学习参考用书:Machine Learning in Python:Essential Techniques for Predictive Analysis
Rock or Mine 岩石还是矿石问题
1.获取数据并简单分析
- 代码
import pandas as pd
target_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data"
#其中header和prefix的作用为在没有列标题时指定列名
df = pd.read_csv(target_url, header=None, prefix='V')
#打印数据形状
print (df.shape)
#打印数据框数据类型的个数
print (df.get_dtype_counts())
#打印整体数据框(包括每列个数、平均值、标准差、最大最小值等)
print (df.describe())
- 结果展示
(208, 61)
float64 60
object 1
dtype: int64V0 V1 V2 V3 V4 ……
count 208.000000 208.000000 208.000000 208.000000 208.000000
mean 0.029164 0.038437 0.043832 0.053892 0.075202
std 0.022991 0.032960 0.038428 0.046528 0.055552
min 0.001500 0.000600 0.001500 0.005800 0.006700
25% 0.013350 0.016450 0.018950 0.024375 0.038050
50% 0.022800 0.030800 0.034300 0.044050 0.062500
75% 0.035550 0.047950 0.057950 0.064500 0.100275
max 0.137100 0.233900 0.305900 0.426400 0.401000
- 结果分析
数据由208行61列组成,其中前60列为采样数据(float类型),具体含义为:207个采样点,每个采样点才60个数据(按照频率采样),最后一列为最终结果判断(R:rock; M:mine)。
数形结合
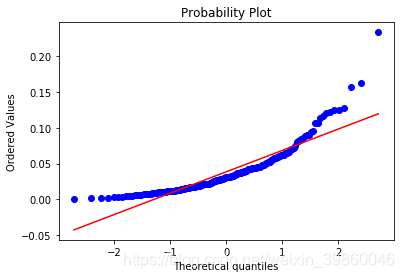
- 分位图展示异常点
分位图是原数据与正态分布数据的对比
import matplotlib.pyplot as plt
from scipy import stats
#分位图(以第二列为例),其中蓝线为列数据分布;红线代表正态分布,截距为列均值、斜率为标准差
stats.probplot(df.loc[:,1], plot = plt)
plt.show()
- 平行坐标图看Rock&Mine数据差异
#平行坐标图,蓝色:rock;红色:mine
for i in range(df.shape[0]):
if df.loc[i,60] == "R":
pcolor = "blue"
else:
pcolor = "red"
df.iloc[i,0:60].plot(color = pcolor)
plt.show()
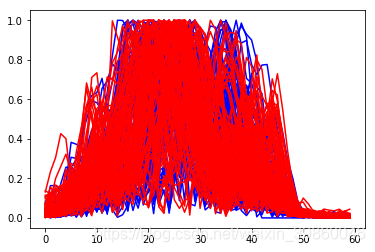
图中我们观察到蓝线和红线有很大程度的交叉,说明岩石数据和矿石数据之间的对比并不足够明显,但是在[20,30]区间的下半部分和[32,41]区间的上半部分还是有一些区分的。
利用代码看一下岩石和矿石在这些频率的数据差异:
from random import uniform
# alpha代表透明度;s代表数据点的大小
plt.scatter(df["V25"], df["V60"].apply(lambda v: (1.0 if v== 'M' else 0.0)+uniform(-0.1,0.1)), alpha=0.4, s=20)
plt.show()
plt.scatter(df["V35"], df["V60"].apply(lambda v: (1.0 if v== 'M' else 0.0)+uniform(-0.1,0.1)), alpha=0.4, s=20)
plt.scatter(df["V38"], df["V60"].apply(lambda v: (1.0 if v== 'M' else 0.0)+uniform(-0.1,0.1)), alpha=0.4, s=20)
plt.show()
结果展示:
第25个属性岩石矿石数据对比图:
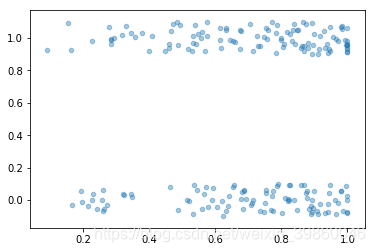
第35、38个属性岩石矿石数据对比图:

结果分析:
以第25个属性为例,岩石和矿石的数据分布在<0.5时还是有区别的,具体分析可以日后再做
- 标签间相关性
#label cor
print ("第1属性和第2属性的相关系数:",df.V0.corr(df.V1))
print ("第1属性和第31属性的相关系数:",df.V0.corr(df.V30))
#画属性相关性热度图
_df = df.copy()
_df["V60"] = _df["V60"].apply(lambda v: 1.0 if v== 'M' else 0.0)
plt.pcolor(_df.corr())
plt.xlim((0,61))
plt.ylim((0,61))
plt.show()
结果:
第1属性和第2属性的相关系数: 0.7358956043135682
第1属性和第31属性的相关系数: -0.048369907110591526
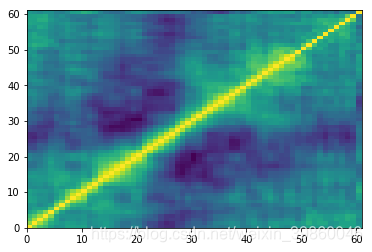
数据分析:
相邻频率之间采集的数据相关性较大(eg.label1&label2),从热度图也可以印证这一点。