CNN卷积神经网络之ResNet
未经本人同意,禁止任何形式的转载!
前言
《Deep Residual Learning for Image Recognition》
论文地址:https://arxiv.org/pdf/1512.03385.pdf.
2014年VGG达到19层,GoogLeNet达到22层,就算是15年Incepetion V2 42层,V3 44层,但resnet能达到数百上千层。resnet的提出始于2015年,在ILSVRC 2015夺得冠军。
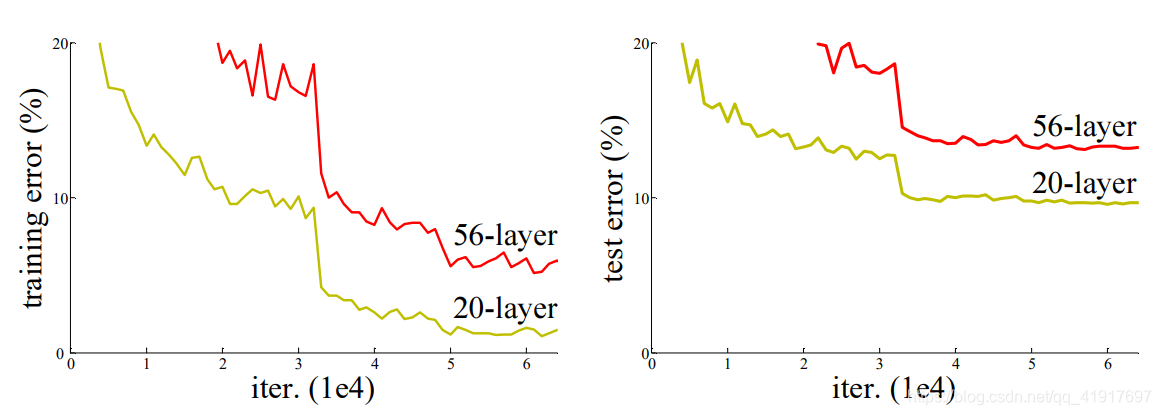
神经网络的“退化”问题
随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大(但这并不是过拟合,因为在过拟合中训练loss是一直减小的)。当网络退化时,浅层网络比深层网络效果更好。
梯度弥散/爆炸成为训练深层次的网络的障碍,导致无法收敛。虽有一些方法可以弥补(合适的初始化,输入归一化)但深层网络却还是开始退化了,即增加网络层数却导致更大的误差。这是个优化问题,且难度的增长并不是线性的,越深的模型越难以优化。
残差块(Residual Block)
如果堆积层降低了网络性能,那么我可以选择不要新堆积的层,按照这个思路,较深的模型所产生的训练误差不应该比较浅的模型高才对。Resnet设计了identity mapping和residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被尽量优化为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
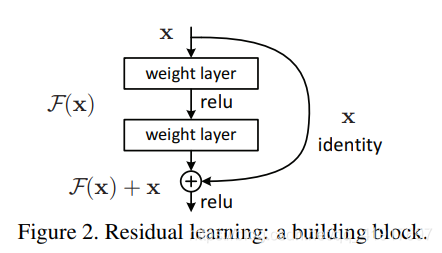
