写作背景:前段时间看了李航的《统计学习与分析》这本书,受益良多。刚开始一味地以手写的形式记录下来,但是后来觉得这样既不环保也不利于随时查看,因此觉得有必要写成博客与大家分享与讨论。
1.感知机
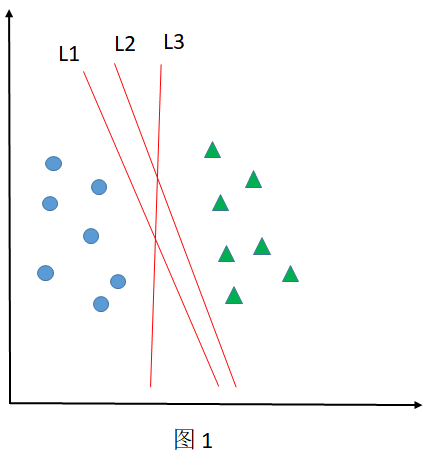
感知机是二类分类的线性模型,其目标是求得一个能够将训练数据集正实例点和负实例点完全正确分开的分离超平面,如下图所示(L1,L2和L3都可以作为分离超平面):
感知器模型为:
其中, 和 为感知机模型参数, 叫作权值或权值向量, 叫作偏置, 表示 和 的内积, 是符号函数。
损失函数
基于误分类点到超平面S的总距离
其中,
是误分类点集合。
目标函数
其中,
是误分类点集合。
学习策略(随机梯度下降法)
首先,任意选取一个超平面;然后,用梯度下降法不断极小化目标函数,在这个过程中一次随机选择一个误分类点使其梯度下降。
假设误分类点的集合
是固定的,那么损失函数
的梯度由下面的式子给出:
随机选取一个误分类点
,对
进行更新:
算法描述
输入:训练数据集
,其中
,
,
;学习率
;
输出:
;感知机模型
.
(1)选取初值
(2)在训练集中选取数据
(3)如果
(4)转至(2),直至训练集中没有误分类点。
2.支持向量机(SVM)
支持向量机是二类分类模型,它既有线性的支持向量机(线性可分支持向量机和线性支持向量机),也有非线性的支持向量机(非线性支持向量机)。
基本模型
定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;
还包括核技巧,这使它成为实质上的非线性分类器。
学习策略
“间隔最大化”
可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。
线性算法原理
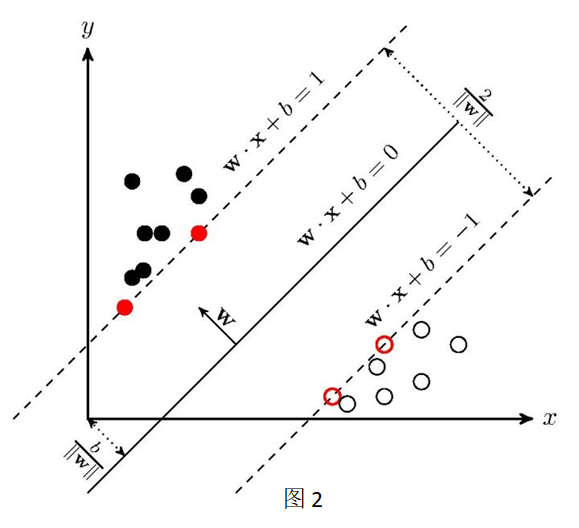
SVM学习的目标得到能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示,
即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机,见图1),但是几何间隔最大的分离超平面却是唯一的。
算法详解
假设给定一个特征空间上的训练数据集:




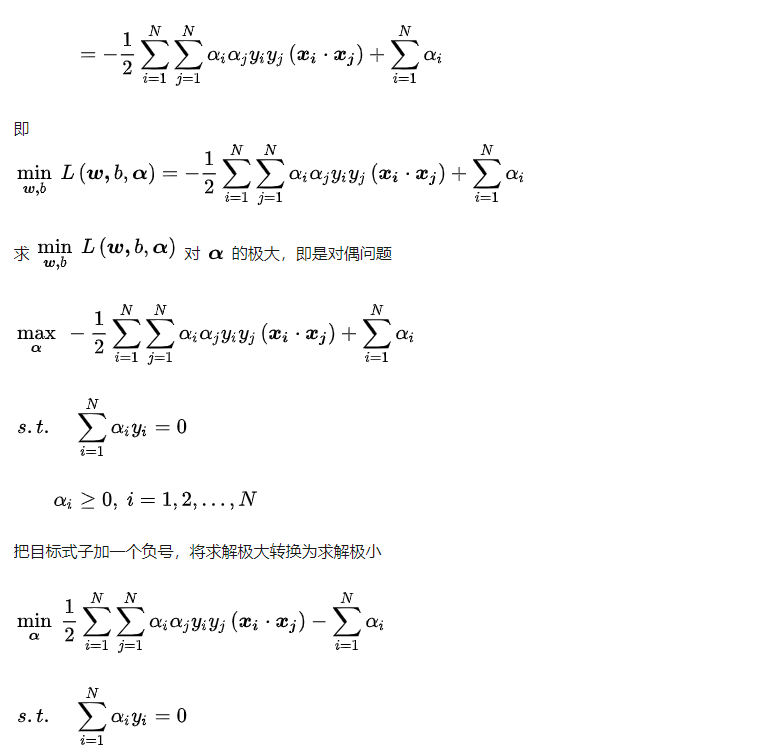




非线性SVM算法原理


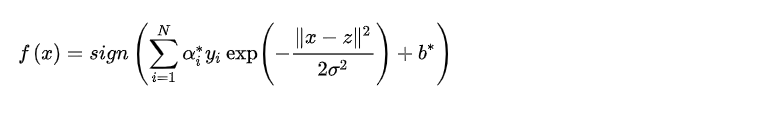
最后需要注意的是,求解 这几个参数,通常使用的是 算法,我在之前的博客有详细讲解秦刚刚的机器学习成长之路之SVM原理(SMO算法详解)
3.二者的联系
以下仅为个人观点,如有问题,欢迎大家指正_。
相同点
- 都是二类分类模型
- 都对线性可分的数据集有效
不同点
- 从本质上来讲,感知器属于神经网络的范畴,支持向量机属于机器学习
- 感知器的学习基于其收敛定理,通过收敛算法进行学习;支持向量机则是通过拉格朗日乘子法,得出一个对偶问题,再进行凸二次优化求解,得到最优分类超平面
- 对于同一个二分类问题,感知机的解不唯一(如图1所示),而支持向量机的解是唯一的(如图2所示)
- 感知机只适用于线性可分数据集,而支持向量机既适用于线性可分数据集,也在借助核方法和软间隔最大化时可以适用于线性不可分数据集
- 感知机追求最大程度正确划分,最小化误分类样本个数,很容易造成过拟合
- 支持向量机追求在大致正确分类的同时,最大化几何间隔,一定程度上避免了过拟合
- 支持向量机更加适用于现实问题