版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/pku_langzi/article/details/81196298
这是沈春华老师小组的一篇文章。
这篇文章的出发点是:目前的VQA问题,由于answer数量的有限性,因此转化为一种分类问题,但由于部分answer出现
的频次较低(比如上图中的黄瓜),为了提高整体的分类准确率,往往进行分类的时候,将频次低的answer进行舍弃,
如取answer出现频次高的top1000,。基于这种现象,本文提出Memory-Augmented Network来处理这样一种长尾效应。

方法简介
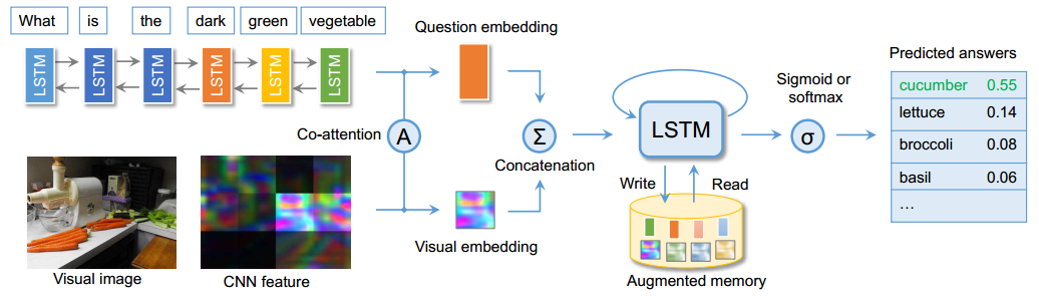
(1)对于图像与question的分别特征提取,并没有太多的新意,对于两种特征也采用了sequential co-attention机制,但
这种attention机制也是借鉴的NIPS2016中一篇VQA的方法。
(2)文章主打的Memory-Augmented network是在原来的memory network上进行改进,主要有两点别:其利用LSTM自
身特性,形成一种天然的internal memory其也设计了一种external memory,使得LSTM成为一种外部记忆机制的控制器
文章由于处理的问题是出现频次少的answer带来的长尾效应,因此主要落点放在了memory写机制的创新上,文中的写机
制能够在memory中极少用到的位置与经常用到的位置中达到一种平衡,来缓解长尾效应。具体实现细节,不再赘述,但
是这种memory的读写,既借鉴了操作系统内存的读写,又可与推理引擎中的working memory联系,又很好地利用深度
学习的记忆机制来实现,很有参考借鉴意义。
参考原文:Visual Question Answering with Memory-Augmented Networks