x.1 Linear Regression Theory
x.1.1 Model
线性回归的模型如下:
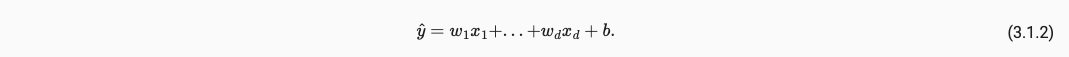
我们给定d个特征值 x 1 , x 2 , . . . , x d x_1, x_2, ..., x_d x1,x2,...,xd,最终产生输出yhat,我们产生的yhat要尽量拟合原来的值y,在这一拟合过程中我们通过不断修改 w 1 , . . . , w d 和 b w_1, ..., w_d和b w1,...,wd和b来实现。
x.1.2 Stategy or Loss
如何评价这个拟合好不好呢,我们的loss/strategy选择为MSE,对于单个点的损失如下:
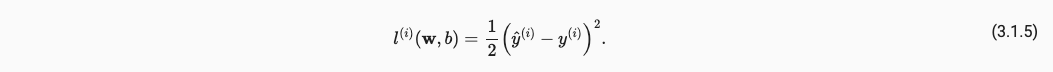
将全部的点都添加至损失,得到,
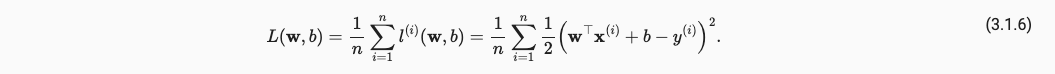
最终我们需要做的就是最小化Loss,如下:
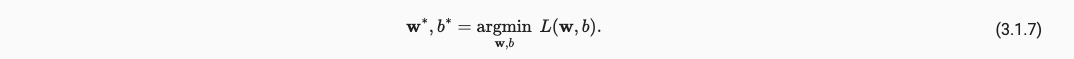
x.1.3 Algorithm
我们使用什么algorithm/optimizer来最小化loss呢?这里采用了Minibatch Stochastic Gradient Descent,mini-batch SGD也是深度学习中最常用的方法。
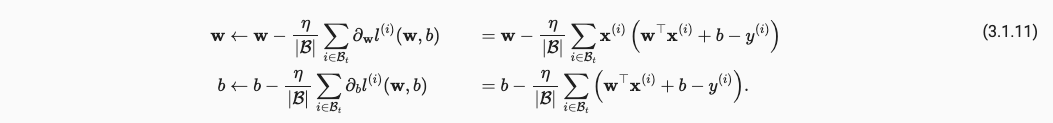
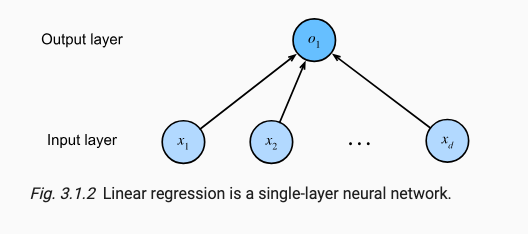
x.1.4 Nerual Network
线性回归的过程类似于神经元的表达,多个输入产生一个输出,
x.2 Experiments
x.2.1 手撕一个Linear Regression*
在下面的内容中,只使用了torch的自动微分来实现Linear Regression,值得反复推敲。
'''
手撕一个线性回归,包括:
1. 构造真实线性回归式子
2. 初始化权重
3. 生成一个迭代器每次取batch_size个数据
4. 构造model线性回归
5. 构造cost funtion-MSE
6. 构造optimizer-SGD
7. 开始每个epoch的训练, 注意梯度何时更新:
先loss(model(), y)计算loss来构造计算图; backward()计算梯度参数grad; param-=lr*grad更新梯度; param.zero_()梯度变零; 循环。
线性回归简洁表示:
这其实是一个feature=2, n=1000, label.shape=1的二元线性回归问题y = a * x_1 + b * x_2 + c: 用1000个样本(x_1, x_2)来拟合出a, b, c.
线性回归的简洁实现
'''
import random
import torch
# 生成n = 1000组数据, label 1维, features 2维; => weight [2, 1]
# 初始化 weight 和 bias 的初始值
def synthetic_data(w, b, num_examples):
"""⽣成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0],'\nlabel:', labels[0])
# 手撕一个DataLoader
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
# 让我们尝试使用iter取batch_size个data
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
# 初始化权重,并使用`requires_grad=True`开启其自动微分
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# model
def linreg(X, w, b):
"""线性回归模型"""
# return torch.matmul(X, w) + b
return X.mm(w) + b
# cost function
def squared_loss(y_hat, y):
"""MSE"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
# optimizer to minimize cost function
def sgd(params, lr, batch_size):
"""mini batchsize SGD"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
# 设置超参数
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
# 开始训练
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的⼩批量损失
# 因为l形状是(batch_size,1),⽽不是⼀个标量。l中的所有元素被加到⼀起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使⽤参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {
epoch + 1}, loss {
float(train_l.mean()):f}')
print(f'w的估计误差: {
true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {
true_b - b}')
在这里补充一下with torch.no_grad(),这个函数用于在上下文中取消梯度更新。详见https://blog.csdn.net/qq_43369406/article/details/131115578
x.2.2 Concise Implementation of Linear Regression 简明实现
在model部分,由于Linear线性层由于经常需要使用到,故现代Pytorch已经将其封装为了一个API函数即torch.nn.LeazyLinear。这个API只关注输出的全连接层的结点个数。
在Loss部分,用torch.nn.MSELoss代替。
在Optimizer部分,用torch.optim.SGD代替。
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
"""
1. define model
"""
class LinearRegression(d2l.Module): #@save
"""The linear regression model implemented with high-level APIs."""
