come from : https://www.cnblogs.com/lizheng114/p/7498328.html
前馈神经网络的弊端
前一篇文章介绍过MNIST,是采用的前馈神经网络的结构,这种结构有一个很大的弊端,就是提供的样本必须面面俱到,否则就容易出现预测失败。如下图:

同样是在一个图片中找圆形,如果左边为训练样本,右边为测试样本,如果只训练了左边的情况,右边的一定会预测错误,然而在我们人眼看来,这两个圆形的特征其实是一样的,不过是移动了一个位置而已,但是因为前馈网络结构的原因,导致在做权重分配的时候,把更多的权重分配给了左上角,右下角分配的较少,所以在做最终预测,便会出现较大的误差。所以,我们需要在图片中找出圆形的特征,即使是变换了位置,这些特征仍然是一样的,这样既减少了训练成本,又提升了训练的效率。就好像写代码把公共的部分封装起来复用一样。这个时候卷积神经网络就隆重登场了。
卷积神经网络(CNN)
根据前面的论述,我们发现,样本可以理解为是一个特征集,我们要找出这个特征集并过滤掉重复的特征,以提升训练的效率,降低成本。那么,我们如何来找寻图片中的各个特征呢?让我们来看看卷积神经网络的结构就可以明白了。
卷积神经网络一般由:卷积层,池化层,全连接层组成。其中卷积和池化会根据不同的需要来做多次。
在介绍这些结构之前,先要说一下图片是如何用矩阵来表达的。看如下代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
代码所表达的意思就是将m2.png转换为矩阵(去掉色彩信息),将矩阵输出到out.csv文件中,然后我们将csv文件打开后,看看对比效果,如下图:
 (csv文件)
(csv文件)
 (原图,50x50的png图片)
(原图,50x50的png图片)
csv文件中的数字表示的是每一个点的亮度,越靠近1越亮。如果是彩色图片,则每个点都包含了RGB三种颜色(因为色彩可以认为是RGB三种颜色叠加在一起来表达的),将会变为一个三维数组。
1、卷积层
卷积层主要是使用过滤器(filter)找寻样本特征的一个过程。过滤器,又叫kernel或者filter,是一个表示权重的矩阵,听名字就可以知道(卷积神经网络的卷积层)这一层非常重要。
由浅入深,我们先讨论只含有灰度信息的图片,也就是图片的深度为1,这样使用得filter就只含有w(宽)和h(高)。
一般我们会使用2x2,3x3,5x5等(一般来说,图片越大,采用的过滤器都会大一点)矩阵来与图片矩阵中相应位置的子矩阵做“点积”,如下图(为了看得清楚我使用的是20x20的png):
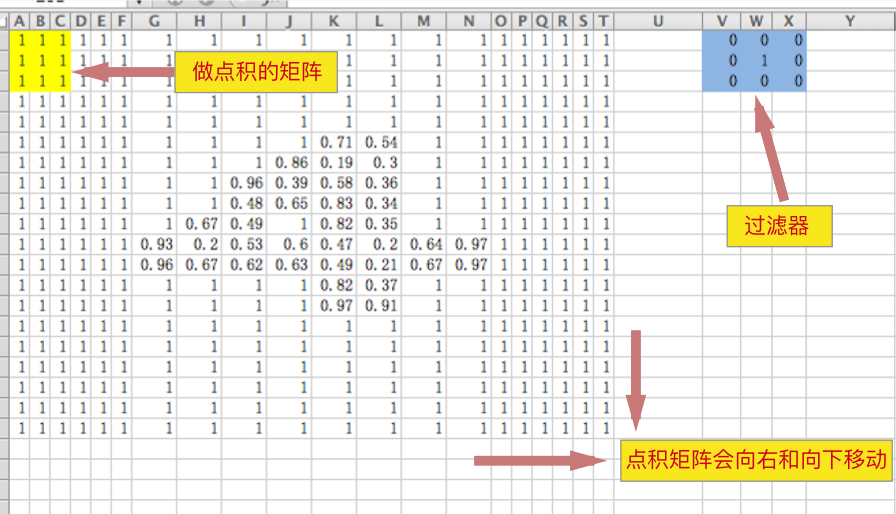
(注:矩阵的点积就是矩阵对应位置的元素做乘法,然后相加,例如上图黄色矩阵和蓝色矩阵做点积就是:1x0+1x0+1x0+1x0+1x1+1x0+1x0+1x0+1x0=1,这个1就是第一次卷积得到的矩阵的第一个元素的值)。