如果期望的潜在映射为H(x),与其让F(x) 直接学习H(x)映射,不如学习残差H(x)−x,即F(x):=H(x)−x,这样原本的前向路径上就变成了F(x)+x,用F(x)+x来拟合H(x)。作者认为这样可能更易于优化,因为相比于让F(x)学习成恒等映射,让F(x)学习成0要更加容易。这样,即使网络加深,对于冗余的block,只需F(x)→0就可以得到恒等映射,性能不减。
⊕ 为element-wise addition,要求参与运算的F(x)和x的尺寸要相同。
网络结构

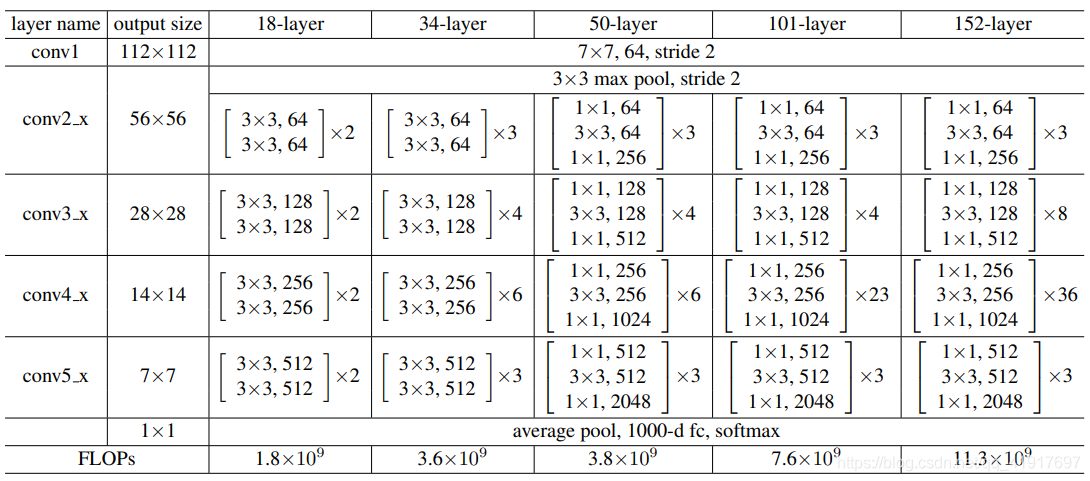
ResNet用 average pool 代替全连接,这点跟Incepetion想得一致,节省大量参数。降采样是通过conv的stride=2实现的。此外,可见模块化的设计从VGGNet开始已经深入人心。
随着网络变得复杂(ResNet-50/101/152),为进一步减少参数,利用1x1卷积核进行降维,下面右图的bottleneck结构。第一个1x1的卷积把channel降维,然后在最后通过1x1卷积恢复channel数。
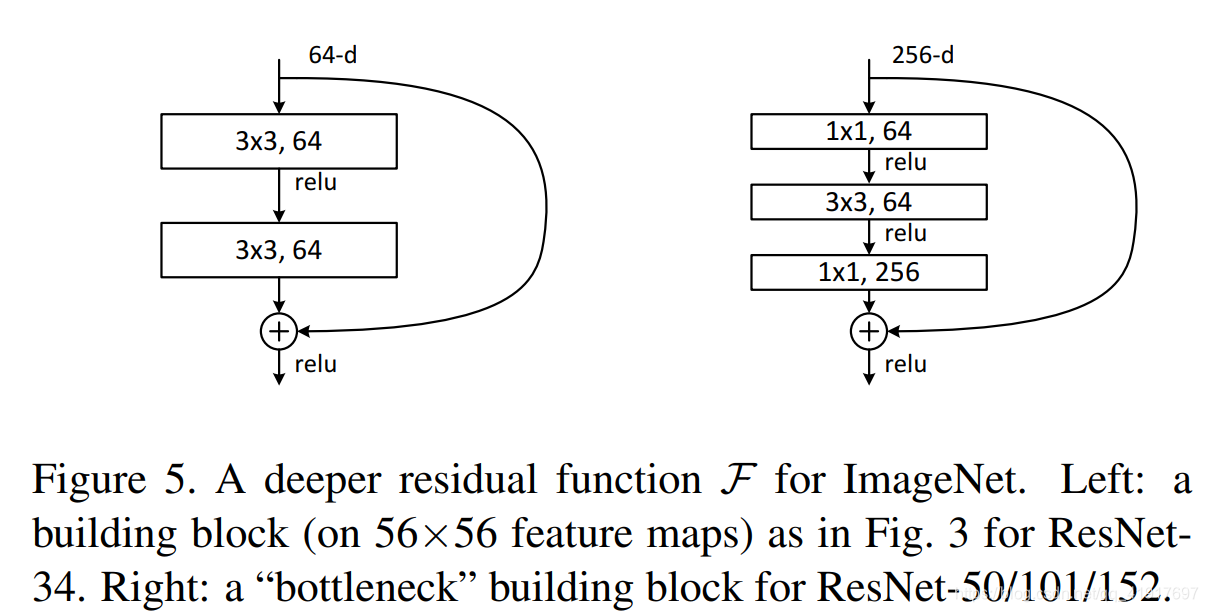
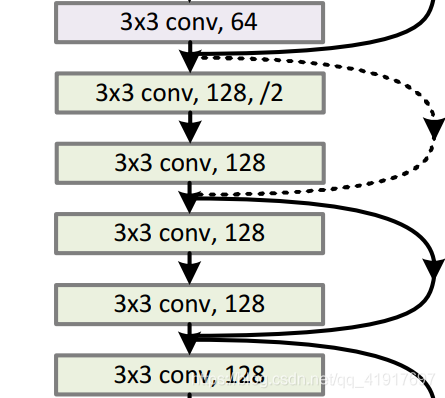
注意:当F(x)和x的通道数不同时,虚线连接部分(在每个channel数改变的第一个残差块),采用计算方式:y=F(x)+Wx。即shortcut connection会进行一次1x1卷积给通道降维。
Residual Block之间的衔接,在原论文中,F(x)+x经过ReLU后直接作为下一个block的输入x。

Residual Block的分析与改进*
《Identity Mappings in Deep Residual Networks》
论文地址:https://arxiv.org/abs/1603.05027.