def __init__(self, lr):
super().__init__()
self.save_hyperparameters()
self.net = nn.LazyLinear(1) # The latter allows users to only specify the output dimension | Specifying input shapes is inconvenient
self.net.weight.data.normal_(0, 0.01)
self.net.bias.data.fill_(0)
# 使用bulit-in func `__call__` 实现forward
@d2l.add_to_class(LinearRegression) #@save
def forward(self, X):
return self.net(X)
"""
2. define loss
"""
@d2l.add_to_class(LinearRegression) #@save
def loss(self, y_hat, y):
fn = nn.MSELoss()
return fn(y_hat, y)
"""
3. define optimizer
"""
@d2l.add_to_class(LinearRegression) #@save
def configure_optimizers(self):
return torch.optim.SGD(self.parameters(), self.lr)
"""
4. training
"""
model = LinearRegression(lr=0.03)
data = d2l.SyntheticRegressionData(w=torch.tensor([2, -3.4]), b=4.2)
trainer = d2l.Trainer(max_epochs=3)
trainer.fit(model, data)
@d2l.add_to_class(LinearRegression) #@save
def get_w_b(self):
return (self.net.weight.data, self.net.bias.data)
w, b = model.get_w_b()
print(f'error in estimating w: {
data.w - w.reshape(data.w.shape)}')
print(f'error in estimating b: {
data.b - b}')
x.3 Generalization泛化能力
x.3.1 过拟合/欠拟合现象
ML机器学习的本质上是要pattern recognition模式识别(CVPR中的PR的由来),但是确定我们模型是真正发现了一种泛化的模式,还是简单地记住了数据是关键点。发现可以泛化的模式是机器学习的根本问题。
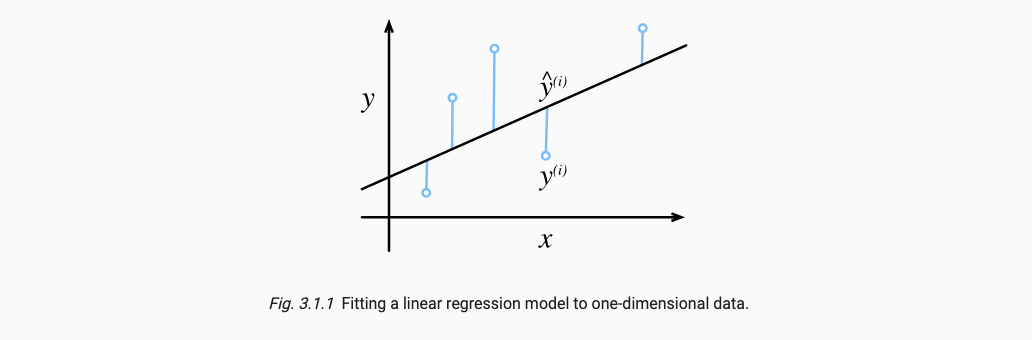
过拟合欠拟合现象如下图所示:
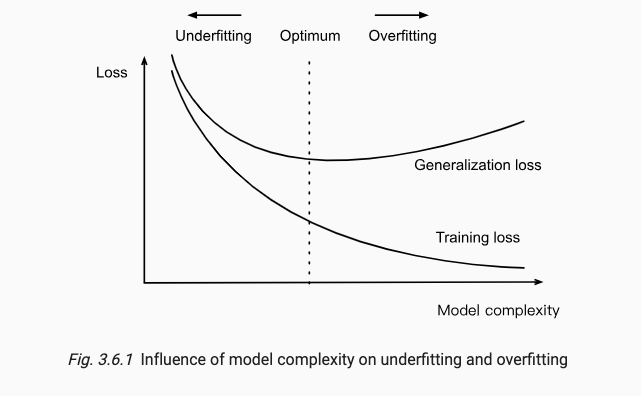
x.3.2 过拟合/欠拟合的决定性因素
过拟合与欠拟合的决定性因素是模型复杂性和可用训练集的大小。
过拟合导致的因素常有:
- 可调整参数的数量。当可学习参数较多时,即你的parameters过多时,更容易过拟合。(减小模型参数量;或者引入早停减少训练轮次)。
- 参数的取值。当权重的取值范围较大时,模型更容易过拟合。(引入数据归一化)
- 训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。(增加数据集;或者引入K折交叉验证)。
欠拟合则是由于训练轮次过少导致的。
x.4 Weight Decay权重衰减
减少过拟合最方便的方式便是引入足够多的数据集,但是往往这并不现实,所以本章节将重点放在regularization正则化技术上。
#TODO::补充一下归一化,标准化,正则化区别。
补充一下:
normalization归一化:使得数据分布在[0, 1]或者[-1, 1]。通过除以极差(推荐)或者数据类型最大值实现。
standardization标准化:使得数据正态分布。通过减去mu除以sigma实现。
regularization正则化:减过拟合方式。
回顾一下数值分析中插值法拟合离散点过程,我们可以通过调整拟合多项式的阶数来限制模型的容量,而这里的限制特征的数量就是缓解过拟合的一种常用技术,这种技术属于正则化技术。
常见的正则化技术有L1正则化和L2正则化,而L2正则化也被称做Weight Decay权重衰减技术,它被使用地更为广泛,它使用了L2范数,L2正则化线性模型构成经典的ridge regression岭回归,L2正则化使得我们的学习算法更偏向于那些在大量特征上权重均匀分布的模型,它对大量的特征都有考虑到。而L1正则化线性回归构成经典的lasso regression套索回归,L1惩罚会使得模型的权重只集中在一小部分特征上,而使得其他权重清除为0,这称为feature selection特征选择。他们都是在指定优化器的时候实现的,例如SGD中指定weight_decay参数。
