- 感知机原理:
感知机是一种线性二分类模型,其目的是找到能将训练数据线性可分的分离超平面。对于数据集T
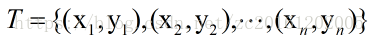
来说,存在可将数据集线线性划分的超平面S:
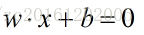
如下图所示:图一表示的直线可以将两类数据线性可分,而图二,图三则无法线性划分。

在实际问题中,并不是所有的数据都能线性可分,而我们要做到的是力求寻找到最优的超平面 S 使数据误分类点尽量最少,即损失函数最小化。又因为误分类点个数与感知机的w和b参数均其不可导,为了引入梯度下降法求取损失函数极小值,损失函数是误分类点到超平面的总距离。
样本空间中任何一点到超平面的距离可以表示为:
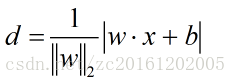
其中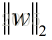

由此可见预测结果与真实结果的符号是相反的,因此,误分类点到超平面的距离可以表示为:
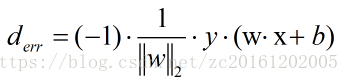
则感知机模型的损失函数表达式为:
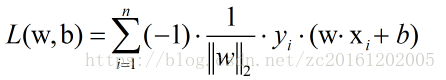
如此,感知机学习问题变成解损失函数最优化问题。而在感知机学习策略中,常用的方法是随机梯度下降法。
梯度据有方向,而L(w,b)的表达式中
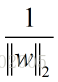
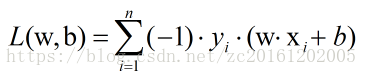
注:
- 梯度下降法求解模型:
对损失函数L(w,b)进行求偏导,可以获得:
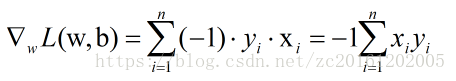
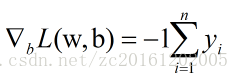
因为学习模型时会初始化权重w和偏置b,以初始化的模型来对训练数据进行分类,若没有误分类点,则表示获得的模型满足要求。若有误分类点,则根据梯度下降原理来对 w,和 b 进行更新。
- 梯度下降法原理:
梯度下降法主要有:随机梯度下降(SGD)、批量梯度下降(BGD)、小批量随机梯度下降(MSGD)三种方式。
在小数据情况下,不考虑批次问题,批次为1 。若数据量比较大,理想的状态,从训练集中随机抽取部分数据形成一批训练数据,则这一批训练数据理论上是可以代表整个数据集的,用它获得的梯度也可以代表整个数据集的梯度。各种梯度下降方法工作方式为:
- 随机梯度下降法(SGD):
随机从训练集中抽取一个样本,使用初始化的超平面来对改样本进行划分,划分正确则权重w与偏置b不作改变。若抽取的样本被分类错误,则利用梯度更新权重w和偏置b.
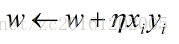
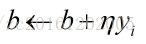
其中
优缺点:速度快,但容易收敛到局部最优,并且在某些情况下可能被困在鞍点。
#随机梯度下降,不直接用矩阵转换,换成向量计算。每次迭代只用了for循环中的一个样本。
def SGD(dataMat,labelMat):
m,n = np.shape(dataMat)
alpha = 0.02
weights = np.ones(n)
dataMat = np.array(dataMat)
error0 = 0
error1 = 0
epsilon = 1e-6
for i in range(m):
np.random.shuffle(dataMat)
h = sum(dataMat[i] * weights)
loss = h - labelMat[i]
weights -= alpha * loss * dataMat[i]
error1 += (labelMat[i] - h) ** 2 / m
if abs(error1 - error0) < epsilon: # 比较绝对值
break
else:
continue
return weights - 批量梯度下降法(BGD):
批量梯度下降法是使用当前所使用训练的所有样本来进行权重更新:


