
Abstract
使人类区别于现代基于学习的计算机视觉算法的一个特征是获得关于世界的知识并使用该知识推理关于视觉世界的能力。人类可以了解物体的特征以及它们之间发生的关系,从而学习各种各样的视觉概念,并且可以通过很少的例子学习。本文研究了知识图谱形式的结构化先验知识在图像分类中的应用,表明利用结构化先验知识可以提高图像分类的性能。我们基于最近关于图的端到端学习的工作,引入Graph Search Neural Network,作为将大知识图谱有效地结合到视觉分类pipeline中的方法。我们在一些实验中表明,我们的方法在多标签分类中优于标准神经网络。
Introduction
我们的世界包含人类理解的数百万视觉概念。这些常常是模棱两可的(番茄可以是红色或绿色),重叠的(交通工具包括汽车和飞机),并且有数十或数百个子类别(数千种特定种类的昆虫)。虽然一些视觉概念非常常见,如人或车,但大多数类别的例子较少,形成长尾分布。然而,即使只显示了几个甚至一个例子,人类仍然具有非常显著的能力来高精度地识别这些类别。相比之下,虽然现代的基于学习的方法可以高精度地识别某些类别,但是通常需要为这些类别中的每个类别提供数千个标记的示例。考虑到视觉概念空间大、复杂而且动态,这种为每个概念构建大型数据集的方法是不可扩展的。因此,我们需要寻找目前人类拥有而机器没有的方法。
在图上或者神经网络训练的图中,端到端(备注:端到端指输入是原始数据,输出是最终结果)的学习已经有很多工作。大多数方法要么从图中提取特征,要么学习在节点之间传递证据的传播模型,该模型以边缘的类型为条件。一个例子是Gated Graph Neural Network,它以任意的图作为输入。给定特定于任务的一些初始化,它学习如何传播信息并预测图中每个节点的输出。该方法已被证明可以解决基本的逻辑任务和程序验证。
我们的工作改进了该模型,并将端到端的图形神经网络应用于多标签图像分类。我们引入图形搜索神经网络(Graph Search Neural Network,GSNN),它利用图像中的特征对图形进行有效的注释,选择输入图的相关子集,并预测表示视觉概念的节点上的输出。然后使用这些输出状态对图像中的对象进行分类。GSNN学习传播模型,该模型推理不同类型的关系和概念,以便在节点上产生输出,然后用于图像分类。我们的新架构减轻了GGNN在大图上的计算问题,这允许我们的模型被有效地训练并用于使用大知识图谱的图像任务。我们展示了我们的模型在推理概念中是如何有效的,以改善图像分类任务。重要的是,我们的GSNN模型还能够通过跟踪信息在图中如何传播来提供关于分类的说明。
这项工作的主要贡献是:(a)引入GSNN,作为将潜在大知识图谱合并到端到端学习系统中的一种方法,该系统在大图的计算上是可行的;(b)使用噪声知识图谱进行图像分类的框架;(c)通过使用传播模型来解释我们的图像分类的能力。我们的方法大大优于多标签分类的baselines。
Methodology
1、Graph Gated Neural Network
给定N个节点的图,我们希望产生一些输出,这些输出可以是每个图节点 ,
, ...
