GENDA: A Graph Embedded Network Based Detection Approach on encryption algorithm of binary program [JISA 2022]
Xiao Li School of Information Science and Technology, Northwest University, Xi’an, China
Yuanhai Chang School of Information Science and Technology, Northwest University, Xi’an, China
密码技术在软件保护中广泛应用, 如何高效检测软件中使用的加密算法在评估软件保护强度方面是一个有价值且关键的任务. 但是现有的加密算法识别方法面临高误报率和低效率等问题, 因为这些方法通常不能完全提取加密算法的程序结构和语义特征. 在本文中, 作者提出一种名为GENDA的模型, 基于图嵌入网络的二进制代码中加密算法识别. 首先分析各类加密算法的特性并构建程序图(program graph), 然后以程序图作为基本单位递归地嵌入图神经网络中, 并以向量表示相应的加密算法图, 最后根据向量之间的距离决定加密算法类型. 在开源代码库和实际应用的加密算法识别上, GENDA的准确率可以达到92%, 在和SOTA的比较中可以超过大部分方法.
一句话: 图嵌入网络做加密算法识别
导论
Contributions
本文的一个重要贡献是实验验证了用神经网络检测加密算法的可行性。利用这一优势,深度学习神经网络可以端到端进行训练,将复杂的二值分析任务转化为只需要少量领域知识的训练任务。通过将加密算法视为具有特殊性质的代码,将该问题转化为二进制代码相似度检测问题。本文的贡献如下:
(1) 利用基于图神经网络的检测模型对加密算法进行识别是国内最早的研究之一。为了构建检测模型,将加密算法图结构嵌入到向量结构中。该嵌入网络可以接触基本块节点之间的特征。最后,形成一个包含加密算法图全部信息的向量结构,通过比较加密函数向量之间的距离来确定加密算法的类型。
(2) 它提供了一种构造加密算法图的新方法。为此,GENDA利用逆向工具提取函数单元中的函数流程图信息,并将其与汇编指令操作码、操作数相结合,得到新的结构、加密算法图作为深度学习神经网络的基本嵌入单元,从而保证在训练过程中获得更好的结果。
(3) 它利用从开放源码程序和现有方法收集的数据集进行广泛的评估。实验结果表明,与现有方法相比,GENDA算法能够达到较好的综合性能。
Related Works
(1) Cipher text based encryption detection
对加密算法的识别主要来自于用该方法对加密后的密文进行分析。Souza等人[16]的方法在EBC和CBC模式下进行了基于无监督学习的分组密码分类和聚类。在EBC模式下,分类和聚类准确率可以达到100%。不幸的是,在CBC模式下分类失败。为了解决这一问题,Shivendra等[17]发明了一种将块长度、流量检测、熵再现分析与决策树相结合的方法,发现密文在AES中是均匀分布的。他们完成了密文案例的随机输入。Vina等[18]将机器学习应用于密文加密检测进行差分和线性分析,并根据语义信息恢复对加密方法进行了分析。Vikas等人[19]提出通过聚类技术单独分析密文来识别密码算法。
(2) Binary based encryption algorithm detection
反编译技术是目前加密算法识别的主流方法。该方法可以有效地分析目标加密算法是否包含在二进制码中。目前,该领域的分析主要集中在分组加密算法的传播、评估和测试标准和方法上,根据识别方法可分为静态分析和动态分析。Li等[20]利用贝叶斯分类模型速度快、空间开销小的特点,利用装配级加密算法向量构建贝叶斯决策识别模型,对加密算法进行了有效的分析,但精度仍有待提高。Tieming等人[21]通过匹配标记词来识别加密算法。虽然识别效率高,但识别的虚警率难以被接受。为了解决这一问题,也有工作通过检测比特操作指令[22]、信息熵[23]来判断是否使用了加密算法。基于静态分析的检测方法易于实现,性能良好。然而,使用未知特征的加密算法很难检测出来。
