《DYNAMIC COATTENTION NETWORKS FOR QUESTION ANSWERING阅读理解论文阅读笔记》
这篇文章发表在ICLR2017上,在两个经典模型Match LSTM和Bi-DAF之间。
通过四个方面来介绍这篇论文,
- Motivation
- Model
- Experiment
- Discussion
- Question
1、Motivation
- However, due to their single-pass nature, they have no way to recover from local maxima corresponding to incorrect answers.原文的解释如上。
这里我的理解,之前的Match LSTM在预测答案起止位置的时候,只考虑一次,即在passage中通过指针网络找到start,然后再继续找到end。假设这一次找的位置不正确,那么就陷入了一个local maxima。这篇论文这一个思想就是人在阅读时,可能第一眼会有一个大概的位置,然后再进行第二次第三次,把答案确定下来,即在起止位置之间反复迭代(最大4次)。
- 之前的编码层过于简单,没有充分捕获文档与问题之间的交互,该论文提出更加复杂的coattention encoder。
2、Model
整体结构:
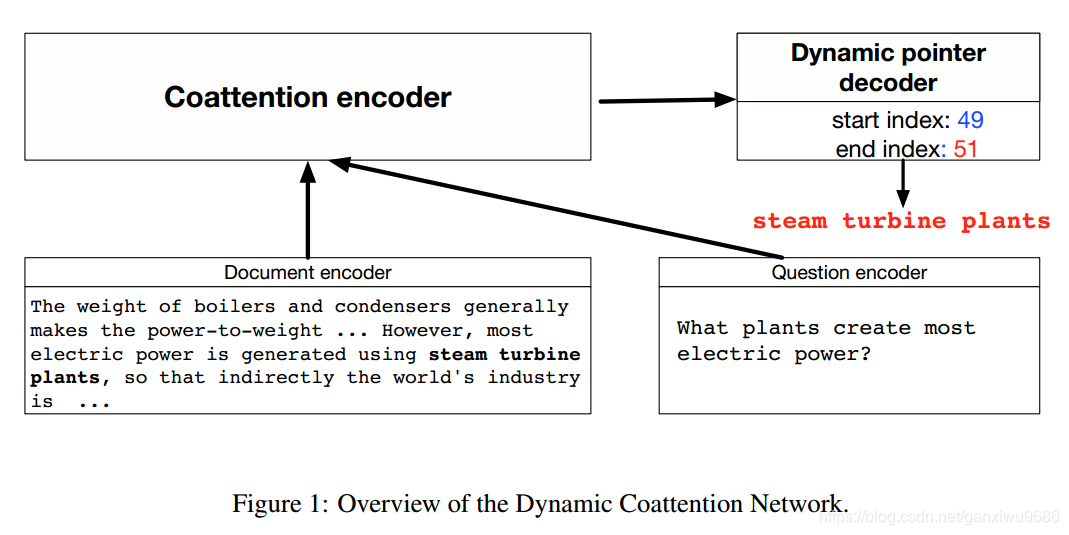
