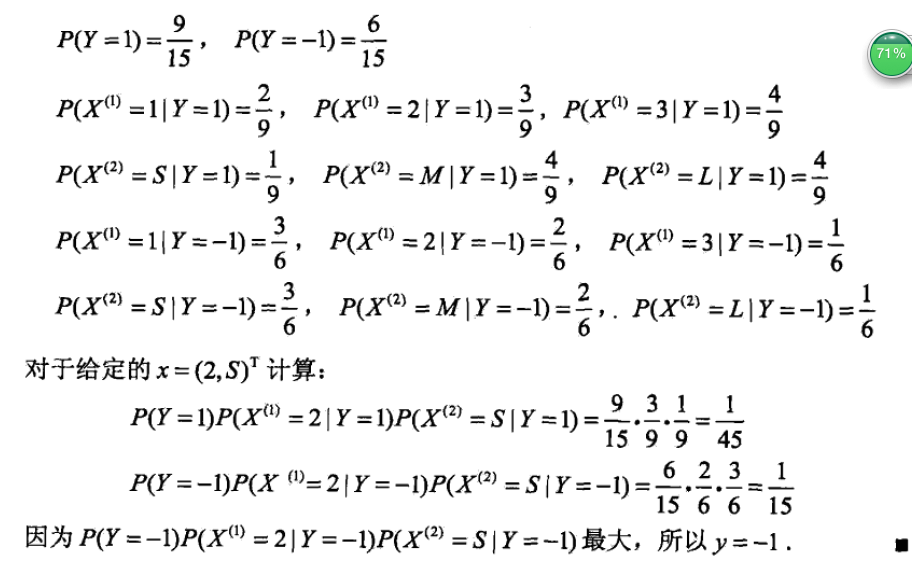版权声明:版权所属秦刚刚,转载请标明出处。谢谢^_^ https://blog.csdn.net/yzcjwddbdgg/article/details/87636194
写作背景:为了对所学知识进行一个总结,写下了秦刚刚的机器学习成长之路系列。欢迎大家的批评和指正^^
本文主要分四个部分来对朴素贝叶斯进行一个循序渐进的讲解
- 贝叶斯定理
- 特征条件独立假设
- 朴素贝叶斯估计法的参数估计
- 总结
注意: 在学习与朴素贝叶斯相关的东西时,一定要时刻清楚朴素贝叶斯的前提是假设属性相互独立!!!
1. 贝叶斯定理
贝叶斯定理是一种在已知其他概率的情况下求概率的方法。
概率论与数理统计中讲过:
由
p(x,y)=p(x∣y)⋅p(y)=p(y∣x)⋅p(x)(1)
可以推出:当先验概率
p(y)和条件概率
p(x∣y) 已知时,求后验概率
p(y∣x)的公式为
p(y∣x)=p(x)p(y)⋅p(x∣y)(2)
公式(2)就被称作贝叶斯定理。
2. 特征条件独立假设
给定训练数据集
(X,Y),其中每个样本x都包括
n维特征,即
x=(x1,x2,x3,⋯,xn),类标记集合含有
k种类别,即
y=(y1,y2,⋯,yk)。
如果现在来了一个新样本
x,我们要怎么判断它的类别?
从概率的角度来看,这个问题就是:给定
x,求它属于哪个类别的概率最大。
从而问题转化为求解
P(y1∣x),P(y2∣x),⋯,P(yk∣x)中最大的那个,即求后验概率最大的输出:
argmaxykP(yk∣x)(3)
那
argmaxykP(yk∣x)怎么求解?答案就是贝叶斯定理:
P(yk∣x)=P(x)P(yk)P(x∣yk)(4)
根据全概率公式,可以进一步地分解上式(4)中的分母:
P(yk∣x)=∑kP(x∣yk)P(yk)P(yk)P(x∣yk)(5)
对于式(4)/(5),由于对所有的
yk,分母的值都是一样的(为什么?注意到全加符号就容易理解了),所以可以忽略分母部分,所以我们只用关注分子部分。
在式(5)的分子部分中,
P(yk)是先验概率,表示训练集中类别
yk出现的概率,可以通过简单的统计计算出来;
P(x∣yk)=P(x1,x2,⋯,xn∣yk)是条件概率,表示类
yk中出现样本
x的概率,它的参数规模是指数数量级别的,假设第
i维特征
xi可取值的个数有
Si个,类别取值个数为
k个,那么参数个数为:
k∏i=1nSi (原本需求解的参数个数)
这显然不可行!!!针对这个问题,朴素贝叶斯算法对条件概率分布作出了独立性的假设,通俗地讲就是说假设各个维度的特征
x1,x2,⋯,xn互相独立,在这个假设的前提上,条件概率可以转化为:
P(x∣yk)=P(x1,x2,⋯,xn∣yk)=i=1∏nP(xi∣yk)(6)
这样,参数规模就降到
k∑i=1nSi (作出特征条件独立假设后需求解的参数个数)
以上就是针对条件概率所作出的特征条件独立性假设,至此,先验概率
P(yk)和条件概率
P(x∣yk)的求解问题就都解决了,那么我们是不是可以求解我们所要的后验概率
P(yk∣x)了?