上图就是过滤器工作的方式,会向右以一定的步长来移动,到最右边以后,会以一定的步长(stride)来向下移动,直到整个图片结束。然后会得到一个新的矩阵,这个矩阵就是我们的特征矩阵。
所以,如果我们使用不同的过滤器(权重值不同)来对图片做卷积,就会得到图片不同的信息,比如:我如果使用
 这样的过滤器,就可以得到图片的边缘特征。所以,一般在卷积层,都会使用多个过滤器来采集图片的特征。
这样的过滤器,就可以得到图片的边缘特征。所以,一般在卷积层,都会使用多个过滤器来采集图片的特征。
这里有个链接可以观看不同过滤器卷积的过程。
{kind=link}
不难发现,如果是20x20的矩阵,采用3x3,步长为1的话,一次卷积过后,矩阵会变为:18x18,那么如果多几个卷积层,那图片岂不是要被卷没了?所以为了让卷积不改变图片大小,增加了zero padding(0填充)的概念,就是往图片的四周补0,这样就不会改变图片大小了。这里有一个公式来计算卷积以后图片的大小:
(input size - filter size + 2 * zero padding size) / stride + 1
现在我们来看看带有RGB的图片如何做卷积。图片带有了R、G、B三种颜色通道,就变为了20x20x3,那么相应的过滤器也要带有三个通道,所以之前的3x3,就变成了3x3x3,如下图:

三个权重数值可以不同,然后做点积,结果就是:
Xr0 * Wr0 + Xr1 * Wr1 + Xr2 * Wr2 + Xr3 * Wr3 + Xr4 * Wr4 + Xr5 * Wr5 + Xr6 * Wr6 + Xr7 * Wr7 + Xr8 * Wr8 +
Xg0 * Wg0 + Xg1 * Wg1 + Xg2 * Wg2 + Xg3 * Wg3 + Xg4 * Wg4 + Xg5 * Wg5 + Xg6 * Wg6 + Xg7 * Wg7 + Xg8 * Wg8 +
Xb0 * Wb0 + Xb1 * Wb1 + Xb2 * Wb2 + Xb3 * Wb3 + Xb4 * Wb4 + Xb5 * Wb5 + Xb6 * Wb6 + Xb7 * Wb7 + Xb8 * Wb8 +
B(偏置量)
所以其实卷积最后得到的矩阵是:20x20。
经过卷积之后的矩阵,要做ReLU变换来增强拟合能力,ReLU可以保证得到的矩阵所有元素的取值都大于0。
2、池化层
在卷积过后,我们要将结果进行池化,池化层的目的就是为了降低不必要的冗余信息(downsampling),有两种池化操作:求最大和求平均,一般都采用求最大值得方式。
选取一个2x2的filter,然后将卷积后的矩阵分割为不同的块,选取步长为2,然后将里面的最大值取出来得到一个新的矩阵的过程,就是最大池化操作,如图:
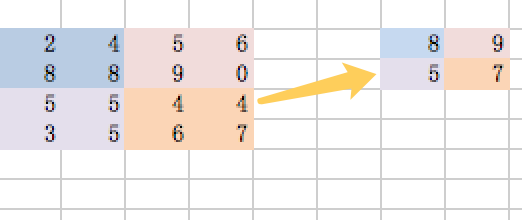
那么,我们不禁会问,将其中的一些值舍弃掉,只留最大值,对判定结果有没有影响?
