
Abstract (摘要)
这篇文章基于场景图的概念,提出了一种新的语义图像检索框架。场景图表示了对象(“人”,“船”),对象的属性(“船是白色的”),对象之间的关系(“人站在船上”)。我们使用这些场景图来检索与场景图语义相关的图像。为此,我们设计了一个条件随机场模型,为每一个场景图挑选出可能的测试图片。这些理由的可能性被用作检索的排名分数(The likelihoods of these groundings are used as ranking scores for retrieval.)。我们介绍了一个新数据集,这个数据集中含有5000张图片及这些图片对应的场景图,并用这个数据集来评估我们的图像检索方法。特别地,我们使用全场景图和小场景子图来评估检索,并且表明我们的方法优于只使用对象或低级图像特征的检索方法。此外,我们表明,我们的模型可以用来提高对象定位的准确度compare to baseline methods。
一、Scene Graphs(场景图):
为了检索图像包含的特定的语义信息,我们需要一种规范化方法来描述场景中的内容,这种表达必须足够强大,以描述丰富多彩的场景,而且不太繁琐。为此,我们定义了两个抽象概念:scene graph(用来描述场景)和scene graph grounding(场景图与图像的具体关联)。(grounding的意思应该是场景图的每个对象与图像中的区域的对应)
场景图是用来描述场景的数据结构,一个场景图包含了对象的实例,对象的属性,以及对象之间的关联。
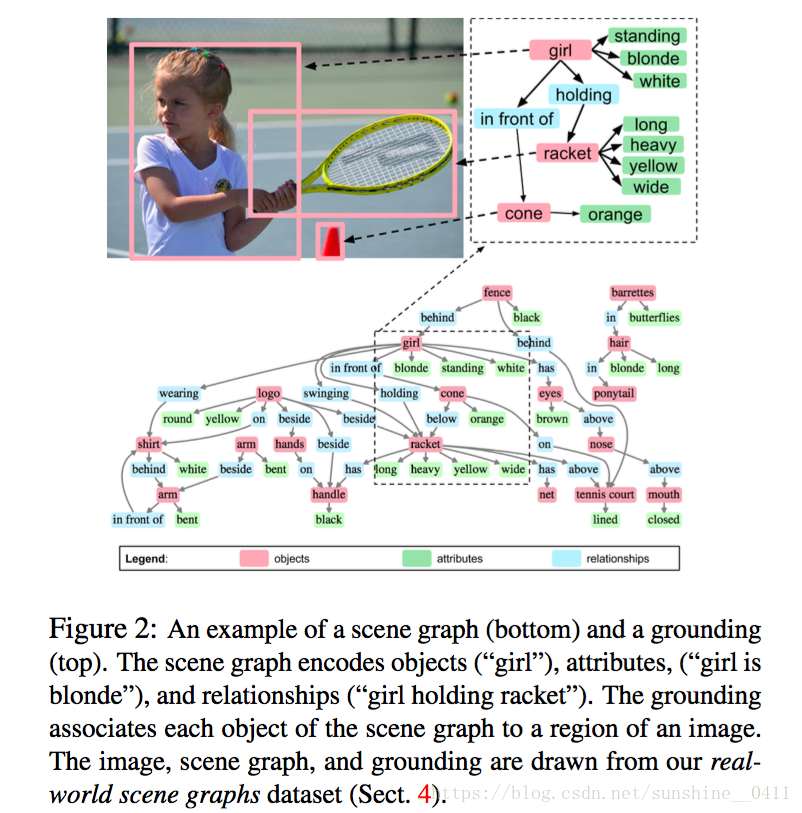
上图的下面部分:
是一个场景图,场景图的对象可以是人(“girl”),地点(“tennis court”),物品 (“shirt”),其他(“arm”)。属性可以是颜色(“cone is orange ”),形状(“logo is round ”),以及姿势(“arm is bent ”)等。关系可以是位置(“fence behind girl ”),动作(“girl swinging racket ”),对象的一部分(“racket has handle ”)等。
定义对象类别集合C,属性类别集合A,关系类别集合R。场景图G(O, E) ,其中O={o1,...,on} 是对象,E ⊆ O×R×O 是边。每个对象 oi = (ci, Ai),ci ∈ C,Ai ⊆ A。
上图的上面部分:
通过将场景图中每一个对象实例和图像中某一个区域相关联 可以将场景图和真实世界的图片关联起来。
真实世界图片中的部分区域的集合为B(bounding boxes )。
γ : O → B :将场景图中的对象和图片中的部分区域相关联,即一个grounding。
二、Real-World Scene Graphs Dataset
本文提出了一个新的数据集:real-world scene graphs :从YFCC100m and Microsoft COCO选取了5000张图片重新标注。对每张图片,标出其(对象,属性)和(对象,关系,对象)元组,描述词汇是非固定的单词不是预定义好的词汇,并且标出每个对象在图片中对应的方形区域。
数据集一共5000张图片,包含93,000 个对象实例,110,000 个属性实例和112,000 个关系实例。实验部分只考虑训练集中对象类别和属性种类出现50次以上,关系种类出现30次以上的数据。如下图所示,新的数据集的对象数量远高于原始数据集,且比原始数据集新增属性和关系。

