CNN卷积神经网络之ConvNeXt
前言
《A ConvNet for the 2020s》
论文地址:https://arxiv.org/abs/2201.03545
pytorch代码:https://github.com/facebookresearch/ConvNeXt
最近Transfomer在CV领域大放异彩,颇有一种要碾压CNN的气势。但是作者觉得,CNN并没有过时,只是需要改进一下结构,借鉴Swin-T的结构设计思路来重新改进CNN。作者将所提出的卷积网络结构ConvNeXt称为“2020年代的卷积网络”,将2010年代的网络进行了提升。
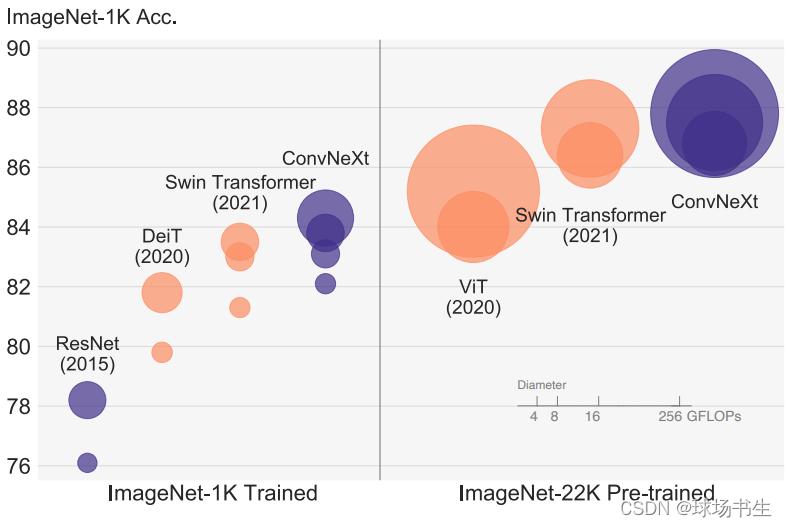
左边是img_size=224,右边是img_size=384。
改进内容
改进的思路就是对Transformer的trick进行梳理和模仿,而且没有引入任何注意力机制模块,把ResNet50从76.1一步步提到82.0。这里是考虑到两个模型大小的FLOPs,一个是ResNet50/Swin-T区间,FLOPs约4.5×109,另一个是ResNet200/ Swin-B区间,FLOPs约15×109。为了简单起见,我们将用ResNet50/Swin-T复杂度模型给出结果。高容量模型的结论是一致的。
探索的路线图如下:

1 训练技巧
我们的出发点是ResNet,首先使用类似的训练技术训练它,获得更高的基线。这种增强的训练方法将ResNet-50模型的性能从76.1%提高到了78.8%(+2.7%),这意味着传统ConvNet和视觉Transformer之间的性能差异很大一部分可能是由于训练技术。之后将使用相同的超参数训练ResNet-50,准确度都是从三个不同的随机种子训练中获得的平均值。

layerscale是给不同通道乘上一个可学习参数λ
2 宏观设计

- stage的比例:众所周知resnet50有4个由若干个block堆叠出的stage,每个stage的block数量不太相同,作者将堆叠次数按照Swin-T来设计,

- “patchify” stem:将stem更改为Patchify。

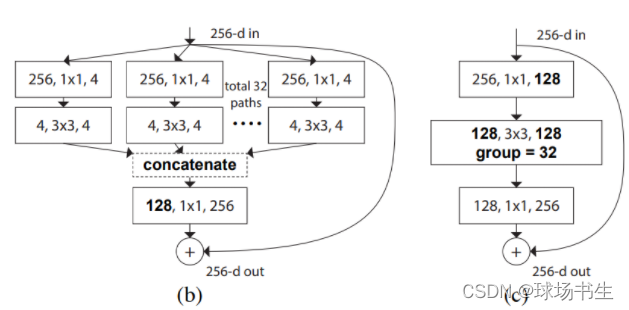
3 ResNeXt-ify

这一部分中,尝试采用ResNeXt的思想。核心部分是分组卷积,其中卷积滤波器被分成不同的组。在高层次上,ResNeXt的指导原则是“使用更多组,扩大宽度”。更准确地说,ResNeXt对瓶颈块中的3×3 conv层采用分组卷积。这里使用深度可分离卷积大大减少了FLOPs,降低了精度。按照ResNeXt中提出的策略(网络宽度被扩展以补偿容量损失),我们将网络宽度增加到与Swin-T相同的信道数(从64个增加到96个)。这将使网络性能达到80.5%,并增加了FLOPs(5.3G)。