(3) Encryption algorithm detection based on deep learning
深度学习正在成为一种有前途的技术,用于构建预测模型,以支持与代码相关的任务,如性能优化和代码漏洞检测[28,29]。为了实现可扩展性和高精度,一些研究者尝试使用自然语言处理(NLP)的思想来解决二进制码分析问题。通过将汇编指令视为自然语言,他们训练文本嵌入模型,然后使用情感分析或主题建模等技术对代码进行分类或聚类。从而达到识别目标代码的目的。
(4) Code clone detection
对于相似度检测这一课题,无论是基于源代码还是基于二进制系统的研究,其方法在很多地方都是通用的。按照主流思想可以分为文本字符串检测[33,34]、基于标记的相似度检测[35,36]和基于树的检测[10,37,38]。
方法
Overview
在本节中,我们描述了用于二进制检测和识别的GENDA。图1给出了GENDA框架的概述。

在获得开源加密库源代码后,第一步是通过选择不同版本、优化级别、编译器和指令集作为数据集,对源代码进行交叉编译。
Encryption algorithm features extraction
不同类型的加密算法由于其独特性而包含许多不同的特征。例如,块加密算法包含大量的算术指令、跳转指令和逻辑运算指令。公钥加密中的指令分布更加均匀。
加密中经常涉及到大整数或大数组,如块加密中的混合矩阵常数、哈希算法加密的SHA-1和MD5的初始链值。无论是采用整数分解、离散对数解还是椭圆曲线解,在公钥加密中都不可避免地要用到大素数。通过区分这些常数特征,可以很好地区分加密算法的分类。
加密算法由于其特殊性,具有明显的统计特征。首先,加密算法中的指令数受到限制。要实现加密或解密功能,指令总数不会太小。当指令数量低于一定数量时,可能不考虑。加密算法核心功能中算术运算、逻辑运算和移位运算的频率明显高于其他运算指令。由于位移表的存在和分组密码周期多轮运算的特点,会更加明显地出现同结构代码循环。图3为对200组分组加密算法进行反分析统计的指令频率分布。

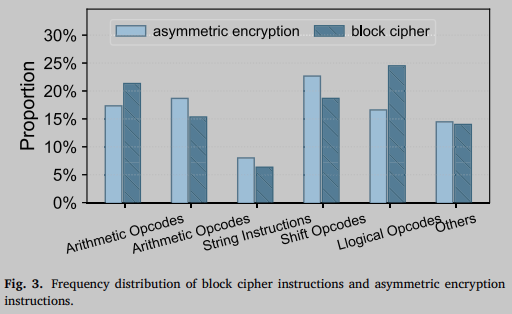
在运算方面,根据前一节分组密码的特点,可以确定大部分运算都是处理器ALU支持的基本算术运算,包括加、减、乘、除和逻辑运算异或。公钥加密算法涉及大量的模运算,这些基本运算被去掉了。模运算可以由固定的基本运算组成。公钥加密常用的基本公式 m e ( m o d n ) m^e (mod\ n) me(mod n) 可以由如图4所示的指令组成。例如,识别代码中是否包含大量此类操作是判断公钥加密的重要依据。
非指令特征是指与具体指令内容没有直接关系,但与所有指令的总体特征有关的特征。第一类非指令特征是函数基本块的数量/指令总数/局部变量的数量。
Encryption algorithm graph structure
本文构造了一种新的数据结构——加密算法图,将加密函数转化为以基本块特征集为节点,调用关系为边的图嵌入神经网络。在这种情况下,节点内容保证了文本信息,边的流向保证了结构信息。与直接使用每个基本块进行特征聚合相比,使用加密算法图的流程图结构可以更好地保留函数中的信息。
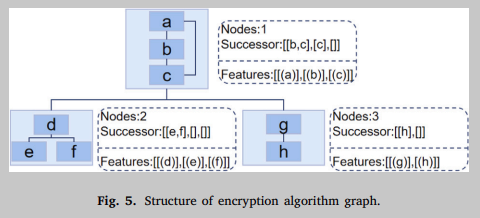
加密算法图的结构如图5所示,其中边缘采用后缀树表示法表示。树中的每个节点按顺序记录与其相连的子节点,并表示直接指向的基本块信息。使用后缀tree,可以构建从第一个节点开始的整个功能的完整流程图。在这一点上,已经获得了一个数据结构,包括一组节点和一组边, T = < V , E > T=<V, E> T=<V,E>,其中顶点还包括在前一节中获得的三种类型的数据。
Graph construction data structure selection
