresholds = roc_curve(test_y, model.predict(test_X))
#两点与X轴围成的面积,越大越好
aucList.append(auc(fpr, tpr))
print ("alpha对应的AUC误差:")
for i in range(len(alphaList)):
print (alphaList[i],aucList[i])
# 绘制alpha-误差曲线
x = range(10)
plt.plot(x, aucList, 'k')
plt.xlabel("alpha")
plt.ylabel("AUC")
plt.show()
- 两次结果依次为:
alpha对应的AUC误差:
999.9999999999999 0.7520408163265306
99.99999999999999 0.7897959183673469
10.0 0.8755102040816326
1.0 0.8530612244897959
0.1 0.836734693877551
0.010000000000000002 0.7989795918367347
0.0010000000000000002 0.7673469387755102
0.00010000000000000002 0.7642857142857143
1.0000000000000003e-05 0.7642857142857142

alpha对应的AUC误差:
1 0.8530612244897959
2 0.8704081632653062
3 0.8785714285714286
4 0.8755102040816326
5 0.8765306122448979
6 0.8816326530612244
7 0.8775510204081634
8 0.8785714285714286
9 0.876530612244898
10 0.8755102040816326

- 选取最佳模型,并画出最佳模型预测值与实际值的散点图
# 最佳模型
idx = np.argmax(aucList)
alphBest = alphaList[idx]
print ("最佳alpha:", alphBest)
model = linear_model.Ridge(alpha=alphBest)
model.fit(train_X, train_y)
# 预测 与 实际 的散点图
plt.scatter(model.predict(test_X), test_y, s=100, alpha=0.3)
plt.xlabel("预测值")
plt.ylabel("实际值")
plt.show()
- 结果为:
分析结果看出<0.6的值基本上都被划分为负例,>0.4的值基本上都被划分为正例。

- 最后让我们来对比一下岭回归和普通线性回归在测试集和训练集上的混淆矩阵和误分类差别,还是用昨天的混淆矩阵相关代码:
predict_train = model.predict(train_X)
predict_test = model.predict(test_X)
#计算混淆矩阵
def confusionMatrix(predicted, actual, threshold):
TP, FP, TN, FN = [0.0]*4
for i in range(len(actual)):
if actual[i] > 0.5:
if predicted[i] > threshold:
TP += 1.0
else:
FN += 1.0
else:
if predicted[i] > threshold:
FP += 1.0
else:
TN += 1.0
return [TP, FP, TN, FN]
#
##索引重置
train_y.index = range(len(train_y))
tp_train, fp_train, tn_train, fn_train = confusionMatrix(predict_train, train_y, 0.5)
test_y.index = range(len(test_y))
tp_test, fp_test, tn_test, fn_test = confusionMatrix(predict_test, test_y, 0.5)
- 结果为:
训练集上阈值为0.5的混淆矩阵:
[[66. 10.]
[15. 54.]]
训练集上阈值为0.5的误分类:
0.1724137931034483
测试集上阈值为0.5的混淆矩阵:
[[27. 8.]
[ 7. 21.]]
测试集上阈值为0.5的误分类:
0.23809523809523808
可见测试集上的误分类有所下降0.03,训练集上的误分类有所上升0.13,过拟合现象有所缓解。