主要就是两部分:
- coattention encoder
- dynamic pointer
coattention encoder

1.文档和问题表示:
输入就是文档和问题,输出是答案起止位置对应的index。
首先
表示问题,
表示文档中的每个词对应的词向量,经过LSTM后得到,其中多了一个
后面解释:
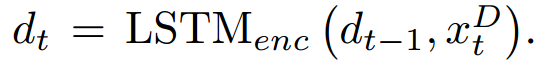
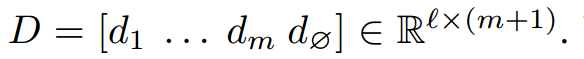
同理经过LSTM也得到
,然后得到
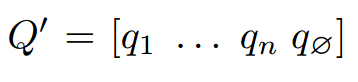
接着,文章又做了一个非线性变化,To allow for variation between the question encoding space and the document encoding space, we introduce a non-linear projection layer on top of the question encoding. 最终得到问题表示:
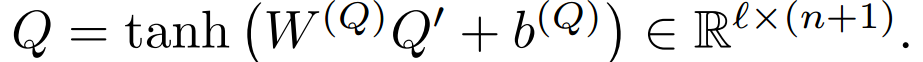
2.encoder
经过上面的表示,文档有
个词,问题有
个词。下面进行attention的计算:
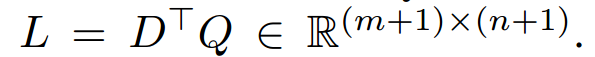
