CNN卷积神经网络之VGGNet
前言
《Very Deep Convolutional Networks for Large-Scale Image Recognition》
论文地址: https://arxiv.org/abs/1409.1556.
该网络是在ILSVRC 2014上的相关工作,ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet),2015年发表到ICLR。主要贡献是使用很小的卷积核(3×3)构建各种深度的卷积神经网络结构,16-19层的网络深度能够取得较好的识别精度。 这就是常用的VGG-16和VGG-19。
网络结构
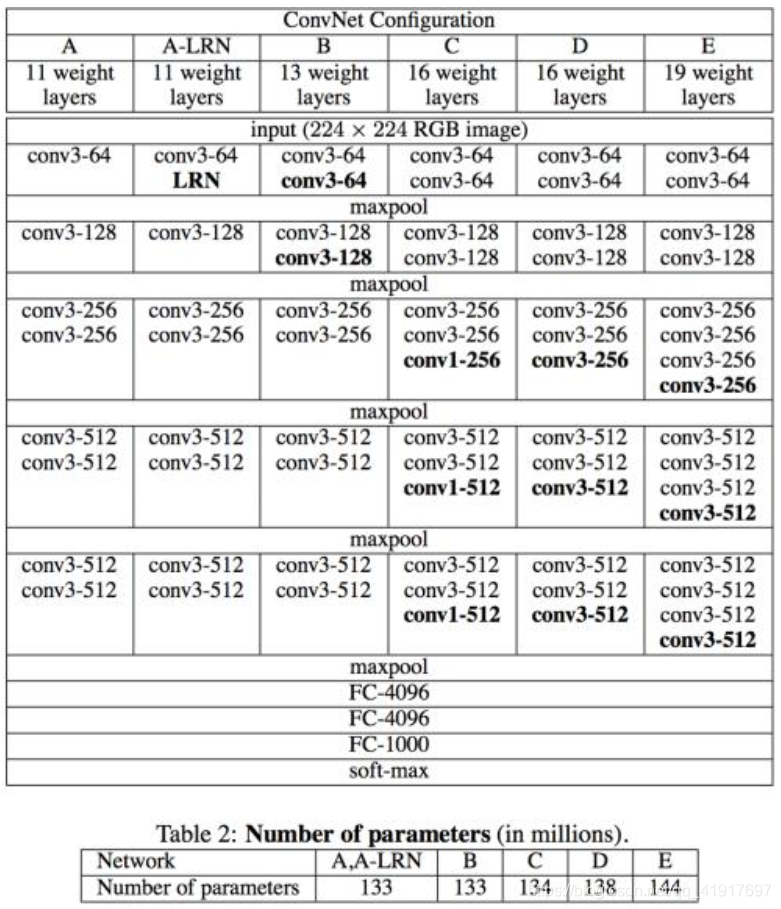
输入是大小为224*224的RGB图像,预处理时计算出三个通道的平均值,在每个像素上减去平均值。全连接层后是Softmax,用来分类。所有隐藏层的conv层中间都使用ReLU作为激活函数。连续的卷积后面接最大池化。在FC层中间采用dropout层,防止过拟合。
VGG在训练的时候先训A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,可加快训练。
运用的方法
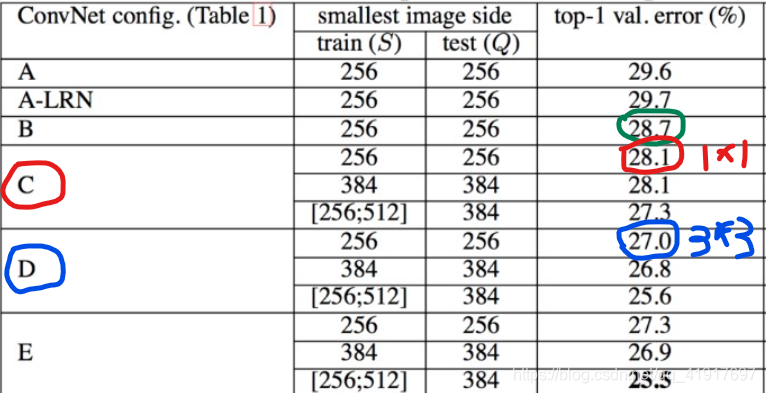
1.多尺度训练
训练采用多尺度训练(Multi-scale),将原始图像缩放到不同尺寸 S,然后再随机裁切224*224的图片,并且对图片进行水平翻转和随机RGB色差调整。