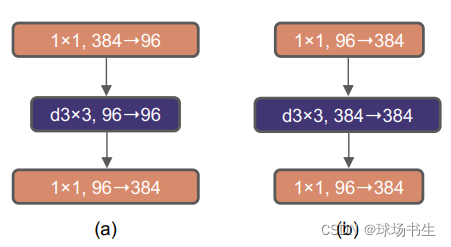
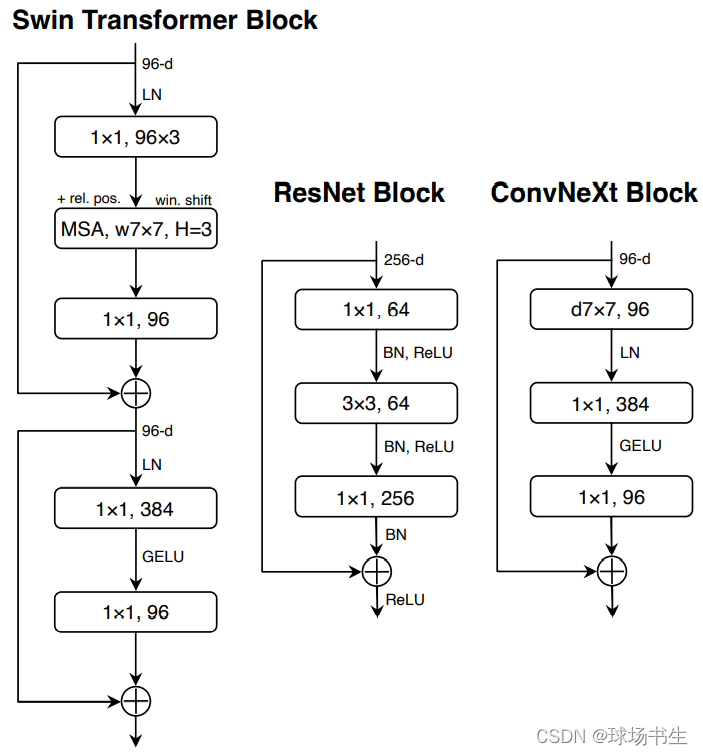
4 Inverted Bottleneck

resnet里block的设计是先1x1卷积降维,之后再用1x1卷积升维,形成一个瓶颈层。而Transformer块的一个重要设计是,它会产生一个反向瓶颈(b),即MLP块的隐藏尺寸比输入尺寸宽四倍:
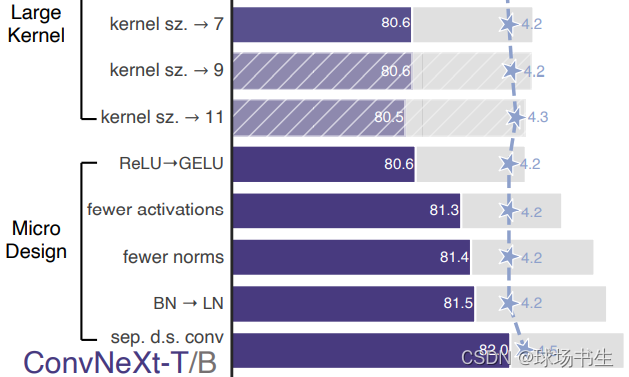
5 Large Kernel Sizes
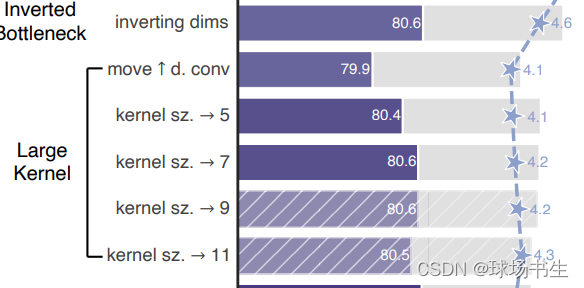
由于Swin-T中使用了7x7的窗口,为了对齐比较作者也打算采用大卷积核。但又因为inverted bottleneck放大了中间卷积层的缘故,直接替换会导致参数量增大,因而作者把dw conv的位置进行了调整,放到了反瓶颈的开头。最终结果相近,说明在7x7在相同参数量下效果是一致的。(其实就是作者认为自注意力层可以和DW Conv等价,用dw conv 7×7替换MSA)

