Multi-Cast Attention Networks for Retrieval-based Question Answering and Response Prediction
(KDD 2018)
1.主要特点:
通常,一个句子应用一次attention,然后学习最终表示并传递给预测层。许多现有模型的明显缺点是它们通常仅限于一种attention变体,在调用一次或多次注意力机制的情况下,如果用连接来融合表示,在每次调用时,表示的加倍会使后续层中成本增加。
故针对上述问题本文旨在解决两个方面:
(1)消除调用任意k次注意力机制所需架构工程的需要,且不会产生任何后果。
(2)通过多次注意力调用建模多个视图以提高性能,与multi-headed attention相似。为此,我们引入了多播注意力(Multi-Cast Attention),这是一种新的深度学习架构,用于问答和对话建模领域的大量任务。
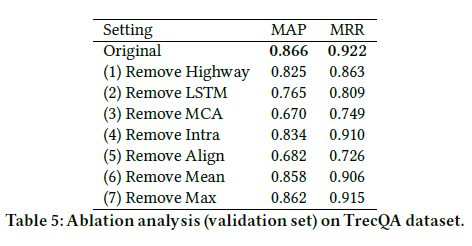
2.模型细节
2.1输入层
对于每个embedding使用highway作为输入层。
许多工作都采用一种训练过的投影层来代替原始词向量。这不仅节省了计算成本,还减少了可训练参数的数量。本文将此投影层扩展为使用highway编码器,可以解释为数据驱动的词滤波器,它们可以参数化地了解哪些词对于任务具有重要性和重要性。例如,删除通常对预测没有多大贡献的停用词和单词。与自然门控的循环模型类似,highway编码器层控制每个单词流入下一层多少信息。

2.2.attention
计算Q与D的相似度矩阵
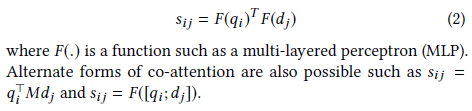
(1)max
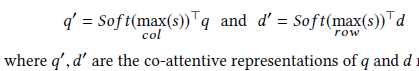
(2)mean
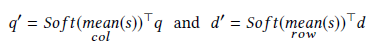
(3)alignment(对齐)
去重新对齐Q与D
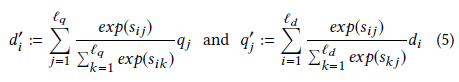
(4)self-attention
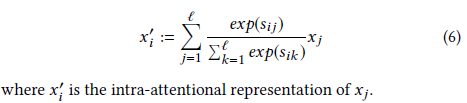
2.3.多播attention
(1)分别使用三种形式去捕捉多种特征:
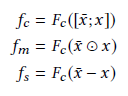
其中:
1.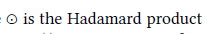
2.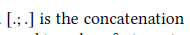
(2)压缩函数(compression function)
而 为压缩函数(compression function)讲feature压缩至一个标量,文中使用了3种:
效果比较(三种效果相差不大):

(3)如何使用?
+ 对于每个query-document对,应用Co-Attention with mean-pooling,Co-Attention with max-Pooling和Co-Attention with alignment-pooling。 此外,将Intra-Attention分别单独应用于query和document。
+ 每个注意力投射产生三个标量(每个单词),它们与Intra-Attention后的词向量连接在一起。最终的投射特征向量每个embedding维数+3, 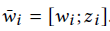
2.4 使用LSTM 编码
(1) 对于每一个Q和D,使用一个LSTM区进行编码,在Q和D之间共享权重

(2) pooling
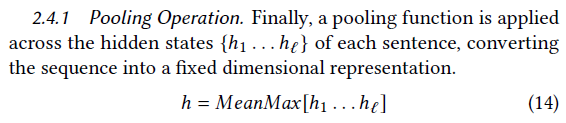
2.5 输出层
将问题和回答concat输入到两层的highway网络中

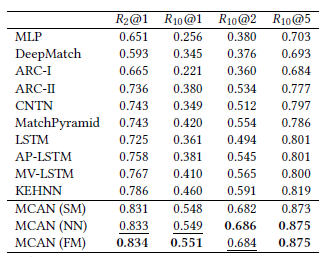
结果比较