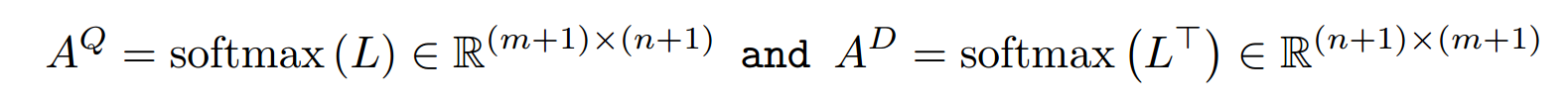
相当于做完点积之后,按行softmax;而
相当于对列做softmax。得到
,然后和问题做连接,与
相乘得到
。
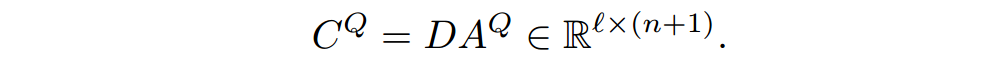
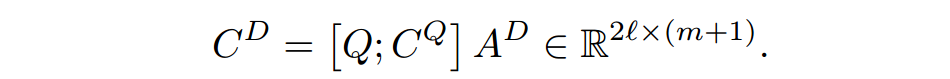
最后将
和文档连接,得到最后的表示,再经过LSTM得到passage中每一个word的表示。
(这里从公式以及维度来看,感觉 是对列做softmax,即Q中的每个词与D做attention,然后加权得到Q的表示。包含了文档信息Document-aware的Q的表示。)
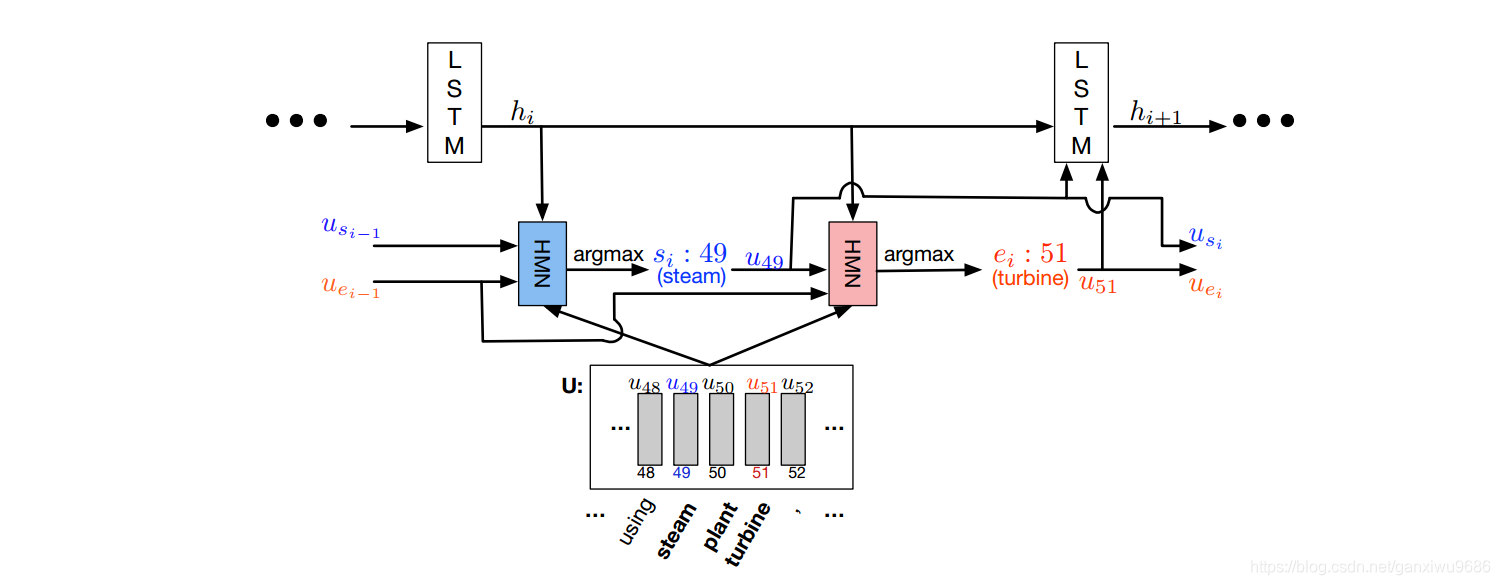
dynamic pointer
](https://img-blog.csdnimg.cn/20190304094923419.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2dhbnhpd3U5Njg2,size_16,color_FFFFFF,t_70)
1.解码端,轮流开始预测起止位置,先定义LSTM计算方式,更新state:
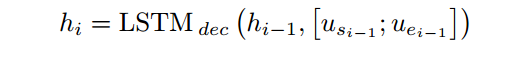
