摘要
在本文中,我们研究了在高度实用的环境下的视觉文本检索任务,在这种环境下,带有成对文本描述的标记视觉数据在一个域(“源”)中可用,而在感兴趣的域(“目标”)中只有未标记视觉数据(没有文本描述)可用。我们提出了AdaptiveCross-MODAL原型框架,该框架旨在通过学习跨模态可视文本表示来实现目标域检索,同时最小化源域和目标域之间的单峰和跨模态分布偏移。。我们的方法基于两个关键思想:第一,我们对归纳偏差进行编码,即学习到的跨模态表示应该是关于每个模态中的概念的组合。这是通过在每个域中聚类预训练的单峰特征并设计仔细的正则化方案来实现的,以保留产生的结构。其次,在学习过程中,我们在源域和目标域的跨模态表示之间使用互信息最大化,这提供了一种机制,该机制保留了域之间的共性,同时丢弃了每个域中无法从另一个域推断的信号。我们展示了我们的跨域可视文本检索方法,优于现有的图像和视频检索方法。
介绍
在本文中,我们研究了一个语用问题,即我们如何能够最好地利用配对数据学习“源”领域的知识,从而推广到其他“目标”领域,而无需额外数据收集的高昂成本。这项研究揭示了机器在一般情况下如何理解视觉和文本信息,而不是学习和利用特定领域的配对知识。
将在标记的源域上学习的模型转移到未标记的目标域的任务称为无监督域自适应(UDA)。在这方面,单峰分析已经取得了很大的进展。eg:图像分类[41]、图像分割[59]、文本情感分类[51]等。
本文将UDA用于涉及视觉和自由形式自然语言描述的跨模态任务。
可视化文本检索模型必须解决三个挑战(如图1所示):
-
(1)组成性:该模型需要用多个视觉实体(多个单词)的组合以及它们之间的关系来编码复杂的语义特征。(多个单词)
-
(2) 报告偏差:检索要求模型解决一个具有挑战性的集到集的跨模态匹配问题(其中多个视觉实体对应于自由形式的句子中包含的各种单词),其中跨模态的信息仅部分匹配(也就是没有把整个图片的所有信息全部描述出来,仅仅描述了重点的意思)。
-
(3) 视觉和文本领域的转变:检索模型必须对视觉内容和书面描述的领域转移具有鲁棒性。(也就是跨域呗)
ACP:
(1)为了解决组合性的需要,并实现报告偏差的稳健性,我们建议学习一种精心设计的正则化的跨模式表示。由于用于文本视频检索的数据样本缺乏自然的离散语义类结构(不同于用于分类的传统UDA,其中每个视觉输入映射到一个或多个有限的预定义类别),我们首先对目标域中的视觉内容和源域中的文本执行现成的单峰嵌入聚类。然后,我们将原型网络连接到跨模态表示,并要求它们预测每个样本的单峰嵌入到同一模态内样本的每个聚类中心的分配概率。(感觉就是先按照老方法处理文本和视频(局域网),然后连接到互联网,然后处理其他人的信息)目标是确保在使用源域上的成对数据进行训练时,通过聚类发现的类别之间的关系不会在跨模态表示中丢失。
(2) 为了最大限度地减少跨域视觉和文本分布变化的影响,我们在源域和目标域上的原型网络预测之间采用互信息最大化[29]。这旨在保留域之间的共性,同时丢弃每个域中无法从另一个域推断的信号。
本文的研究成果如下:
(1)提出了一种新的跨模态检索框架,即自适应跨模态原型(adaptivcross -modal prototype),
通过保留单模态数据中组成概念的语义结构,实现了UDA环境下的跨模态检索;
(2)我们证明,最大化源和目标跨模式原型集群分配预测之间的共现互信息是减少视觉和文本数据域转移的有效机制
(3)与仅在源域上训练的检索系统相比,我们的方法在三个图像检索数据集和三个视频检索数据集上实现了改进,
以及替代域适应策略,如最大平均差异变体[42]、对抗性学习策略[24]和运输建模[17]。
方法
问题描述
源域已配对的视觉和文本样本,目标域未配对的视觉样本,我们的目标是学习一个跨模态嵌入空间,这样当ℓ描述v时,它在域v和ℓ上的描述的距离应该嵌入得很近(意思就是,如果两个域的v和ℓ是一个描述一个,特们就该离得近),否则则要分开很远。
ADAPTIVECROSS-MODAL原型(ACP)的总体框架如图2所示,其中蓝色和红色箭头分别表示来自源域和目标域的信息流。它由六个组件组成,包括视觉和文本编码器 E v E_v Ev, E l E_l El ,单峰视觉和文字基调 K v K_v Kv, K l K_l Kl, 跨模式源和目标原型网络 P s P_s Ps, P t P_t Pt 。我们将在下面讨论这些组件及其相互作用。
单峰:感觉就是一个,比如匹配一个视频,一种类别这个意思。