- 向上移动dw conv:这个中间步骤将FLOPs减少到4.1G,导致性能暂时降低到79.9%。
- 增加核大小:采用更大的核大小的卷积的好处是显著的。
6 细节设计
-
用GELU替换ReLU:
ReLU在原始Transformer中也用作激活函数。高斯误差线性单位GELU,可以被认为是ReLU的一个更平滑的变体,在最先进的Transformer中使用以及最近的ViTs。我们发现在ConvNet中,ReLU也可以用GELU替代,但准确率保持不变(80.6%)。 -
更少的激活功能:
Transformer和ResNet块之间的一个小区别是Transformer的激活功能较少。如图所示,我们消除了剩余块中的所有GELU层,除了两个1×1层之间的一层,复制了Transformer块的样式。这一过程将结果提高了0.7%至81.3%。现在,我们将在每个区块中使用一个GELU激活。
-
更少的标准化层:
Transformer块通常也有较少的规范化层。在这里,我们移除了两个BatchNorm层,在conv 1×1层之前只留下一个BN层。这进一步将性能提升到81.4%。请注意,这里每个块的标准化层比Transformers更少,因为根据经验,我们发现在块的开头添加一个额外的BN层并不能提高性能。 -
用LN代替BN:
BatchNorm是ConvNets中的一个重要组成部分,因为它提高了收敛性,减少了过度拟合。然而,BN还有许多复杂之处,可能会对模型的性能产生不利影响,但BN仍然是大多数视觉任务的首选选项。另一方面,更简单的层规范化(LN)已在Transformer中使用,从而在不同的应用场景中获得了良好的性能。在原始ResNet中直接用LN代替BN将导致次优性能。在对网络架构和训练技术进行修改后,在这里重新使用LN代替BN,性能稍好一些,准确率为81.5%。 -
分离下采样层:

在ResNet中,空间下采样是通过在每个阶段中使用步幅2的卷积实现的。而在SwinTransformer中,在stage之间有单独的下采样层。因此,作者使用2×2 conv层和步长2的卷积进行空间下采样。进一步的研究表明,在空间分辨率发生变化的地方添加归一化层有助于稳定训练。准确度提高到82.0%,大大超过Swin-T的81.3%。
网络结构
ResNet-50、SWN-T和ConvNeXt-T的详细架构比较见表:



实验结果
图像分类:

目标检测:COCO object detection and segmentation results

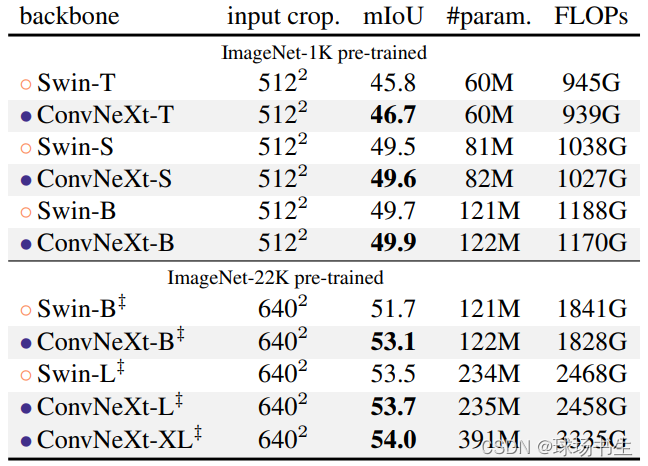
分割:ADE20K validation results
上一篇:Swin-Transformer