【论文笔记】
用于图像-文本匹配的交叉模型深度投影学习
1. 论文提出了一种交叉模态匹配(cross-modal projection matching,CMPM)损失和交叉模态投影分类(cross-modal projection classification,CMPC)损失,来学习判别图像-文本嵌入。
- CMPM损失:为了增加不匹配样本间的方差和匹配样本间的联系,最小化了投影兼容性分布和归一化的匹配分布(由小批次样本中所有正负样本定义)之间的KL散度。
- CMPC损失:对于有identity标签的辅助分类任务,尝试利用 改进的norm-softmax损失,对从一个模态到另一个模态的向量投影表示 进行分类,以进一步增强每个类的特征紧凑性。
2. 基于方法的联合的嵌入式学习在学习具有判别力的多模态表示和测试阶段的计算效率有很大的潜力。
3. 通常,用于图像-文本匹配的联合嵌入式学习框架采用双分支结构,其中一个分支提取图像特征,另一个分支编码文本表示。然后用设计的目标函数学习具有判别力的多模态嵌入。常用的函数有规范相关分析(canonical correlation analysis,CCA)和双向排序损失(bi-directional ranking loss)。与基于CCA的方法相比,双向排序损失具有更好的稳定性和更好的性能,并且在多模态匹配中得到越来越广泛的应用。然而在实际应用中,双向排序损失需要采样有用的triplets并且选择合适的margin。
4. 利用identity-level标注。【没太理解这个level,望有大佬指点】
5. 通过介绍分类损失作为辅助任务或者与训练的初始化,可以明显增强 学习的图像-文本嵌入的识别能力。
6. 解决问题:
考虑到独立分类不能充分利用identity信息进行多模态特征学习,《Identity-aware textual-visual matching with latent co-attention》改进了多模态交叉熵损失,利用多模态“sample-to-identify”的关系进行分类预测,而这种策略需要分配额外的identity特征缓冲区,当对象数量较多时,会带来较大的内存消耗。
7. 大多数基于深度学习方法来对图像和文本进行匹配的方法大致可以分为两种:1)联合嵌入学习(joint embedding learning);2)成对相似学习(pairwise similarity learning)。
8. 网络结构:
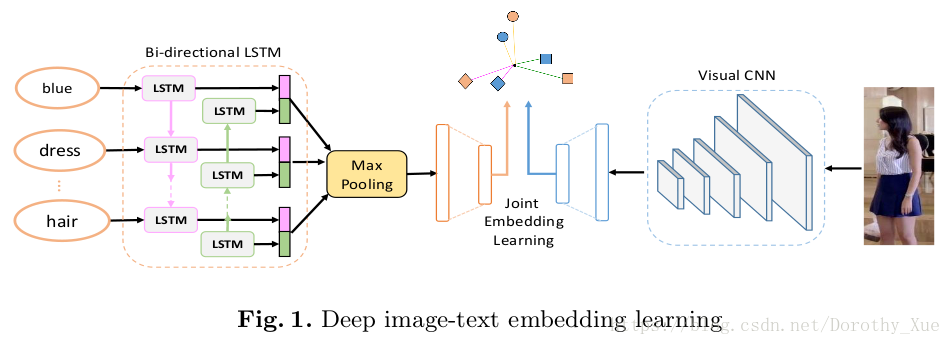
可分为3部分:
- 一个视觉CNN用于提取特征
- 一个双向LSTM用于编码文本特征
- 一个联合学习模块用于关联多模态表示
各部分功能:
- 图像:采用MobileNet(《Mobilenets: Efficient convolutional neural networks for mobile vision applications》),并从最后的池化层提取初始特征。
- 文本:给定一个句子,应用最基本的tokenizing(?标记法?),将句子拆分成单词,然后利用Bi-LSTM顺序处理这些单词。将正向和反向的隐藏态联系起来,采用最大池化策略获得初始文本表示。
- 联合学习:将提取的图像和文本特征嵌入到一个共享的潜在空间中,并最大化匹配特征之间的兼容性,以及不匹配样本间的方差。
9. CMPM:
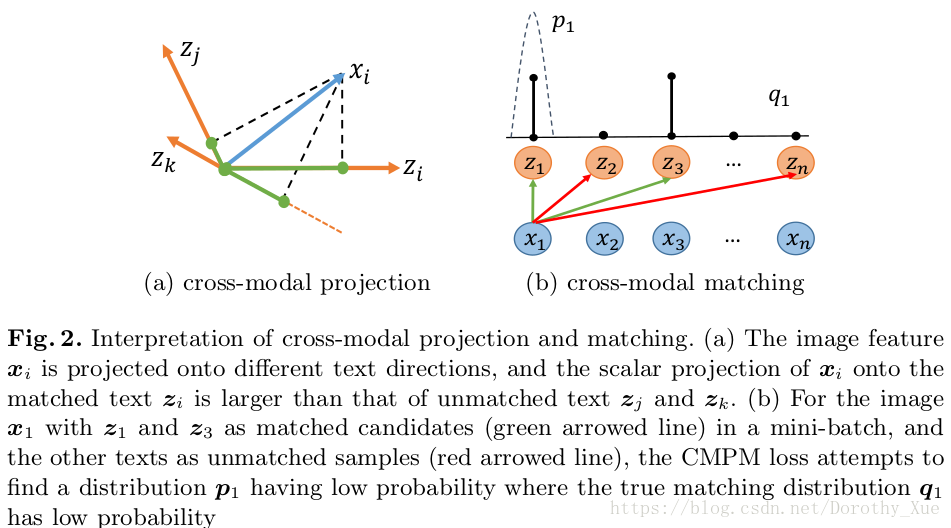
- 图像特征与文本特征越相似,标量投影越大。
- 给定一张图像,计算匹配损失时,要考虑mini-batch中所有正负文本候选对象,从而摆脱传统双向排序损失(bi-directional ranking loss)中的专用采样过程。
- 在图像-文本嵌入式学习中,通常在两个方向上计算匹配损失:① image-to-text匹配损失,要求匹配的文本比不匹配的离图像更近;②text-to-image匹配损失,强使相关的文本排在不相关的文本之前。
10. CMPC
利用identity-level标注的图像-文本匹配,应用于每个模态的分类损失有助于学习更有区分性的特征。
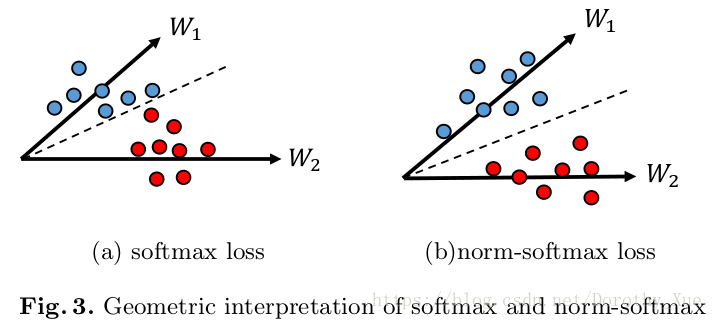
① norm-softmax
与原始的softmax损失相比,norm-softmax损失将所有权值向量归一化成相同的长度,以减小权重大小对区分不同样本的影响。
② 交叉模态投影
- 对图像特征在对应的文本特征上的投影进行分类,而不是对原始的特征表达进行分类。
- 交叉模态投影将图像-文本相似性集成到分类中,从而增强 匹配对 之间的关联。