在构成图形时,选择成熟的复杂网络构建工具NetworkX。它支持创建多种类型的结构图,构建无向图、有向图和多图。根据功能特点,本文需要一种能够表示控制流程的有向图。由于程序调用时可能出现“多边”情况,因此综合选择了多向图。节点信息和网络拓扑,在构建图时需要关注。对于明显的稀疏图存储,应采用字典的字典数据结构进行存储。它的优点是字典字典结构可以提高稀疏存储的空间利用率。并且数据可以添加到“边”结构中,比如权重。此外,可以方便地通过字典表查询边缘关系,并可以快速遍历邻接关系。

对于加密算法的流程图提取过程,这里采用图的深度优先遍历 (DFS)。其核心思想是根据提取的控制流块和各节点的邻接矩阵对控制流进行深度优先仿真。每次遍历整个控制流路径并记录连接关系。在所有DFS完成后,使用NetworkX的合成模式生成相应的加权有向图。目前还没有确定权重,只有保留属性。代码如算法1所示。
Model training and detecting

本文的目的是测试加密算法是否符合要求。为了实现这一目标,我们对标准加密算法、要检测的算法、要检测的算法进行了代码相似度分析和检测。对于这类问题,通常有两种选择:
(1) 把这个问题当作分类问题,训练一个可以直接对目标加密算法进行分类的模型。
(2) 通过相似度检测,将未知类型的算法与确定类型的加密算法进行比较,并训练出判断这些相似度的模型。
实验
加密算法检测实验 对算法托管平台上已知的开源库或开源加密算法进行检测,检测各类加密算法是否能够正确识别。
与现有工作的比较实验 与相关领域已有的开源工具进行比较,并进行各种对比实验。
Datasets
该评估旨在验证GENDA是否能够正确识别目标加密算法。要检测的对象是实现某些加密功能的完整函数或函数块。为此,我们通过剥离和交叉编译的方法,从知名开源项目中共收集了1835个编译好的加密算法。具体来说,分组密码可以分为CFB(密码反馈块)、OFB(输出反馈块)、CBC(密码块链)和ECB(电子代码本)。
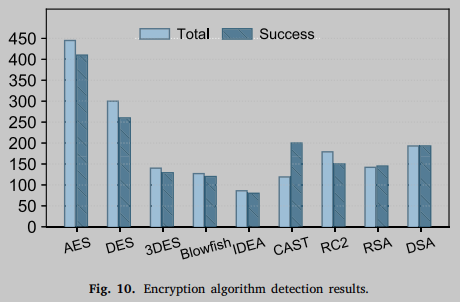
The specific quantities were as follows: AES, 445 copies, DES, 301 copies, 3DES, 141 copies, Blowfish, 127 copies, IDEA, 86 copies, CAST, 218 copies, RC2, 178 copies, RSA, 145 copies and DSA, 194 copies. The individual encryption algorithms were stripped from the open source encryption library like OpenSSL, Sodium, LibTomcrypt and Crypto++.

Example
计算公式的“相似性”基于马氏距离。为了计算方便,将相似度除以图向量的长度。相似度的最终结果固定在0%-100%。百分比越大,两个函数越相似。实验的具体过程如下:以从开源加密库Crypto++中剥离的加密算法AES_128_CFB为例,该加密算法由14个函数组成。由于剥离的数据是源代码数据,而本系统的预期输入是二进制代码,因此需要对其进行随机编译以获得二进制数据,并使用IDA Pro进行反编译。从指定入口点(本例为0x00401249)开始,使用图结构生成模块进行处理,如图7所示。图形结构生成模块是在IDA Python插件和NetworkX的帮助下完成的。实现了基本块中操作码特征的提取和程序流程图的提取记录等功能。在这个过程中,为组成AES的每个函数生成了一个单独的图结构,总数为14,这些算法被记录在一个json文件中。