答案是会有一定影响,但是影响会比较小,因为选择的过滤器比图片本身要小很多,那经过过滤器筛选出来的特征本身也是很小的局部特征,而这些特征中,经过权值计算,权值比较小的值则表明对该局部特征的影响比较小,所以只保留影响最大的最大值,这样既能减少矩阵大小,而又不会对预测结果产生太大影响。
3、全连接层
即是将所有特征组合在一起组成一个一维数组的过程。
总体
至此,卷积神经网络的主要层级功能都介绍完毕了,我们来看看一种卷积神经网络的整体结构,如下图:
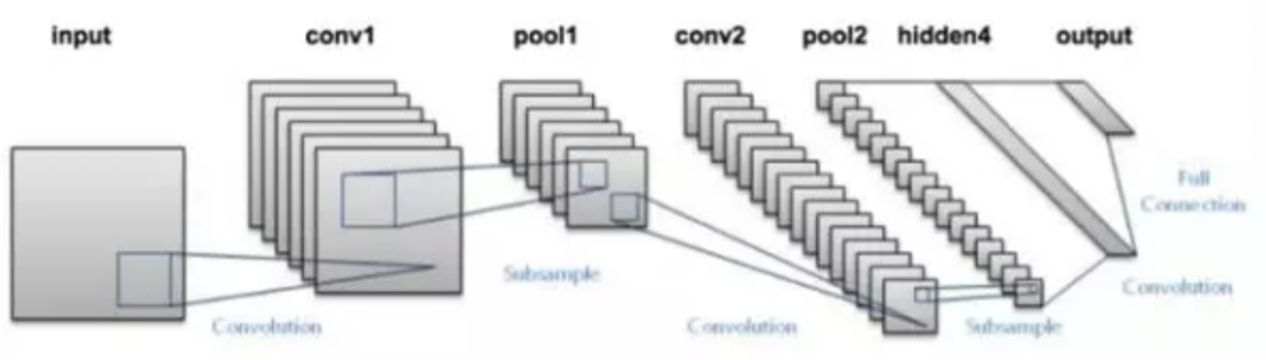
它采用了两个卷积层,两个池化层,一个全连接层来表达。
目前比较流行的卷积网络的结构有:
LeNet(1990年诞生的第一个成功的卷积神经网络的模型)、AlexNet、ZFNet、GoogLeNet、VGGNet、ResNet等,感兴趣的朋友可以自行搜索一下。
TensorFlow的官方例子
TensorFlow在对MNIST的图片集上采用了卷积神经网络来做图形识别,代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 |
|
代码比较清楚,就不过多讲述了,基本就是:卷积->池化->卷积->池化->全连接->dropout->全连接->训练->测试。
注意到代码中的:with tf.name_scope('xxx'): 是在构建计算图,看其中的代码:
| 1 2 3 4 |
|
是将计算图存储下来,打印出路径,我们找到相应的路径以后,在命令行中执行:

将地址复制到Chrome中,点击Graph标签,就可以看到计算图了。
上面的代码都跟是遵循我们之前介绍的卷积网络的卷积层,池化层,全连接层来组成的,其中多了一个dropout,如下:
| 1 2 3 |
|
dropout的目的是为了防止产生过拟合的问题,这里解释一下过拟合和欠拟合。
过拟合(overfitting):当某个模型在经过训练后,过度的学习了训练集的噪音和干扰项,从而导致在测试集上表现很差,但是在训练集上表现很好,就称为过拟合。
欠拟合(underfitting):值模型无论在测试集还是训练集上表现都不好,也就是说训练样本不够。
那么dropout如何来避免这些噪音的影响呢?通常做法是随机的将某些特征的权值置为0。
详细解释看这里:https://yq.aliyun.com/articles/68901
常见问题
1、官网的例子filter为什么要选32个?filter size为什么要选5x5?stride为什么要选2?
网上有人说是因为这些数字到底选多少是一门艺术和经验的总结。
2、在做卷积的时候,为什么可以使用同一个filter(权重矩阵),而不是每移动一步就换一个矩阵?
因为filter的作用在于将图片中的某一类特征卷积出来,将符合条件的特征都筛选出来。所以可以共享权值矩阵。
3、全连接层到底是做什么的?有什么用?
将之前的结果,例如官网例子中的第二轮pool2的结果 7x7x64,通过跟乘以权重矩阵(W),得到1024个元素的一维数组的过程。就跟之前讲MNIST一样,我们就是要通过训练来得到这个W的各个元素的值。这个值会影响预测结果。
4、卷积网络如何保证特征不变性(同样的特征不因位置改变而改变)?
因为对同一个图片来说,在同一深度同一卷积层下,权值是共享的,也就是说,相同的特征会被统一识别出来而不需要再次学习。
参考文章:
https://www.zhihu.com/question/39022858
http://cs231n.github.io/convolutional-networks/#case
http://www.sohu.com/a/132394579_714863
标签: TensorFlow, CNN, 深度学习, Deep Learning, 卷积神经网络