答案是肯定的。我们继续上面关于
P(yk∣x)的推导,将公式(6)代入公式(5)得到:
P(yk∣x)=∑kP(x∣yk)P(yk)P(yk)∏i=1nP(xi∣yk)(7)
又由于对于所有的
yk,分母都为
P(x),所以可以省略,于是朴素贝叶斯分类器可表示为:
f(x)=arg maxykP(yk)i=1∏nP(xi∣yk)(8)
至此,朴素贝叶斯分类器的两个基本前提–贝叶斯定理和特征条件独立假设已全部讲解完毕,同时,此时朴素贝叶斯法的大体也已经完全呈现了出来。
3. 朴素贝叶斯估计法的参数估计
3.1 极大似然估计
在朴素贝叶斯法中,学习意味着估计
P(Y=ck)和
P(X(j)=x(j)∣Y=ck).可以应用极大似然估计法估计相应的概率。先验概率
P(Y=ck)的极大似然估计是
P(Y=ck)=N∑i=1NI(yi=ck),k=1,2,⋯,K(9)
其中
N表示训练数据集的大小,
K表示类别数目。
设第
j个特征
x(j)可能取值的集合为
{aj1,aj2,⋯,ajSj},条件概率
P(X(j)=ajl∣Y=ck)的极大似然估计是
P(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ck)∑i=1NI(xi(j)=ajl,yi=ck)(10)
j=1,2,⋯,n;l=1,2,⋯,Sj;k=1,2,⋯,K
式(10)中,
xi(j)是第
i个样本的第
j个特征;
ajl是第
j个特征可能取的第
l个值;
I为指示函数。
3.2 朴素贝叶斯算法及例题
下面给出朴素贝叶斯法的学习与分类算法。
算法:朴素贝叶斯算法
输入:训练数据
T={(x1,y1),(x2,y2),⋯,(xN,yN)},其中
xi=(xi(1),xi(2),⋯,xi(n))T,
xi(j)是第
i个样本的第
j个特征,
xi(j)∈{aj1,aj2,⋯,ajSj},
ajl是第
j个特征可能取的第
l个值,
j=1,2,⋯,n; l=1,2,⋯,Sj; yi∈{c1,c2,⋯,cK};实例
x;
输出:实例
x的分类;
步骤(1):计算先验概率及条件概率
P(Y=ck)=N∑i=1NI(yi=ck),k=1,2,⋯,K
P(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ck)∑i=1NI(xi(j)=ajl,yi=ck)
j=1,2,⋯,n;l=1,2,⋯,Sj;k=1,2,⋯,K
步骤(2):对于给定的实例
x=(x(1),x(2),⋯,x(n))T,计算
P(Y=ck)i=1∏nP(X(j)=x(j)∣Y=ck),k=1,2,⋯,K
步骤(3):确定实例
x的类
y=arg maxckP(Y=ck)i=1∏nP(X(j)=x(j)∣Y=ck)
=====================================================================================
例题1
该例题来自于李航《统计学习方法》一书
3.3 贝叶斯估计及例题
用极大似然估计可能会出现索要估计的概率值为0的情况。这是会影响到后验概率的计算结果,使分类产生偏差。解决这一问题的方法是采用贝叶斯估计。具体地,条件概率的贝叶斯估计是
Pλ(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ci)+Sjλ∑i=1NI(xi(j)=ajl∣yi=ck)+λ)(11)
式中
λ≥0.等价于在随机变量各个取值的频数上赋予一个正数
λ>0。当
λ=0时就是极大似然估计。常取
λ=1,这是称为拉普拉斯平滑。显然,对任何
l=1,2,⋯,Sj;k=1,2,⋯,K,有:
Pλ(X(j)=ajl∣Y=ck)>0
l=1∑SjP(X(j)=ajl∣Y=ck)=0(12)
表明式(11)确为一种概率分布。同样,先验概率的贝叶斯估计为
Pλ(Y=ck)=N+Kλ∑i=1NI(yi=ci)+λ(13)
=====================================================================================
例题2
该例题来自于李航《统计学习方法》一书
附加:如果还想要通过例题深入朴素贝叶斯法,可以直接百度一下“检验SNS在社区中的不真实账号”例子。
4. 总结
至此,我已经将朴素贝叶斯法的主要内容讲解完毕了,下面这段话是我结合自身理解以及总结收集的资料对朴素贝叶斯法所作的一个总结,分别阐述一下该方法的优缺点。
| 优点 |
| 1.有稳定的分类效率 |
| 2.适合增量式训练(对小规模数据表现很好,也能处理多分类任务) |
| 3.算法简单,对确实数据不敏感,常用于文本分类 |
| 缺点 |
| 1.朴素贝叶斯假设属性之间相互独立(即特性条件独立假设),实际应用中这点往往不成立 |
| 2.需要知道先验概率,而此取决于假设模型(例如:高斯模型,多项式模型,伯努利模型等) |
| 3.存在一定的错误率(通过先验和数据决定后验概率,从而决定分类) |
| 4.对输入的表达形式很敏感 |