三、Image Retrieval by Scene Graph Grounding
我们希望使用场景图来检索图像场景与场景图描述场景相似的图像。我们需要测量要查询的场景图和未注释的图像之间的相似程度。我们假设相似程度可以通过检查场景图和图像之间最可能的 grounding 来决定。
本文构建了一个条件随机场,该CRF模拟了所有可能的groundings分布,再通过最大后验(MAP)寻找最可能的grounding。
通过对比几种方法,图像子区域(candidate boxes )的选择使用Geodesic Object Proposals (GOP[2])方法。
算法:
G=(O,E)是场景图,B是bounding boxes的集合(图像中的一个个方形子区域),γ 是一个grounding。有:

根据贝叶斯,上式变为:

四、Experiments(实验):
4000个训练图像,1000个测试图像,一共比较了如下几个方法:
SG-obj-attr-rel:上述模型,场景图中含有对象,属性,关系。
SG-obj-attr:上述模型,场景图中含有对象,属性。
SG-obj:上述模型,场景图中只含有对象。
以及CNN, GIST, SIFT, Random.
实验结果如table2:
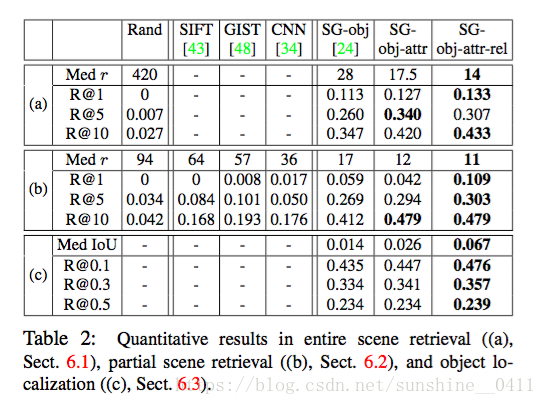
1、在full ground-truthscene graphs中
目的:“复杂的全场景图”,证明模型可以精确的描述要检索的图片
结果:shown in Table2 (a)
2、在extremely simple scene graphs中
目的:“非常简单的场景图”,证明模型非常灵活
结果:shown in Table2 (b),效果优于传统方法和其他方法
3、object localization
模型可以用于单个目标的定位,结果依旧很优。Shown in table2 (c)
Conclusion(总结)
本文将场景图作为视觉场景中细节语义的一种新的表示方法,并引入一个新的数据集,这个数据集将场景图和真实世界的图片关联起来。我们已经使用这种表示和数据集构建一个CRF模型,用场景图作为查询来进行语义图像检索。实验表明,该模型优于基于对象检测和低层次视觉特征的方法。我们认为,语义图像检索是我们的场景图表示和数据集的许多令人兴奋的应用之一,并希望更多的后续。
参考
[1] Image Retrieval using Scene Graphs
[2] P. Kra ̈henbu ̈hl and V. Koltun. Geodesic object proposals. In Computer Vision–ECCV 2014, pages 725–739. Springer, 2014. 6