论文中使用了两种方法:
(1) 固定最小边的尺寸为256;
(2) 随机从[256,512]的确定范围内进行抽样,这样原始图片尺寸不一,有利于训练,这个方法叫做尺度抖动(scale jittering),有利于训练集增强。
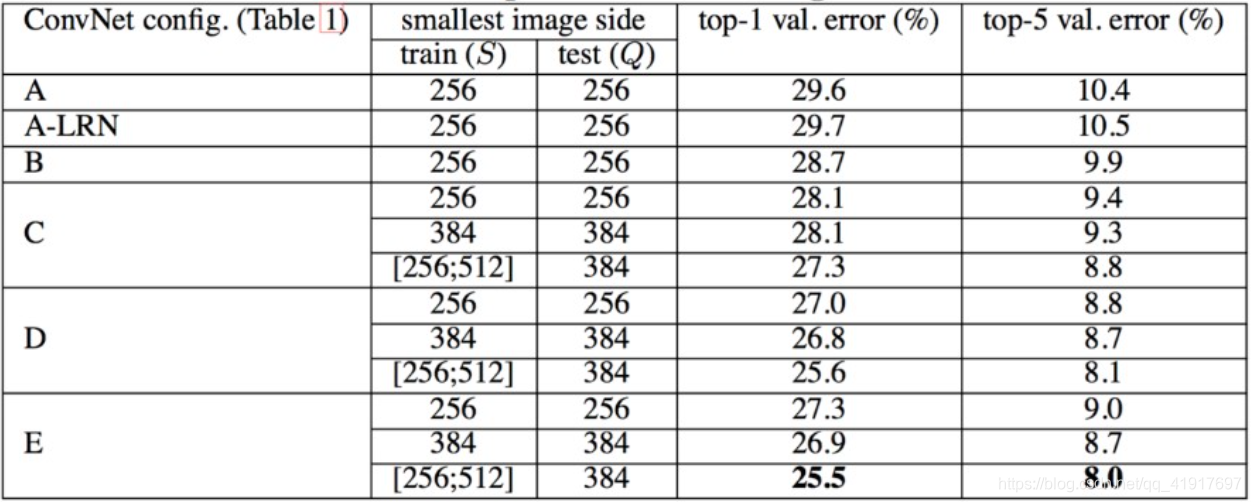
结论:网络的性能随着网络的加深而提高。当网络层数达到19层时,使用VGG架构的错误率就不再随着层数加深而提高了。训练时的尺寸抖动的结果好于固定尺寸。
2.稠密和多裁剪图像评估对比
Dense(稠密评估),即指全连接层替换为卷积层(第一FC层转换到7×7卷积层,最后两个FC层转换到1×1卷积层),最后得出一个预测的score map,再求平均。可参考 OverFeat的全卷积部分。
multi-crop(多裁剪图像评估),即对图像进行多样本的随机裁剪,将得到多张裁剪得到的图像输入到网络中,最终对所有结果平均。
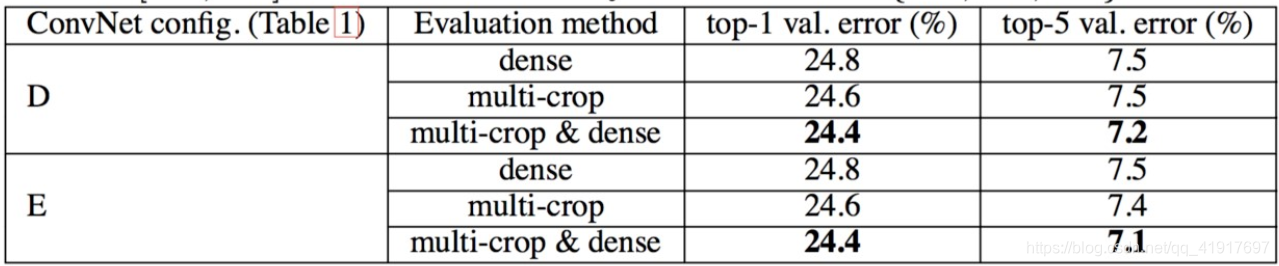
可以看出,多裁剪的结果是好于密集估计的。而且这两种方法是互补的,它们的组合会更加好。
3.小卷积核和连续的卷积层*
VGGNet全部使用3x3(or 1x1)的卷积核和2x2的最大池化。两个3x3卷积层的串联相当于1个5x5的卷积层,3个3x3的卷积层串联相当于1个7x7的卷积层,即3个3x3卷积层的感受野大小相当于1个7x7的卷积层。但是3个3x3的卷积层参数量只有7x7的一半左右,同时可以增加非线性。前者可以有3个非线性操作,而后者只有1个非线性操作,这样使得学习能力更强。