讲解一下L2正则化。在Loss中,常见的MSE loss如下:
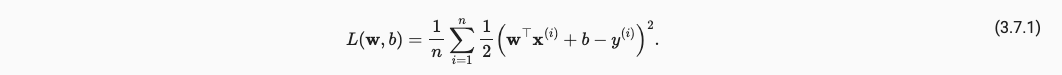
为了实现L2正则化,即限制特征数量,考虑特征对损失的影响,我们需要引入L2惩罚项,即在loss中添加权重,可以如下添加:
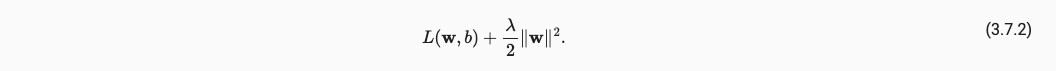
于是梯度更新变成了如下:
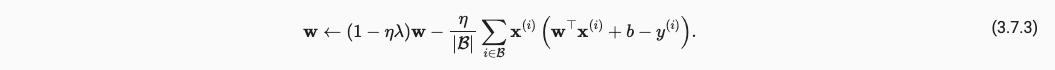
代码实现:
import torch
from torch import nn
from d2l import torch as d2l
# generate data
class Data(d2l.DataModule):
def __init__(self, num_train, num_val, num_inputs, batch_size):
self.save_hyperparameters()
n = num_train + num_val
self.X = torch.randn(n, num_inputs)
noise = torch.randn(n, 1) * 0.01
w, b = torch.ones((num_inputs, 1)) * 0.01, 0.05
self.y = torch.matmul(self.X, w) + b + noise
def get_dataloader(self, train):
i = slice(0, self.num_train) if train else slice(self.num_train, None)
return self.get_tensorloader([self.X, self.y], train, i)
# l2 norm
def l2_penalty(w):
return (w ** 2).sum() / 2
# model
class WeightDecayScratch(d2l.LinearRegressionScratch):
def __init__(self, num_inputs, lambd, lr, sigma=0.01):
super().__init__(num_inputs, lr, sigma)
self.save_hyperparameters()
def loss(self, y_hat, y):
return (super().loss(y_hat, y) +
self.lambd * l2_penalty(self.w))
# train
data = Data(num_train=20, num_val=100, num_inputs=200, batch_size=5)
trainer = d2l.Trainer(max_epochs=10)
def train_scratch(lambd):
model = WeightDecayScratch(num_inputs=200, lambd=lambd, lr=0.01)
model.board.yscale='log'
trainer.fit(model, data)
print('L2 norm of w:', float(l2_penalty(model.w)))
train_scratch(0) # training without weight decay
train_scratch(3) # training with weight decay
# Concise Implementation
class WeightDecay(d2l.LinearRegression):
def __init__(self, wd, lr):
super().__init__(lr)
self.save_hyperparameters()
self.wd = wd
def configure_optimizers(self):
return torch.optim.SGD([
{
'params': self.net.weight, 'weight_decay': self.wd},
{
'params': self.net.bias}], lr=self.lr)
model = WeightDecay(wd=3, lr=0.01)
model.board.yscale='log'
trainer.fit(model, data)
print('L2 norm of w:', float(l2_penalty(model.get_w_b()[0])))