的输出,也可以是全局输出
。这是通过学习一个类似于LSTM的传播模型来实现的。对于图v中的每一个节点,在每一个时间t,都有一个隐状态
。从t=0时刻开始,初始隐状态
依赖于问题。例如,为了学习图的可达性,隐状态可能是一个二位向量,表明是源节点或者是目标节点。对于视觉知识图谱的推理,
可以是一位,表示类别的置信度,基于一个对象检测器或者分类器。
接下来我们使用图结构,编码在矩阵A中,矩阵A用于检索相邻节点的隐藏状态,基于相邻节点之间的边缘类型。然后通过类似于LSTM的门控更新模块来更新隐藏状态。这个传播网络的基本递归是:
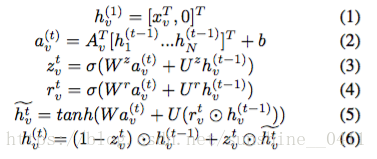
其中是节点v在时刻t的隐状态,
是问题的特定注释,
是节点a的图邻接矩阵,W和U是学习参数。等式(1)是具有
和空维度的隐状态的初始化,等式(2)展示了来自相邻节点的迭代更新,等式(3-6)结合相邻节点的信息和节点的当前隐藏状态来计算下一个隐藏状态。
T步之后,我们得到了最后一个隐状态。节点级别的输出可以被计算为:
g是一个全连接网络,全连接层是输出层,是节点的初始注释。
2、Graph Search Neural Network
GGNN在图像任务中最大的问题是计算可扩展性。例如,NEIL有2000多个概念,NELL有200多万的confident beliefs。即使我们的任务剪枝之后,这些图表仍然是巨大的。N个节点的标准GGNN,正向传播复杂度是O(),逆向传播是O(
), 其中t是传播次数。我们对合成图上的GGNNs执行简单的实验,发现在大约500个节点之后,即使做出大量的参数假设,一个实例的前向和后向传递会花费1秒钟的时间。在2000个节点上,单个图像需要花费超过一分钟的时间。使用GGNN是不可行的。
我们对这个问题的解决方法是Graph Search Neural Network(GSNN)。顾名思义,我们的想法是,与其同时对图的所有节点执行我们的周期性更新,不如根据我们的输入从一些初始节点开始,并且只选择扩展对最终输出有用的节点。因此,我们只在图的子集进行更新。那么,我们如何选择节点的子集来初始化图呢?在训练和测试期间,我们确定图的初始节点,基于由对象检测器或分类器确定的概念存在的可能性。我们的实验使用更快的R-CNN对于80个COCO类别中的每一个。对于一些选定的阈值的分数,我们选择图中的相应节点作为初始的活节点集合。
一旦确定了初始节点,我们将邻接于初始节点的节点添加到活动集。给定初始节点,我们首先将初始节点的beliefs传播到所有相邻节点(we want to first propagate the beliefs about our initial nodes to all of the adjacent nodes.)。在第一步之后,我们需要一种方法来决定接下来要扩展哪些节点。因此,我们学习了每个节点评分函数,它估计节点是多么重要。在每个传播步骤之后,对于我们当前图中的每个节点,我们预测重要性得分:
其中gi是一个学习网络,即重要性网络。
一旦我们有了的值,我们将获取得分最高且从未被扩展的前p个节点,将它们添加到扩展集,并将那些节点的所有邻接节点添加到活动集。图二说明了这种扩展。
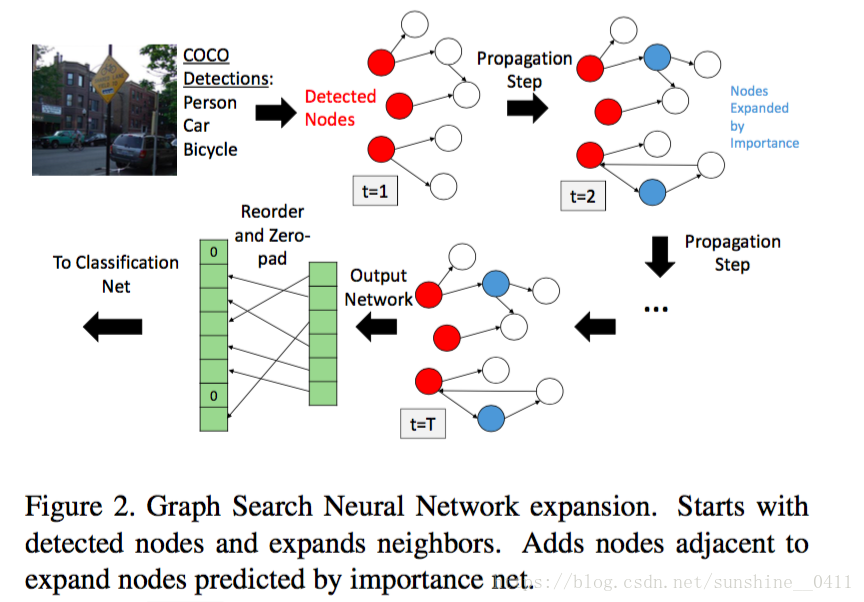
T=1时,仅检测到的节点被扩展。T=2时,我们基于重要性值扩展选择节点,并将它们的邻居添加到图中。在最后一步T,我们计算the per-node-output, the re-order and the zero-pad,输出到最终分类网络。