使用1x1的卷积层来增加线性变换,输出的通道数量上并没有发生改变。
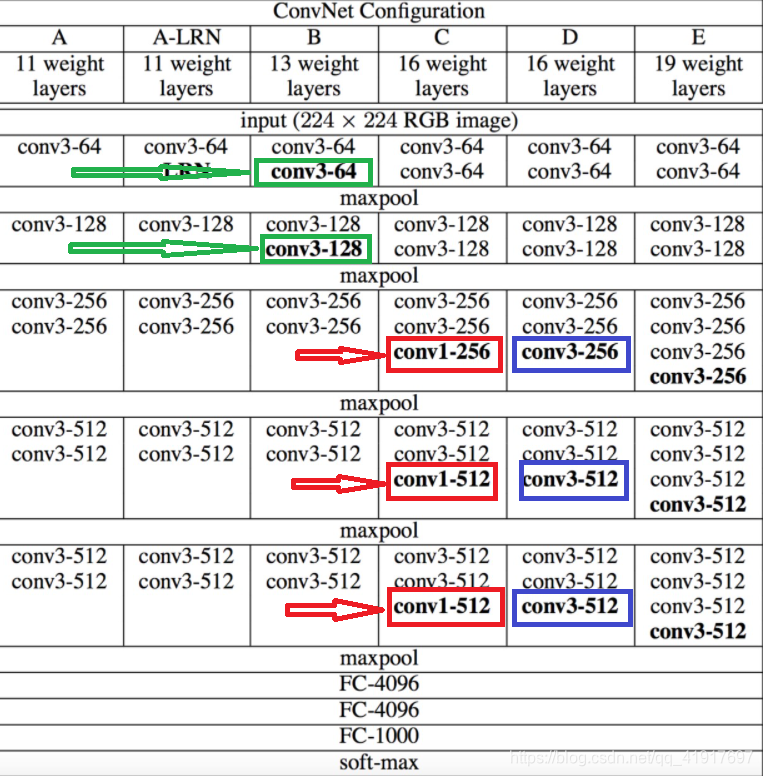
可见 1x1的卷积也是很有效的,但是没有3x3的卷积效果好,因为3x3的网络可以学习到更大的空间特征。
4.dropout
并非首次提出,不在赘述。
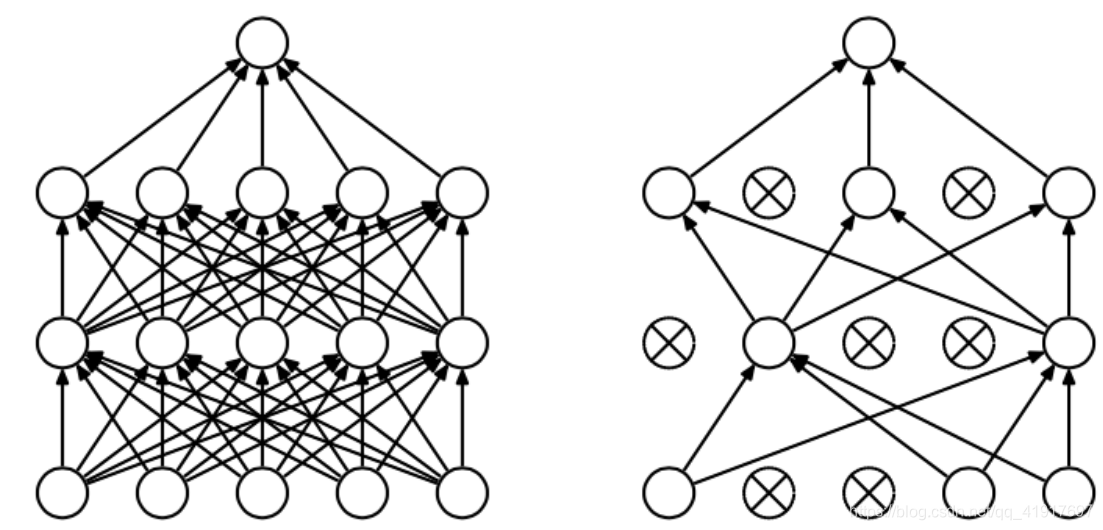
(1)达到了一种模型融合的作用。相当于对多种网络结构进行了优化,预测时又取了平均,因此可以较为有效地防止过拟合的发生。
(2)减少神经元之间复杂的共适应性。有些特征可能会依赖于固定关系的隐含节点的共同作用,而通过dropout的话,增加了神经网络的鲁棒性。
5.尺寸大小和通道数

利用pooling下采样,随着层数的增加,图像尺寸越来越小,通道数成倍增加。
总结
1)在训练时,可以使用多尺度抖动的训练图像,其精度好于固定尺寸的训练集。测试时,使用多裁剪和密集评估(卷积层替换全连接层)相结合的方法。
2)VGG的结构非常简洁规整,整个网络都使用了同样大小的卷积核尺寸和最大池化尺寸。几个小滤波器卷积层的组合比一个大滤波器卷积层好!!
3.验证了通过不断加深网络结构可以提升性能。
4.VGG耗费更多计算资源(卷积操作更多),并且使用了更多的参数(全连接层)。有些研究称:这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。(有空我会亲自验证一下)
5.尺寸越来越小,通道数越来越大。