where usi−1 and uei−1 are the representations corresponding to the previous estimate of the start and end positions in the coattention encoding U.
2.我们需要通过两次softmax得到开始、结束位置,计算如下:
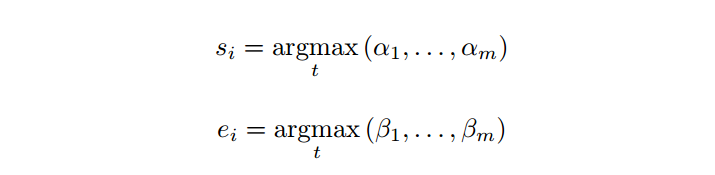
其中afa,根据前一时刻的起止位置和当前时刻的隐层state,通过一个HMN网络得到,beta同理,只不过需要用当前时刻的开始位置:
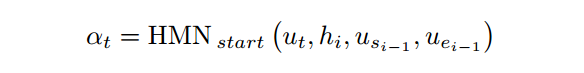
3.HMN具体展开如下:
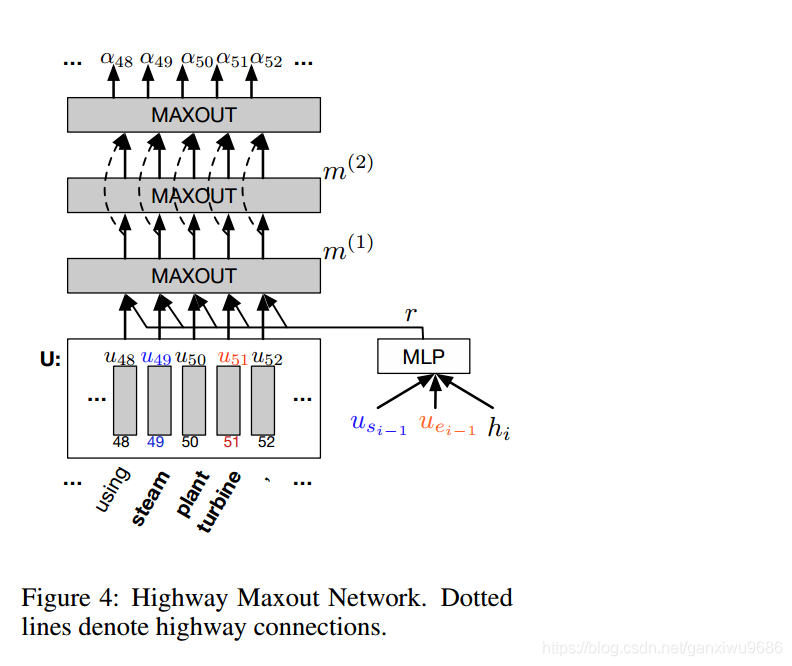
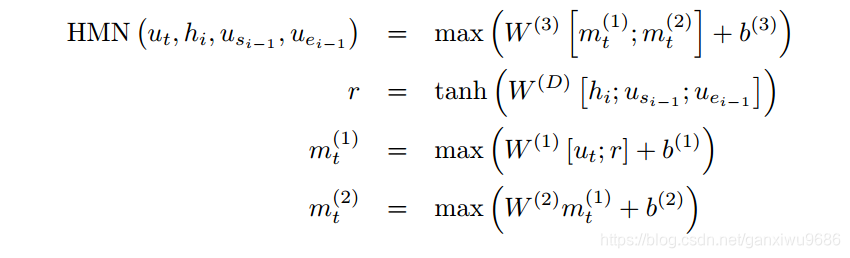
最后直到答案起止位置不变,或者达到最大迭代次数终止。
模型结构稍微有点复杂,但是分开结构来剖析还是比较好理解的。
3、Experiment
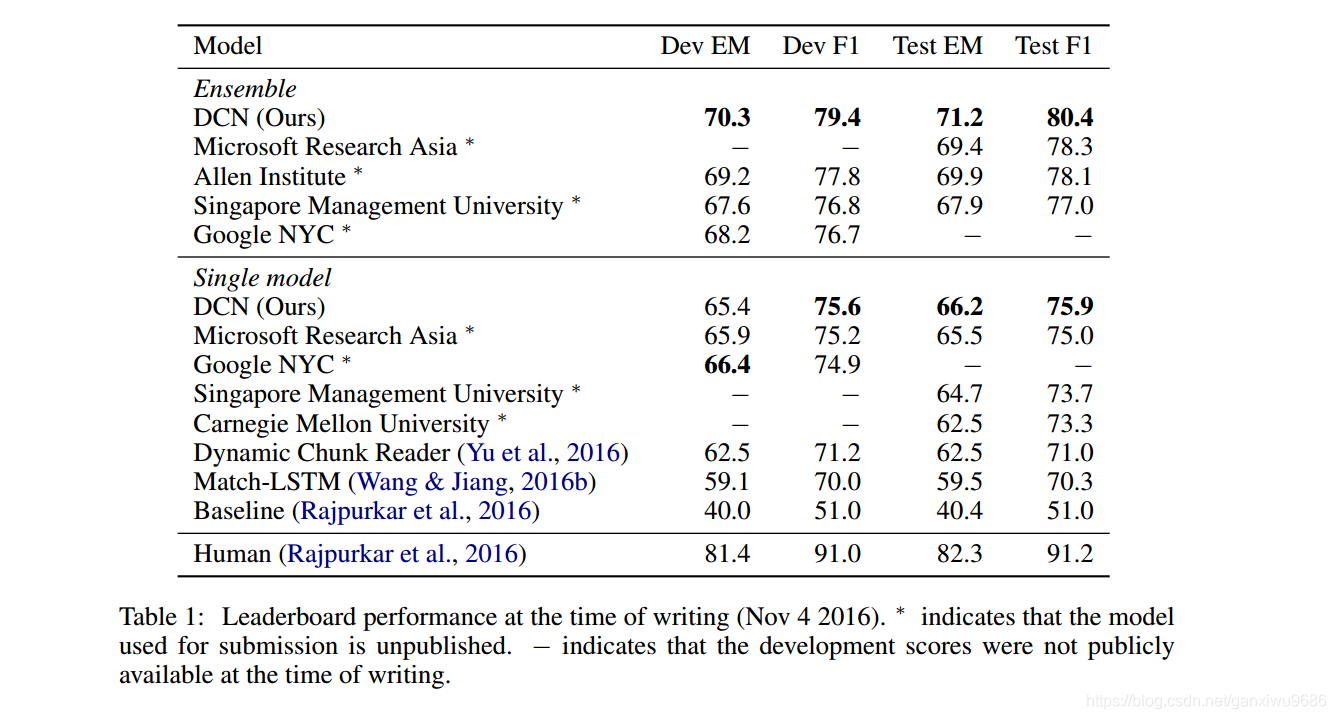
除了在各个模型上进行比较,还给出了可视化的结果。
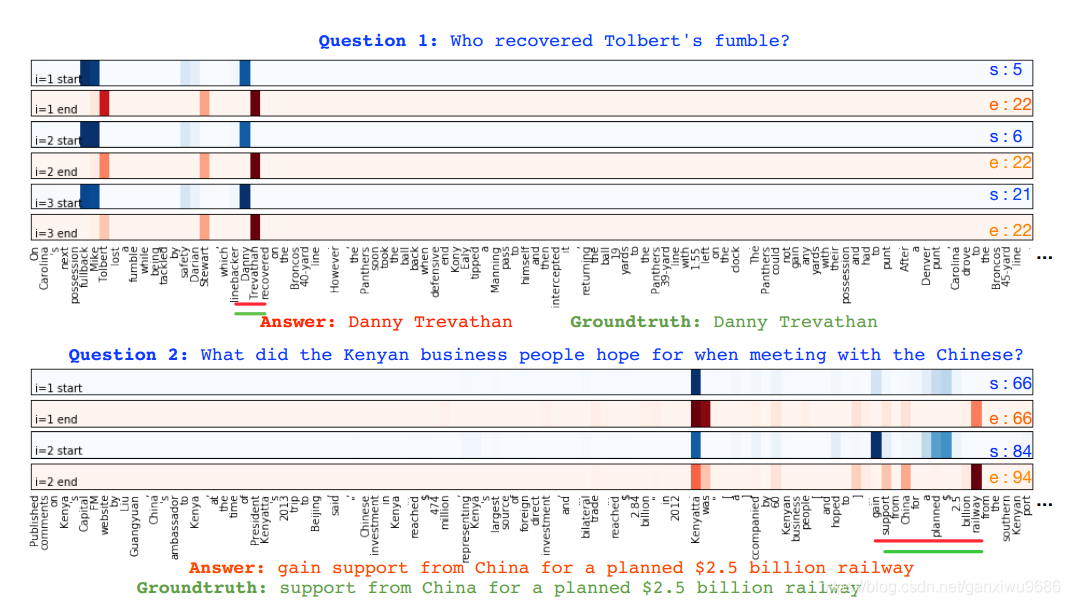

也验证了最开始的想法,对于大部分问题来说(Q3是个例外,模型对答案摇摆不定,论文没给出解释)先确定一个大致范围,再慢慢缩小。