为了训练重要性网络,我们为给定的图像在图中的每个节点分配重要性值。对应事实概念的节点重要度为1,这些节点的邻居被分配一个γ值。隔一个的节点具有值γ
2(γ的平方)等。 这个想法是最接近最终输出的节点是最重要的扩展。
现在我们有一个端到端网络,它接受一组初始节点和注释作为输入,并且输出图中每个活动节点的输出。它由三个网络组成:传播网络、重要性网络和输出网络。图像问题的最终损失可以反向传播,从pipeline的最终输出,通过输出网络。重要性损失通过每个重要性输出反向传播。Figure3展示了GSNN的架构。
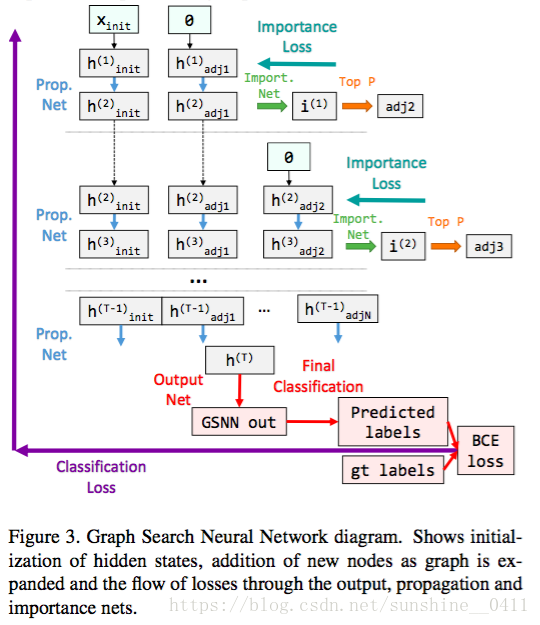
图的解释:
: the detection confidences
: the hidden states of the initially detected nodes, 初始化为
: 初始化邻接结点的隐藏状态
被用来预测重要性得分
,重要性得分用来挑选接下来哪些结点被加入adj2中
初始化=0, 通过传播网络更新隐状态
T步后,我们用所有的累积隐藏状态来预测所有活动节点的GSNN输出。
在反向传播过程中,二进制交叉熵(BCE)损失通过输出层反向反馈,而重要损失通过重要度网络反馈以更新网络参数。
最后一个细节是将“节点偏置”添加到GSNN中。在GGNN中,每个节点的输出函数g(hv,xv)接受节点v的隐藏状态和初始注释来计算其输出。从某种意义上说,它对节点的意义是不可知的。也就是说,在训练或测试时,GSNN可能获得它从未见过的图表,和每个结点的初始注释xv(or并为每个节点提供一些初始注释xv?)。然后,它使用图的结构通过网络传播这些注释,然后计算输出。图的节点可以表示从人际关系到计算机程序的任何东西。然而,在我们的图网络中,特定节点表示“马”或“猫”的事实可能相关,并且我们还可以将自己约束为图像概念上的静态图。因此,我们引入节点偏置项,对于我们的图中的每个节点,都有一些学习的值。我们的输出方程现在是G(HV,XV,NV),其中NV是与整个图中的特定节点V相联系的偏置项。这个值被存储在一个表中,并且它的值通过反向传播来更新。
3、Image pipeline and baselines
对于视觉问题,我们面临的另一个问题是如何将图形网络合并到image pipeline中。对于分类,这是相当简单的。我们获取图网络的输出,对其进行reorder,以便节点总是以相同的顺序出现在最终网络中,并且zero pad任何未扩展的节点。因此,如果我们有一个具有316个输出节点的图,并且每个节点预测一个5维隐藏变量,那么我们从图中创建一个1580维的特征向量。我们还将这个特征向量和a fine-tuned VGG-16 network的fc7 layer (4096-dim) 和由更快的R-CNN(80-dim)预测的每个COCO类别的最高得分连接起来。这个5676维的特征向量送到一层的最终分类网络中训练。
对于baseline,我们比较了:(1) VGG Baseline - feed just fc7 into final classification net; (2) Detection Baseline - feed fc7 and top COCO scores into final classification net.
