今天我们来讨论线性回归问题,数据来源是该系列第一天的岩石与矿石的数据,主要用到回归模型是:
from sklearn import linear_model
model = linear_model.LinearRegression()
首先在第一天的学习中我们已经通过以下代码拿到了数据df(DataFrame):
target_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data"
#其中header和prefix的作用为在没有列标题时指定列名
df = pd.read_csv(target_url, header=None, prefix='V')
做回归分析时,我们把每行前60列数据作为输入数据,最后一列判断是否为岩石/矿石的做为输出答案,这里为了量化,用1来代替M(mine),用0来代替R(rock):
df['V60'] = df.iloc[:,-1].apply(lambda v:1.0 if v== 'M' else 0.0)
在所有数据中(利用函数model_selection import train_test_split)随机选出1/3做为测试集,2/3做为训练集:
from sklearn.model_selection import train_test_split
train_X,test_X,train_y,test_y = train_test_split(df.iloc[:,:-1],df.iloc[:,-1],test_size=0.3,random_state=5)
利用训练集数据训练模型,并利用训练好的模型预测训练集和测试集数据得到的结果输出:
from sklearn import linear_model
model = linear_model.LinearRegression()
model.fit(train_X, train_y)
predict_train = model.predict(train_X)
predict_test = model.predict(test_X)
为了衡量预测结果和真实值之间的预测好坏,我们引入混淆矩阵的概念如下图:
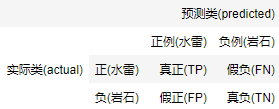
相应的判断代码如下:
#计算混淆矩阵
def confusionMatrix(predicted, actual, threshold):
TP, FP, TN, FN = [0.0]*4
for i in range(len(actual)):
if actual[i] > 0.5:
if predicted[i] > threshold:
TP += 1.0
else:
FN += 1.0
else:
if predicted[i] > threshold:
FP += 1.0
else:
TN += 1.0
return [TP, FP, TN, FN]
最后打印查看训练集和测试集预测的情况:
#索引重置
train_y.index = range(len(train_y))
tp_train, fp_train, tn_train, fn_train = confusionMatrix(predict_train, train_y, 0.5)
test_y.index = range(len(test_y))
tp_test, fp_test, tn_test, fn_test = confusionMatrix(predict_test, test_y, 0.5)
#print
import numpy as np
print ("训练集上阈值为0.5的混淆矩阵为:\n", np.array([[tp_train,fn_train],[fp_train,tn_train]]))
print ("训练集上阈值为0.5的误分类率为:\n", 1.0*(fp_train+fn_train)/(tp_train+tn_train+fp_train+fn_train))
print ("测试集上阈值为0.5的混淆矩阵为:\n", np.array([[tp_test,fn_test],[fp_test,tn_test]]))
print ("测试集上阈值为0.5的误分类率为:\n", 1.0*(fp_test+fn_test)/(tp_test+tn_test+fp_test+fn_test))
结果如下:
训练集上阈值为0.5的混淆矩阵为:
[[71. 5.]
[ 1. 68.]]
训练集上阈值为0.5的误分类率为:
0.041379310344827586
测试集上阈值为0.5的混淆矩阵为:
[[25. 10.]
[ 7. 21.]]
测试集上阈值为0.5的误分类率为:
0.2698412698412698