-
乘积量化PQ(Product Quantization):
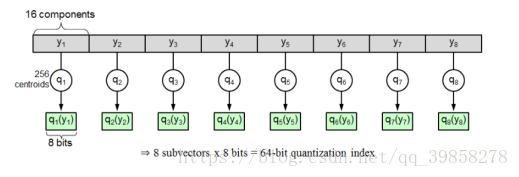
PQ算法将D维空间切分为M个D/M维的子空间:假设现得到每张图片特征向量维度为128维,共256张图片。为了加速距离运算,现将128维向量切分成8段,如下图所示。
分别在每一段所表示的子空间中进行K-means聚类,之后在每一段中用距离该段内距离最近的聚类中心的编号来作为索引值,即每一个128维向量被压缩为8个索引值表示的向量。保留压缩后的向量与聚类中心。

-
SIFT特征(尺度不变特征变换):
(1)DoG尺度空间的极值检测:首先是构造DoG尺度空间,在SIFT中使用不同参数的高斯模糊来表示不同的尺度空间。而构造尺度空间是为了检测在不同尺度下都存在的特征点,特征点的检测比较常用的方法是高斯拉普拉斯LoG,但是LoG的运算量是比较大的,故可以使用DoG差分高斯来近似计算LoG,所以在DoG的尺度空间下检测极值点。
(2)删除不稳定的极值点:主要删除两类:低对比度的极值点以及不稳定的边缘响应点。
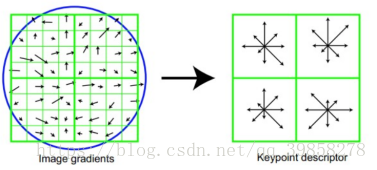
(3)确定特征点的主方向:以特征点的为中心、以3×1.5σ3×1.5σ为半径的领域内计算各个像素点的梯度的幅角和幅值,然后使用直方图对梯度的幅角进行统计。直方图的横轴是梯度的方向,纵轴为梯度方向对应梯度幅值的累加值,直方图中最高峰所对应的方向即为特征点的方向。
(4)生成特征点的描述子:首先将坐标轴旋转为特征点的方向,以特征点为中心的16×1616×16的窗口的像素的梯度幅值和方向,将窗口内的像素分成16块,每块是其像素内8个方向的直方图统计,共可形成128维的特征向量。
-
VLAD局部聚合向量(Vector of Aggragate Locally Descriptor):
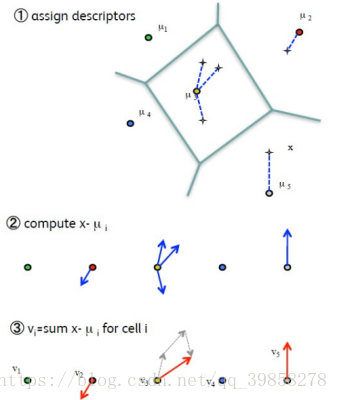
给定一个由类似K-means算法得到的码本和一个从某张图像提取到的局部描述子集合。VLAD算法包括如下步骤:
- 把每个描述子赋给最近的码本
- 计算每个码本与之被赋予的描述子的差
- 对所得差向量合成并做L2归一化
三步骤可用如下图表示:

-
BING算法:
生成目标proposal的快速方法,为接下来的detectors提供可能的目标区域:

-
估计最近邻算法(ANN):
KD树、随机K-D树:大概是通过每次寻找方差最大的维度作为判别标准进行树的构造,中位数作为节点,小于节点的在左子树,大于在右子树,之后对每个子树也相同。
查找过程:将查询数据Q从根节点开始,按照Q与各个节点的比较结果向下遍历,直到到达叶子节点为止。到达叶子节点时,计算Q与叶子节点上保存的所有数据之间的距离,记录最小距离对应的数据点,假设当前最邻近点为p_cur,最小距离记为d_cur。进行回溯操作,该操作的目的是找离Q更近的数据点,即在未访问过的分支里,是否还有离Q更近的点,它们的距离小于d_cur。
-
数据库增强之查询扩展方法TR:
如果一张图像在查询阶段被验证为查询图像的相关图像,则可以将其作为参考来提升检索召回率。首先一个特征A被验证为相关图像特征,然后查询图像特征被朝向A进行偏移,并进行重排序。此后,另一个相关图像特征B就离新的查询特征更近,更有可能在重排序阶段被检索到。