Results
1、Datasets
我们希望实验数据集表达了复杂、有噪声的视觉世界,有许多不同种类的对象,标签可能模糊或重叠,并且是长尾分布。本实验使用Visual Genome dataset v1.0
在我们的实验中,我们创建了Visual Genome的子集Visual Genome multi-label dataset or VGML,我们选取了200个最常见的对象,100个最常见的属性,还为316个视觉概念添加了不在这300个对象和属性中的任何COCO类别。我们的任务是多标签分类:对于每个图像预测316个总类别中的哪个子集出现在场景中。随机将图片分成80-20训练集/测试集。由于我们使用了来自COCO的预先训练的检测器,所以我们确保没有一个测试图像与我们的检测器的训练图像重叠。
我们还在更标准的COCO数据集上评估我们的方法,以表明我们的方法在多个数据集上有用,并且我们的方法不依赖于专门为我们的数据集构建的图。我们在多标签集中进行训练和测试,并对微型集进行评估。
2、Building the Knowledge Graph
我们也使用Visual Genome作为我们知识图谱的来源。Using only the train split,(仅用于训练时的分割?) 我们使用数据集中最常见的对象-属性和对象-对象关系来构建连接概念的知识图谱。具体地说,我们计算在训练集中出现对象/对象关系或对象/属性对的频率,并剪掉任何少于200个实例的边。这给我们留下了关于每个边缘是共同关系的图像的图表。我们的想法是,我们会得到非常常见的关系(如草是绿色或人穿衣服),但不是罕见的关系,只出现在单一的图像(如人骑斑马)。
Visual Genome graphs对我们的问题是有用的,因为它们包含对象之间的场景级关系,例如人穿裤子或消防栓是红色的,因此可以推断场景中的内容。然而,它不包含有用的语义关系。例如,如果我们的视觉系统“看到了”一条狗,而我们的标签是动物,如果能知道狗是动物的一种对分类是有帮助的。为了解决这个问题,我们还创建了一个融合了Visual Genome Graphs与WordNet的图。使用[1]中的WordNet子集,我们首先收集WordNet中不在输出标签中的新节点,包括那些直接连接到输出标签并因此可能相关的节点,并将它们添加到组合图中。然后,我们将这些节点之间的所有WordNet边缘添加到组合图形中。
3、Training details
我们共同训练pipeline的所有部分(除了detectors)。GSNN使用ADAM,其他所有模型使用SGD。对于fc7之前的VGG网络,我们使用0.05、0.005的初始学习率,每10次减少0.1倍,L2惩罚为1e-6,动量为0.5。。。。
[1] K.Guu,J.Miller,andP.Liang.Traversingknowledgegraphs in vector space. In Empirical Methods in Natural Language Processing (EMNLP), 2015.