优缺点:可以获得全局最优解,但是速度慢,不适用于大量数据的情况。
def BGD(dataMat,labelMat):
dataMat = np.mat(dataMat)
labelMat = np.mat(labelMat).T
m,n = np.shape(dataMat)
alpha = 0.001
weights = np.ones((n,1))
error0 = 0
error1 = 0
epsilon = 1e-6
for i in range(m): #迭代循环最大次数
h = dataMat * weights
loss = h - labelMat
weights -= alpha * dataMat.T * loss
error1 += (labelMat[i] - h[i]) ** 2 / m
if abs(error1 - error0) < epsilon: # 比较绝对值
break
else:
continue
return weights - 小批量梯度下降法(MSGD):
小批量梯度下降是集合了随机梯度下降法与批量下降法二者的优点。从当前训练批次中随机抽取部分样本,来进行参数更新。例如:从当前训练批次m个样本中随机抽取n个样本来更新权重。
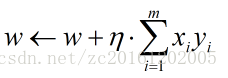
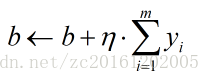
- 使用随机梯度下降法优化感知机模型
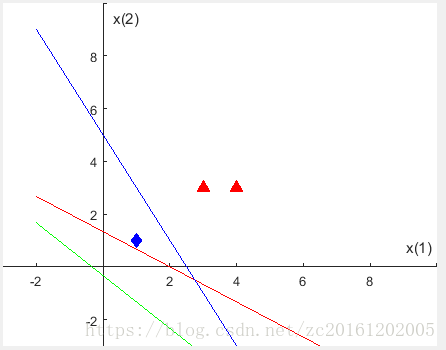
假设有样本点((x1 , x2),y), A((1,1),-1),B((3,3),1),C((4,3),1),一个负类点,两个正类点。
分界面函数为:
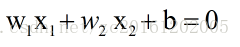
则感知机分类模型为:

该模型的损失函数表达式为:

梯度计算公式为:

使用随机梯度法求解最优模型, 则有参数优化过程为:
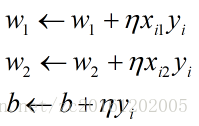
实例优化过程:
step 1 : 初始化权重:
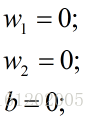
学习率(步长)alpha为1。
step 2 : 将A,B,C,D,E五个点的x1 , x2数值代入公式:
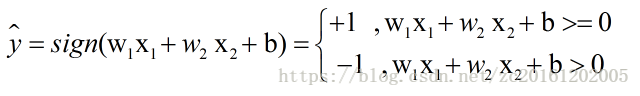
为了简化计算,只选取负类样本来进行参数优化(正常计算中是从训练样本中随机抽一个样本,先判断分类正误,再决定是否可用来优化参数。)
选取A点((3,3),1)来进行权重优化:

拿训练数据来验证:
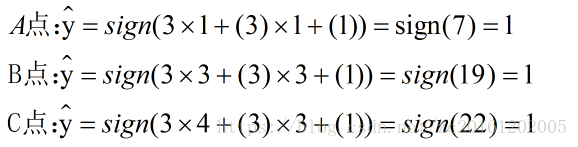
step3: 可以看出此时A点分类错误,此时选则A点来调节参数(因为随机梯度下降,样本随机选,正确分类的点无序用来调整参数):

则
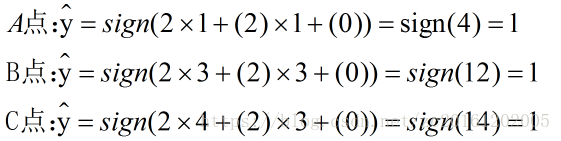
以次类推,最终可以获得最佳分界面。
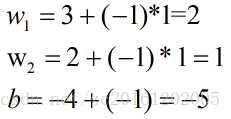
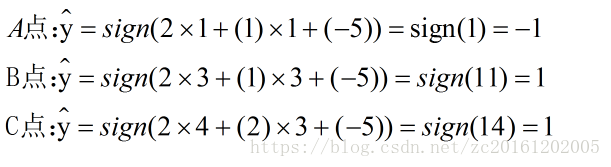
模型学习过程中,不同分界面示意图: