-
逻辑回归与线性回归的联系与区别
第一条:回归模型就是预测一个连续变量(如降水量,价格等)。在分类问题中,预测属于某类的概率,可以看成回归问题。这可以说是使用回归算法的分类方法。
第二条:直接使用线性回归的输出作为概率是有问题的,因为其值有可能小于0或者大于1,这是不符合实际情况的,逻辑回归的输出正是[0,1]区间。线性回归只能预测连续的值,分类算法是输出0和1.
第三条:线性回归中使用的是最小化平方误差损失函数,对偏离真实值越远的数据惩罚越严重;逻辑回归使用对数似然函数进行参数估计,使用交叉熵作为损失函数,对预测错误的惩罚是随着输出的增大,逐渐逼近一个常数 -
逻辑回归的原理
逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
第一步:构建预测函数
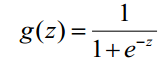
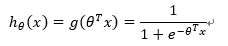
函数h(x)的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
P(y=1│x;θ)=h_θ (x)
P(y=0│x;θ)=1-h_θ (x)
第二步 :构建损失函数
基于最大似然估计推导:
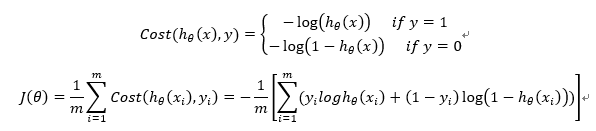
第三步:使用梯度下降或者向量法求最小损失函数和θ -
逻辑回归损失函数推导及优化
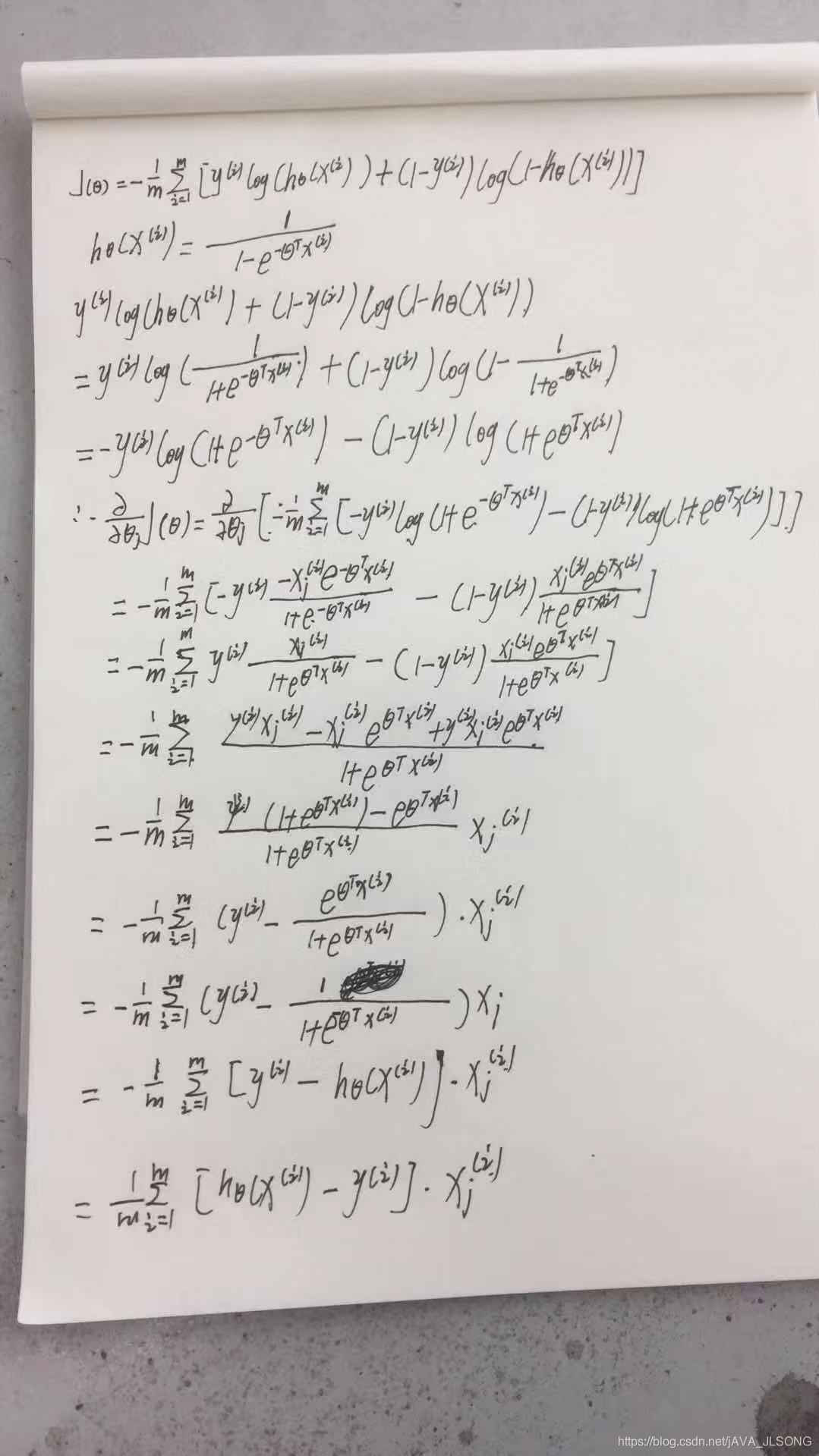
优化方法:共轭梯度,局部优化法,有限内存局部优化法
4.正则化与模型评估指标
L2正则化:
在原来的损失函数基础上加上权重参数的平方和:
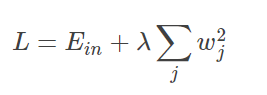
Ein 是未包含正则化项的训练样本误差,λ 是正则化参数,可调。对Ein进行最小化求解。
L1正则化:
在原来的损失函数基础上加上权重参数的绝对值:
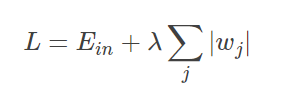
求解最小化Ein
模型评估指标:
回归模型的评估:
平均均方误差mse
MSE=1n∑(y¯−yi)2=Var(Y)MSE = \frac{1}{n}\sum(\bar{y}-y_i)^2 = Var(Y)
拟合优度Goodness of fit
