论文解读:Question Answering over Freebase with Multi-Column Convolutional Neural Networks
KB-QA是一种问答系统任务,其是基于知识库进行的问答。给定一个知识库,其包含若干个实体和边,每两个实体和相连的边为一个三元组。实体分为客观实体和属性,客观实体就是客观存在的一般实体,例如人名地名机构名,属性则是一种特殊的实体,可以是时间、数字等字符串,也可以是年龄、配偶等。FreeBase是一个庞大的知识库,其包含领域广,基于知识库的问答任务描述大概是:给定一个问句,通过问句来判断中心实体,并在图谱中寻找可能的答案,因此简单的KB-QA任务的输入是一个知识库和问句,输出则为一个或多个实体。
本文引入一篇较早的KB-QA论文,其是一种以“信息抽取”和“向量建模”为代表的一篇论文。这篇文章是2015年ACL会议中的一篇。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | MCCNN |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 知识图谱问答系统 |
| 4 | 核心内容 | Multi-column CNN;FreeBase;KB-QA |
| 5 | GitHub源码 | |
| 6 | 论文PDF | https://www.aclweb.org/anthology/P15-1026/ |
二、全文摘要
基于知识库的自然语言问答是一项非常重要且具有挑战性的任务。大多数现有的系统都是依赖于人工特征提取,基于规则的进行问句理解和答案排序。本文引入一种多列卷积神经网络来对问句的三个方面(答案关系路径Answer Path、答案上下文Answer Context和答案类型Answer Type)进行理解和分布式表征学习,同时我们联合知识库实体和关系低维度表示向量。(问句-答案)对被用于训练我们的模型,并对候选答案进行排序。我们同样基于多任务学习利用问句对神经网络进行学习。我们使用FreeBase作为知识库,并在WebQuestion数据集上进行实验。实验结果表明我们的方法获得了更好的效果,且与当前的基线模型具有竞争力。另外我们设计一种方法来计算每个问句中每个单词在不同网络中的得分,其可以帮助我们理解我们的模型是如何学习的。
三、MCCNN模型
3.1 问题描述
通常KB-QA中的问句是以wh为开头的,例如what、which、where、why、when、who等,而问句通常也会指向一个明确的中心实体。例如“when did Avatar release in UK”,其指向的中心实体是“Avatar”,因此问句想要回答的答案也一定是以中心实体“Avatar”所在的子图中。基于这个假设,任务可以描述为:给定一个问句 ,通过实体识别或其他工具可以提取问句中的中心实体,以该中心实体所在图谱中的子图中即可包含一部分实体,这些实体可能是客观实体,也可能是属性,它们可以作为这个问句的候选答案(Candidate Answer)。可知这一部分都是可以通过NLP工具来完成的,因此KB-QA的核心任务是如何对句子进行表征,以及如何从候选答案中选出一个或多个答案。
3.2 相似度
KB-QA一般一种常用的策略是计算问句和候选答案的相似度,这也是“向量建模”的核心思想。过去方法是基于特征工程或人工表征来对句子进行向量化,而现如今基于神经网络可以自动学习低维度特征。假设问句的表征为 ,候选答案表征为 ,则它们的相似度计算为 。
3.3 多列卷积神经网络