接下来是数据预处理。并非所有的图结构在训练中都是必需的。在构成AES_gcm_init函数的14种加密算法中,也有一些算法与加密本身的关系不太密切。例如,ASN_STRING_print_ex函数提供字符串打印功能。当将这些独立于加密的函数加入到模型训练中进行相似度识别时,会影响最终的结果。根据加密算法的复杂性和其他特点,制定了预处理逻辑。排除基本块数小于10或超过一半的基本块无后续节点的算法。这样可以最大限度地提高加密算法的识别效果。经过处理,在AES_gcm_init函数中,还剩下11个函数。
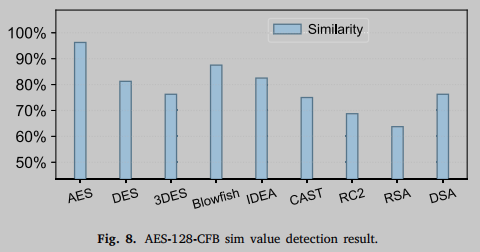
下一步是将生成的11个 EAG 结构嵌入到训练良好的深度学习模型中,作为待检测函数的向量集。同时,对OpenSSL1.0.1中预生成并剥离的标准加密算法进行预处理和嵌入,生成标准加密向量集。其中包含AES、DES、3DES、Blowfish等9种加密算法的图嵌入结构,共97个。然后,依次比较向量之间的距离,并将11个图向量与9种标准加密算法进行比较,取最近的向量距离作为最终结果。从图8中可以看出,AES_128_CFB的检测结果与AES算法的sim值最为相似,因此可以确定检测成功。
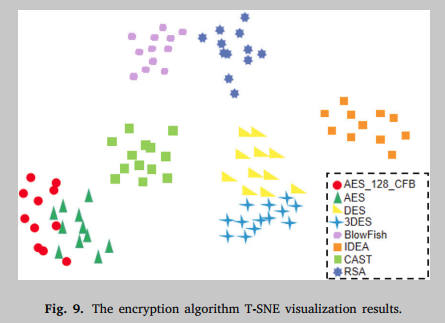
更直观的是,从图9可以看出,嵌入空间是一个二维向量空间,T-SNE可视化后可以清晰地看到嵌入向量之间的距离关系。图中AES_128_CFB的分布与标准加密算法AES最接近,嵌入向量距离最短,因此可以判断两个函数最相似。
Detection
所有测试用例的结果如图10所示。
Comparison experiment with existing work
本文选择了现有的4种工具,从检测、精度和效率三个方面进行了较为全面的横向比较。为了公平起见,测试数据排除了GENDA的训练数据(OpenSSL和Crypto)进行比较。采用Github、Googlecode等项目托管平台中的多星加密算法和其他开源加密数据库数据组成新的测试数据集,避免误报结果。
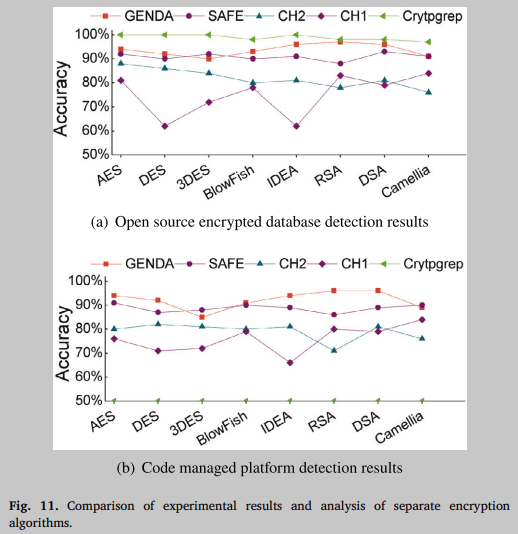
图11(a)和图11(b)分别显示了数据集为开源加密库或代码托管平台(如Github)时各系统的准确率性能。CH1是“一种改进的密码函数识别方法”,CH2是“二进制码级密码算法循环特征识别”。从图中信息可以看出,Cryptgrep在对开源加密库的检测方面表现非常好,基本可以实现完整的检测,因为Cryptgrep是基于签名检测加密算法的,如果签名库中包含该加密算法,则可以很好地检测到它。
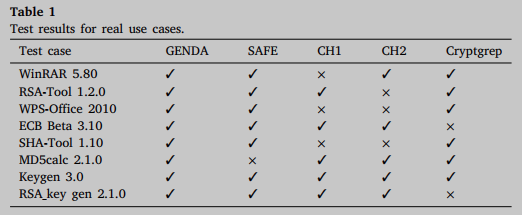
各系统真实软件的检测结果如表1所示。对于GENDA和SAFE等相似度检测模型,成功检测的定义是相似度大于90%。对于其余三种系统,直接判断目标加密算法能否被正确检测出来。结果表明,基于相似度检测的加密算法检测系统具有较宽的检测范围,而基于静态分析或算法签名的系统在性能上存在局限性。
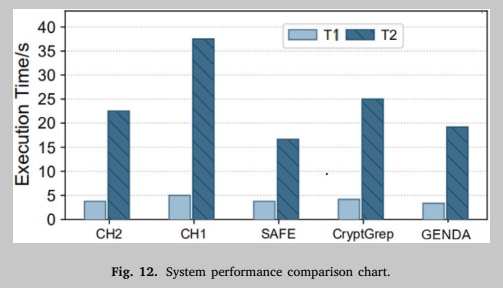
图12显示了不同系统的性能。性能定义为在相同条件下,系统从输入不同系统的二进制码开始给出最终结果所消耗的时间。其中T1表示检测目标是与加密函数库分离的独立加密算法时的平均运行时间。T2表示检测到的目标是二进制文件时的平均运行时间。对于单个加密算法的检测,发现GENDA是最有效的,它可以快速判断代码是否是加密算法。但是从整个软件的判断来看,GENDA需要大量的二进制代码转换到加密算法图,所以效率会比较低。当软件的体积扩大时,几乎所有的用例都会降级。GENDA的性能损失低于平均水平,在可接受的范围内。
总结
References
[10] Yeo HS, Phang XS, Lee HJ, Lim H. Leveraging client-side storage techniques for enhanced use of multiple consumer cloud storage services on resource-constrained mobile devices. J Netw Comput Appl 2014;43:142–56.