但是对于Q2,第一次迭代完全是错误的66~66,可是第二次迭代就正确了 84~ 94,按照公式来说,只是多了 和 的信息(而且还是完全不搭架的信息66~66),就能够预测正确的起止位置?这是笔者的一个疑问。
4、Discussion
优点:
- 提出了动态指针网络,模拟了人的这种阅读过程
- 对Encoder端进行了改进
缺点:
- Encoder的改进既是优点也是缺点,过于复杂的编码端个人感觉没有必要,后面的Bi-DAF仅仅是做了一个简单的双向Attention,效果就比他好,所以在当时可能也算是一个创新点
不知道Bi-DAF加上动态指针会有什么效果。值得讨论一番。
5、Question
1.第7页,
对于Q2,第一次迭代完全是错误的66~66,可是第二次迭代就正确了 84~ 94,按照公式来说,只是多了
和
的信息(而且还是完全不搭架的信息66~66),就能够预测正确的起止位置?这是笔者的一个疑问。
2.感觉 是对列做softmax,即Q中的每个词与D做attention,然后加权得到Q的表示。但是文章说的是 是文档的表示,而且 的维度明明就是n+1啊,问题的词数也是n+1,很迷,照理文章应该不会有问题。
3.第5页,
HMN图旁边的那些维度,首先p是pooling size,最后通过HMN得到的维度是p维的,注意这里max了,所以最后是1维的。不要理解成p维的。笔者开始就理解错了。