按照[62]中流行的跨模态方法,我们使用视觉编码器和文本编码器ℓ映射每个可视样本和文本描述的步骤ℓ进入一个共享的交叉模态嵌入空间,Ev(v),Eℓ(ℓ)∈RM,其中当且仅当文本描述视觉输入时,视觉嵌入和文本嵌入彼此接近。我们利用源域中的成对数据强制执行双向排名损失,以对齐内容和文本描述,如下所示:
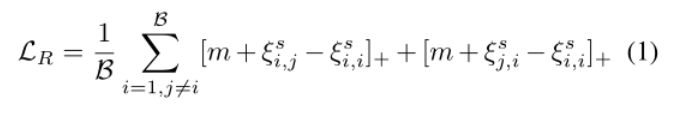
Visual and Text Keels:为了用多个视觉概念(多个单词)的组合来表示复杂的语义特征,我们建议利用每个模态中现成的结构知识来构造视觉和文本基架。
具体地说,我们首先用通用的视觉描述符和文本描述符独立地绘制单模态数据结构——这些是现成的“现成的”视觉分类和句子分类模型,它们已经经过了标签、在计算机视觉和自然语言处理社区中可用的大规模单模态数据集。
我们在每个模态内独立地用Lloyds算法[39]聚类通用描述符,生成一组质心,我们称之为视觉质心和文本质心(这个名字反映了这些质心用于稳定适应过程的意图)。
然后,我们通过计算其在所有聚类质心上的相似度分布对每个样本进行编码。这种赋值是“静态的”,即预先训练的描述符是冻结的,从不进行微调,因此赋值提供了一个领域中立(w.r.t源和目标域)信号来描述单模结构知识。
源和目标原型网络: 接下来,我们将描述如何在每个领域中使用单峰结构知识来有效地正则化跨峰嵌入的学习以进行检索。具体来说,我们将源和目标原型网络(每个都包含一个线性投影)附加到跨模式嵌入特征上,并让它们预测每个样本的聚类分配。
我们最小化KL发散损失,以惩罚该原型分配预测中的差异,因为交叉模态嵌入和由单峰龙骨确定的龙骨分配。这样做的目的是,跨模态嵌入应该保留原始单峰视觉和文本空间中的局部语义关系。
链接跨域原型: 由于原型网络分别由源样本和目标样本驱动,其分配的差异反映了域转移。这些集群分配之间的共存揭示了跨域的底层关系。具体地说,对于源和目标样本,我们通过最大化源和目标原型分配之间的互信息(MI)[29,48]来规范跨模式特征学习(即,从同一样本获得的分配应该彼此可预测,无论领域如何)。这旨在帮助以跨模态方式最大限度地减少域转移
单峰组合龙骨
与基于分类的UDA设置不同,自由格式的文本描述缺少一组明确定义的、有限的类别标签。因此,我们不能通过计算每个类别内实例的平均特征向量来形成文本框架。
我们提出用通用文本描述符编码源文本描述来绘制单模态源文本分布,并在大量自由形式句子的语料库上预先训练一个“冻结”的句子级语言模型。然后使用Lloyd的算法[39]对源文本示例的描述符进行聚类。每个集群质心被命名为文本龙骨。
然后根据文本龙骨之间的关系,通过计算其簇分配的概率,对每个源文本样本进行编码,然后计算概率。
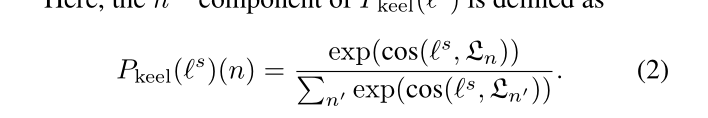
预训练语言模型的作用有两个:(1)以这种方式对语义相似的句子进行编码,每个文本簇质心表示如何使用描述片段的组合来描述一段视觉内容;(2) 为了提高泛化能力,大型、预训练语言模型表现出显著的少镜头学习能力[4],这表明由预训练模型编码的表示具有足够的可组合性,可以有效地进行泛化。
视觉龙骨构造:与文本龙骨结构类似,我们首先使用通用视觉描述符i绘制单峰视觉数据分布图。E来自单峰感知任务的预训练模型。在执行聚类算法以获得视觉龙骨后,通过计算龙骨分配概率,通过视觉龙骨{Vk}Kk=1之间的关系对每个目标视觉样本进行编码
与文本龙骨结构相比,有两个主要区别:(1)为了捕获多个视觉概念的不同组成,我们提取了多个通用视觉描述符,而不是一个,利用多个感知模型,包括用于对象分类、动作识别、场景识别的预训练模型(详情见第4.1节)。然后,每个视觉龙骨跨越以下信息:{视觉空间中的什么、如何、何处},描绘多个视觉概念的组合为了捕获目标域中存在的视觉概念的分布,视觉框架是从目标样本而不是源样本(用于文本构建)1构建的(没看懂呢)
源和目标原型网络
接下来,我们将描述如何使用源文本基架和目标视觉基架来规范共享的跨模态嵌入空间。
源原型网络:我们附加了一个源原型网络(由单个线性投影组成),
为了在交叉模态嵌入空间中整合单峰数据的结构知识,我们最小化了(5)中所示的源KL发散损失,惩罚了“龙骨分配”之间的差异,对于每一个源文本描述,我们使用从单峰文本龙骨中获得的龙骨分配作为“软标签”来指导跨峰文本嵌入的学习过程,因为可视内容与源文本样本配对
目标原型网络:任务是预测每个目标样本的典型分配,
最大化跨模态原型之间的互信息
由于缺少目标域文本标签,我们引入了更多的标签函数来限制共享错误,包括用于计算单峰龙骨分配的函数f和f,用于预测跨峰原型分配的函数f和f。更具体地说,共享误差通过三角形不等式进行限定