[15] Narayanan A, Chandramohan M, Venkatesan R, Chen L, Liu Y, Jaiswal S. graph2vec: Learning distributed representations of graphs. 2017, arXiv preprint arXiv:1707.05005.
[16] Augusto Rodrigues de Souza W, Alfredo Vidal de Carvalho L, Antonio Moreira Xexeo J. Identification of N block ciphers. IEEE Lat Am Trans 2011;9(2):184–91. http://dx.doi.org/10.1109/TLA.2011.5765572.
[17] Mishra S, Bhattacharjya A. Pattern analysis of cipher text: a combined approach. In: 2013 International conference on recent trends in information technology. IEEE; 2013, p. 393–8.
[18] Lomte VM, Shinde AD. Review of a new distinguishing attack using block cipher with a neural network. Int J Sci Res 2014;3(8):2012–5.
[19] Tiwari V, Pradeepthi K, Saxena A. Identification of cryptographic algorithms using clustering techniques. In: Proceedings of the third international conference on computational intelligence and informatics. Springer; 2020, p. 513–21.
[20] Ji-Zhong LI, Jiang LH, Yin Q, Liu TM, Guo J. Cryptogram algorithm recognition technology based on Bayes decision-making. Comput Eng 2008;34(20):159–61.
[21] Liu TM, Jiang Lh, He Hq, Li Jz, Yu X. Researching on cryptographic algorithm recognition based on static characteristic-code. In: international conference on security technology. Springer; 2009, p. 140–7.
[22] Maiorca D, Giacinto G, Corona I. A pattern recognition system for malicious pdf files detection. In: International workshop on machine learning and data mining in pattern recognition. Springer; 2012, p. 510–24.
[23] Tzermias Z, Sykiotakis G, Polychronakis M, Markatos EP. Combining static and dynamic analysis for the detection of malicious documents. In: Proceedings of the fourth european workshop on system security. 2011, p. 1–6.
[28] Ye G, Tang Z, Wang H, Fang D, Fang J, Huang S, et al. Deep program structure modeling through multi-relational graph-based learning. In: Proceedings of the ACM international conference on parallel architectures and compilation techniques. 2020, p. 111–23.
[29] Wang H, Ye G, Tang Z, Tan SH, Huang S, Fang D, et al. Combining graph-based learning with automated data collection for code vulnerability detection. IEEE Trans Inf Forensics Secur 2020;16:1943–58.
[33] Baker BS. On finding duplication and near-duplication in large software systems. In: Proceedings of 2nd working conference on reverse engineering. IEEE; 1995, p. 86–95.
[34] Pewny J, Garmany B, Gawlik R, Rossow C, Holz T. Cross-architecture bug search in binary executables. IEEE Comput Soc 2015;709–24.
[37] Jiang L, Misherghi G, Su Z, Glondu S. Deckard: Scalable and accurate tree-based detection of code clones. Proc Int Conf Softw Eng 2007;96–105.
[38] Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 2012;25:1097–105.
Insights
(1) 使用信息熵判断是否使用加密算法
(2) 要实现加密或解密功能,指令总数不会太小。当指令数量低于一定数量时,可能不考虑。加密算法核心功能中算术运算、逻辑运算和移位运算的频率明显高于其他运算指令
(3) 这篇论文和 Where’s Crypto 那篇比较接近, Where’s 用Ullman算法进行子图同构匹配, 本篇是用图神经网络中向量距离做加密算法类型判断