本文提出一种多列卷积神经网络模型,来对问句和候选答案进行表征。如图所示:
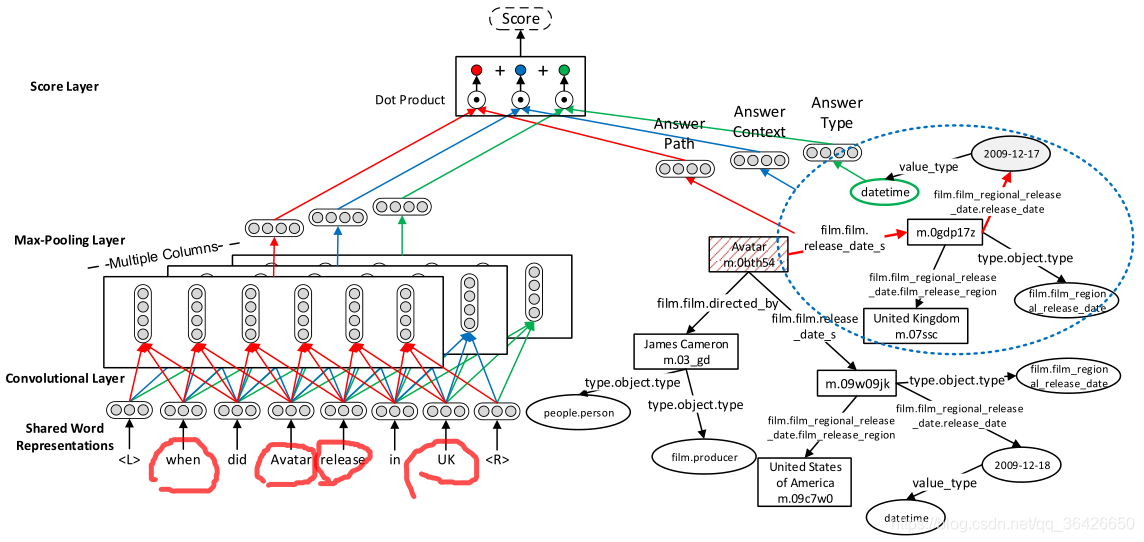
首先,使用FreeBase Search API工具对问句中的中心实体进行实体链接,链接到知识库中对应的实体。这一部分主要是搜索问句中的实体,可以认为是一种实体识别任务。其次根据中心实体,向外扩张2hop实体作为子图,其包含的所有实体(除了中心实体)均是候选答案。
其次将整个问句通过CNN进行语义表征。
我们知道FreeBase知识库包含三个方面:每个实体的实体类型(entity type)、关系路径(即实体与实体之间边的路径)以及上下文(通常表示为以某个实体为出发向外扩张n个路径——n hop),每个部分均包含于问句和候选答案相关联的信息。因此作者同时训练3个CNN网络,分别从这三个方面提取特征,CNN模型即是TextCNN,此处不再详细描述CNN的细节,其输出部分分别为
。其次对于候选答案对应的这三个方面也进行表示,下面详细说明如何对这三个方面信息进行表示:
(1)答案关系路径(Answer Path)。如图所示,问句是问阿凡达在英国的首映时间,自然以“Avatar”为中心实体在这个有限的子图范围内向各个其他实体延伸,每延伸到一个实体便形成一个路径,例如“(Avatar(m.obth54), film.film.release_date_s, film.film_regional_release_date.release_date, 2009-12-17)” 是一条路径,因此每个路径可以被添加到embedding table中。其向量表示为
,其中
是0-1向量,表示当前的路径的0-1编码。
则是embedding table,分式则表示归一化。
(2)答案上下文(Answer Context):这里有个符号为n-hop,表示中心实体所在子图的关系路径最大值。作者认为答案的上下文是一个对当前候选答案的一个有用的信息。作者取候选答案实体的1-hop子图作为上下文,并对其进行表征,向量为
(3)答案类型(Answer Type):往往有些问题对答案的类型是有针对性的。例如示例中的When明显是想要知道一个时间,对应知识库中的可能是一个时间字符串,而不是其他类型的实体。知识库中的实体已经提供了这些实体类型,因此仅需要为其进行表征即可,向量表达式为
。
最后,根据三个CNN提取的问句表示向量 和对应的答案表示向量 进行相似度计算并求和:
3.4 训练策略
基于排序的训练方法都是引入一个负样本,也就是负采样,本文负采样的方法是对每一个问句-答案对 都添加一个错误的答案 ,损失函数则可表示为 ,学过表示学习的知道, 表示最大值,m是一个threshold,即有假设: ,目标则是尽可能的使得 的得分高,使得负样本得分 更低,设置threshold 可以约束二者之间的最小距离。
最后考虑到一些问题的答案不是唯一的,因此才有这种策略进行预测:首先计算所有候选答案的得分,然后取最大值对应的答案作为最佳答案,其次依次对其他候选答案 进行降序排列,选出满足 的答案 。
四、总结
MCCNN可以算作基于NN的KB-QA开篇作之一,从模型上来讲,在当时可以算非常先进的。事实上利用相似度做问答系统的在现如今也很普遍。另外问答系统也是一种多标签任务,即每个问句可能会对应多个答案,因此采用这种基于得分函数的训练策略也是很有效的。不过该文章也存在一些问题:
(1)候选答案不一定在中心实体对应的2-hop范围内;
(2)不能解决带有逻辑判断的问题,例如who is the second …
(3)WebQuestion数据集的训练和测试集太少,容易造成过拟合问题;
