一,感知机模型
感知机是一种较为简单的二分类模型,但由简至繁,感知机却是神经网络和支持向量机的基础。感知机旨在学习能够将输入数据划分为+1/-1的线性分离超平面,所以感知机是一种线性模型。
由输入空间到输出空间到函数为:其中x为实例的特征向量
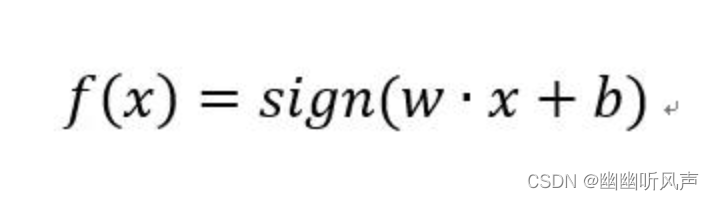
称为感知机其中w和b为感知机模型的参数,w叫做weight(权值)b叫做bias(偏置)其中sign函数为符号函数:
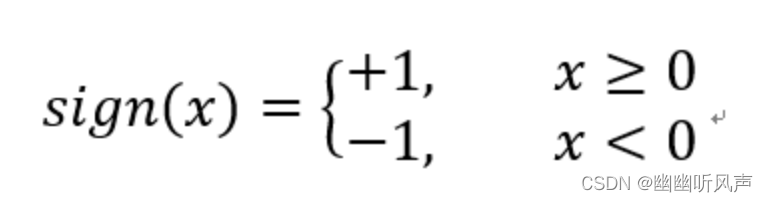

w和b构成的线性方程wx+b=0极为线性分离超平面。用这个感知机模型就是要找到一条好的直线,将数据集划分开来。
二,感知机的学习策略
首先保证数据集是线性可分的,什么叫线性可分,线性可分就是说可以用一个线性函数把两类样本分开,比如二维空间中的直线、三维空间中的平面以及高维空间中的线性函数。比如在一个二维空间中,有红球和绿球,一条直线可以将它们分开,这就说明这个数据集是线性可分的,推广到三维平面,如果一个西瓜一部分是坏掉的,另一部分是好的,切下一刀,将这两者分成两个部分,那么这在三维中就是线性可分的数据集。
下面以二维平面为例子,如何找到一个超平面(直线)?
- 一条直线不分错一个点,就是一条好的直线。
- 模型要尽可能的找到一条好的直线。
- 如果没有好的直线,那么在差的直线中找到一条好的直线。
- 判断直线有多差的方式:分错的点到直线的距离求和。
那么我们在考虑到这个距离的和的时候,会有两种距离,一种叫做函数距离,一种叫做几何距离。来自知乎Jason Gu作者的解释

因为函数距离如果同时放大或者缩小,那么这个距离就随之发生改变,但是用了几何距离会解决这个问题,||w||叫做w的L2范数。
||w|| = 求根(从1到n求和 wi^2)

很显然,损失函数L(w,b)是非负的,如果没有误分类点,那么损失函数值是0,误分类点越少,误分类点离超平面越近,那么损失函数值就越小,因此感知机的学习策略是在假设空间中选取损失函数式最小的模型参数w,b即为感知机模型。
三,感知机学习算法
现在已经知道了感知机的损失函数,感知机学习问题转化为求解损失函数式的最优化问题,最优化的方法是随机梯度下降法。x=x-nf`(x)
具体来说,我们任意选取一个超平面,由参数w0,b0表示。然后我们对w,b求梯度,我们知道梯度代表了函数下降最快的方向,那么我们沿着这个方向下降一定的距离,就可以较快的接近函数的极小值。
损失函数对w求偏导和对b求偏导会得到下面的式子:
每次梯度更新的式子为x=x-nf`(x)

下面介绍感知机的算法原始形式:

四,感知机学习算法的对偶形式
对偶形式其实是对于yixi的重复计算进行了优化,将w和b表示为实例xi和yi的线性组合的形式
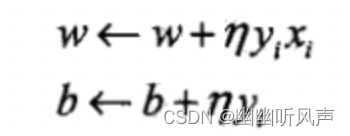
假设修改n次,那么增量为aiyixi和aiyi,这里ai=niη。 (0<η<=1)
w = w0+a1y1x1+a2y2x2+…anynxn
b = b0+a1y1+a2y2+…anyn
w0,b0初始化为0,那么

把w带入感知机模型中,此时的感知机模型为
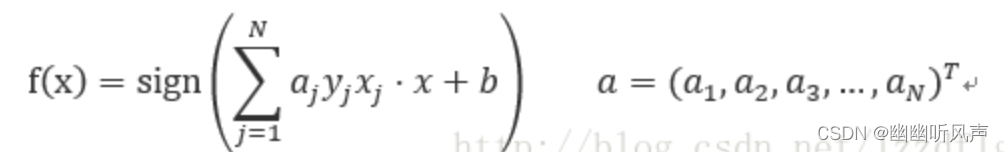
对于ai=niη ,ni是点(xi,yi)被误分类点次数,所以ai的每次增量为η
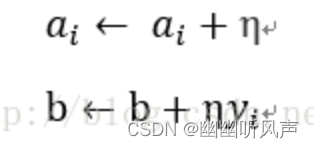
因此感知机的对偶形式算法为:

五,感知机学习算法的对偶形式例题