拟合优度(Goodness of Fit)是指回归直线对观测值的拟合程度。度量拟合优度的统计量是可决系数(亦称确定系数)R^2.
最大值为1。R^2
的值越接近1,说明回归直线对观测值的拟合程度越好;反之,R^2的值越小,说明回归直线对观测值的拟合程度越差。
-
逻辑回归的优缺点
Logistic 回归是一种被人们广泛使用的算法,因为它非常高效,不需要太大的计算量,又通俗易懂,不需要缩放输入特征,不需要任何调整,且很容易调整,并且输出校准好的预测概率。与线性回归一样,当你去掉与输出变量无关的属性以及相似度高的属性时,logistic 回归效果确实会更好。因此特征处理在 Logistic 和线性回归的性能方面起着重要的作用。
Logistic 回归的另一个优点是它非常容易实现,且训练起来很高效。在研究中,我通常以 Logistic 回归模型作为基准,再尝试使用更复杂的算法。
由于其简单且可快速实现的原因,Logistic 回归也是一个很好的基准,你可以用它来衡量其他更复杂的算法的性能。
它的一个缺点就是我们不能用 logistic 回归来解决非线性问题,因为它的决策面是线性的、
-
样本不均衡问题解决办法
样本的过采样和欠采样。
使用多个分类器进行分类。
将二分类问题转换成其他问题。
改变正负类别样本在模型中的权重。
7.sklearn参数
n_neighbors:默认为5,就是k-NN的k的值,选取最近的k个点。
weights:默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。
algorithm:快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
leaf_size:默认是30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。
metric:用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)。p:距离度量公式。在上小结,我们使用欧氏距离公式进行距离度量。除此之外,还有其他的度量方法,例如曼哈顿距离。这个参数默认为2,也就是默认使用欧式距离公式进行距离度量。也可以设置为1,使用曼哈顿距离公式进行距离度量。
metric_params:距离公式的其他关键参数,这个可以不管,使用默认的None即可。
n_jobs:并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作