上次我们介绍了L2岭回归的代码实现,本次我们将介绍L1 Lasso回归中的LARS算法。
………………………………………………………………………………………………
1. 首先看一下L1和L2范数的区别:
这一部份的学习我参考了这篇博文,感觉写得非常高屋建瓴,摘出其中我认为在这里非常值得强调的部分如下:
其实监督学习中几乎所有带参模型都可以写成最小化下面的目标函数:
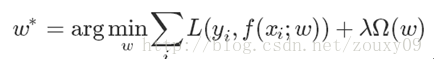
其中第一项L是训练误差要尽量小,即要求模型是要拟合我们的训练样本的;第二项是对模型规则化的要求,即要求模型要尽可能的简单防止过拟合且保证较好的模型适用性。
L1和L2范数的区别就在上式的第二项中,即有不同衡量模型规则化的标准,L1是对绝对值的约数,而L2是对平方的约束,可以分别想象约束到球内部和n边体内部。
两者不同在于L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
2. 其次介绍一下L1回归中常见的算法对比:
这部分我参考了这篇文章,详细介绍了L1回归中常见的几种算法,下面我就不做过多赘述,只是详细介绍一下LSRA算法的步骤:
1).Standardize the predictors to have mean zero and unit norm. Startwiththe residualr=y–y^,β1, β2, … . , βp= 0.
将样本中心化,标准化。残差向量 r = y – y^ ,系数β初始化为0.
2).Find the predictorxjmostcorrelated withr.
寻找与残差向量相关系数最大的样本变量 .
3).Moveβjfrom0 towards its least-squares coefficient<xj,r>,until someothercompetitorxkhasas much correlation with the current residualasdoesxj.
系数沿最小二乘解的方向增大,直到另一个样本变量与残差的相关系数与当前的一样大。
4).Moveβjand βk in the directiondefined by their joint least squarescoefficient ofthe current residual on (xj,xk),until some other competitorxlhasas much correlation with the current residual.
游走点改变前进路径,沿着X1、X2的角平分线方向继续移动,直到其他变量X与残差r的相关系数与当前系数一样大。
5).Continue in this way until allppredictorshave been entered. Aftermin(N−1, p)steps, we arrive at the full least-squares solution.
继续沿着这种方式前进,直到所有的p个变量都已经加入活动集。
最终,所有变量都被选中,且残差向量r垂直于所以变量,求得最小二乘解。
3. 本次LARS算法的代码:
还是以之前的岩石与矿石的数据为例:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#读取数据
target_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data"
#其中header和prefix的作用为在没有列标题时指定列名
df = pd.read_csv(target_url, header=None, prefix='V')
df['V60'] = df.iloc[:,-1].apply(lambda v:1.0 if v== 'M' else 0.0)
# 数据标准化 并拆分成属性x和标签y
norm_df = (df - df.mean())/df.std()
xData = norm_df.values[:,:-1]; yData = norm_df.values[:,-1]
# 设置 步数 和 步长
nSteps = 350; stepSize = 0.004
# 回归系数\beta向量初始化
beta = np.array([0.0]*xData.shape[1])
# 存储每一步生成的回归系数\beta向量, 第0步就是全0向量
betaList = []
betaList.append(list(beta))
for i in range(nSteps):
#计算残差
resid = yData - xData.dot(beta)
#计算属性与残差相关性
corr = resid.dot(xData)
#找出最大相关性的属性, 并更新其beta值
idx = np.abs(corr).argmax()
corrMax = corr[idx]
beta[idx] += stepSize * corrMax / abs(corrMax)
# 存储每一步生成的回归系数\beta向量
betaList.append(list(beta))
#画图,每个步数下属性对应的beta值
plt.plot(betaList)
plt.xlabel("step")
plt.ylabel("beta")
plt.show()
4. 结果分析
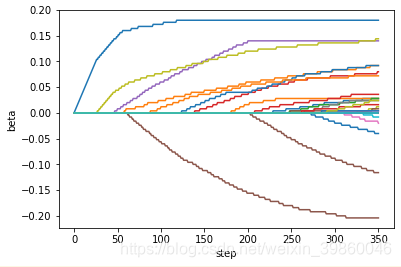
打印看下迭代到最后350步时beta参数的分布情况:
pd.value_counts(betaList[nSteps]))

可见L1的参数是十分稀疏的(有37个属性的beta值为0),这就意味着机器帮我们筛选出了一些没有用的属性将其beta设置为0,在参数选择上L1回归非常有用。
本节我们只是简单的看了下LARS算法,没有区分训练集和测试集。