这是16年,原作者Kaiming He对网络进行的进一步分析和改进。
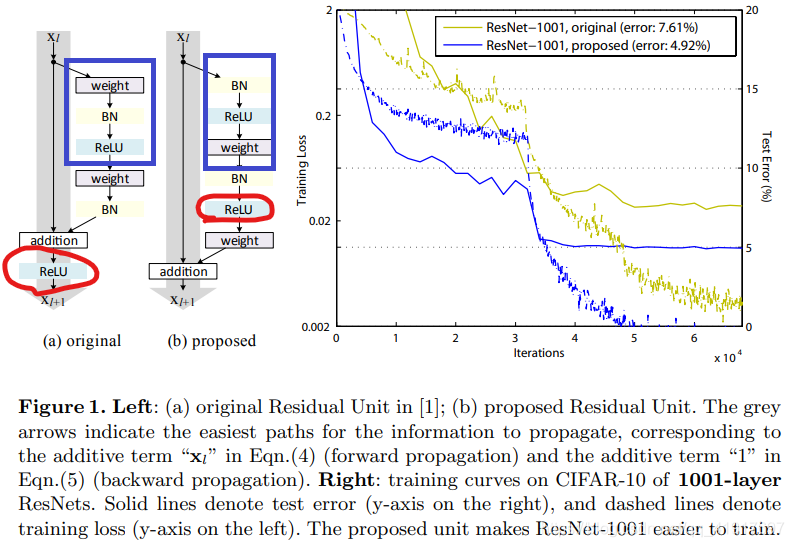
可见,新Residual Block结构具有更好的性能,能更好地避免“退化”,堆叠大于1000层后,性能仍在变好。
这里将shortcut路径视为主干路径,将残差路径视为旁路。通过保持shortcut路径的“干净”,可以让信息在前向传播和反向传播中平滑传递(论文中有做过实验对比)。因此,尽量不在主干路径引入1×1卷积等操作,同时将路径上的ReLU移到F(x)路径上。在残差路径上,将BN和ReLU提前(full pre-activation),获得了“Ease of optimization”以及“Reducing overfitting”的效果。

在卷积之后使用激活函数的方法叫做post-activation。作者通过调整ReLU和BN的使用位置得到了几个变种,通过对照试验对比这几种变异模型。实验结果也表明将激活函数移动到残差部分可以提高模型的精度。
res_block_v2顺序:#伪代码
res_x = BatchNormalization(x)
res_x = ReLU(res_x)
res_x = Conv2D(kernel_size=(3,3), x)
理解与反思
我一直试图从各个角度考虑Residual Block所带来的作用,仅仅将个人的想法写出来分享,抛砖引玉,希望有更好的理解可以留言,相互交流。
1)网络的层数对网路的性能有至关重要的影响,因此通过shortcut connection让网络自己来学习所需要的层数(如果网络已经到达最优,继续加深网络,residual mapping将被尽量优化为0,只剩下identity mapping,这样理论上网络一直处于最优状态了)。
2)也可以从模型集成的角度理解残差网络。
3)反向传播过程中,由链式法则得到梯度累乘,以往堆叠的网络很有可能发生梯度爆炸(λi>1)或者梯度变成0(λi<1),会阻碍残差网络信息的反向传递,从而影响残差网络的训练。常见的激活函数都容易产生类似的阻碍信息反向传播的问题。

利用残差网络,可以避免shortcut路径上的梯度消失和爆炸。shortcut路径将反向传播由连乘形式变为加法形式,梯度能更好的传到前面得到更新。
4)网络原本是让F(x) 直接学习H(x)映射,现在学习残差H(x)−x,即F(x):=H(x)−x。假设原本拟合的是H(x)=100,H’(x)=105的偏差只有5%。然而,如果去拟合H(x)−x=0,F’(x)=5的偏差却是100%,网络对于误差变得更加敏感,所以让F(x)学习成0要更加容易。
上一篇:CNN卷积神经网络之GoogLeNet(Incepetion V1-Incepetion V3).
下一篇:CNN卷积神经网络之Inception-v4,Inception-ResNet.