在本练习中,您将使用牛顿方法对分类问题实现逻辑回归。
首先,下载data2.zip并从zip文件中提取文件。 在本练习中,假设一所高中有一个数据集,该数据集表示40名被大学录取的学生和40名未被录取的学生。 每个
(
x
(
i
)
;
y
(
i
)
)
(x(i) ;y(i))
( x ( i ) ; y ( i ) )
x
x
x
y
y
y
将训练样例的数据加载到程序中,并将
x
0
=
1
x_0 = 1
x 0 = 1
x
x
x
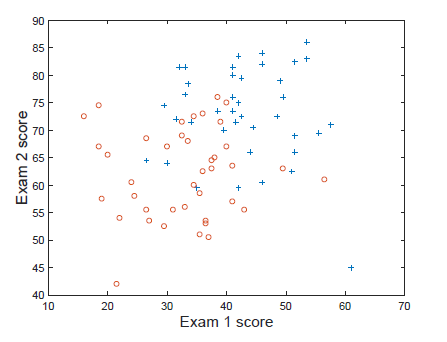
% find返回满足指定条件的行的索引
pos = find ( y == 1 ) ; neg = find ( y == 0 ) ;
% Assume the features are in the 2 nd and 3 rd columns of x
plot ( x ( pos , 2 ) , x ( pos , 3 ) , '+' ) ; hold on
plot ( x ( neg , 2 ) , x ( neg , 3 ) , ' o ' )
你画的应该如下所示
回想一下逻辑回归,假设函数为
(1)
h
θ
(
x
)
=
g
(
θ
T
x
)
=
1
1
+
e
−
θ
T
x
=
P
(
y
=
1
∣
x
;
θ
)
h _ { \theta } ( x ) = g \left( \theta ^ { T } x \right) = \frac { 1 } { 1 + e ^ { - \theta ^ { T } x } } = P ( y = 1 | x ; \theta ) \tag{1}
h θ ( x ) = g ( θ T x ) = 1 + e − θ T x 1 = P ( y = 1 ∣ x ; θ ) ( 1 )
g = inline ( '1.0 ./ (1.0 + exp(-z))' ) ;
% Usage: To find the value of sigmoid
% evaluated at 2 , call g ( 2 )
给定一个训练集
{
x
(
i
)
}
i
=
1
,
…
,
m
\{x^{(i)}\}_{i=1,\dots,m}
{ x ( i ) } i = 1 , … , m
(2)
J
(
θ
)
=
∏
i
=
1
m
(
h
θ
(
x
(
i
)
)
)
y
(
i
)
(
1
−
h
θ
(
x
(
i
)
)
)
1
−
y
(
t
)
J ( \theta ) = \prod _ { i = 1 } ^ { m } \left( h _ { \theta } \left( x ^ { ( i ) } \right) \right) ^ { y ^ { ( i ) } } \left( 1 - h _ { \theta } \left( x ^ { ( i ) } \right) \right) ^ { 1 - y ^ { ( t ) } } \tag{2}
J ( θ ) = i = 1 ∏ m ( h θ ( x ( i ) ) ) y ( i ) ( 1 − h θ ( x ( i ) ) ) 1 − y ( t ) ( 2 )
(3)
L
(
θ
)
=
1
m
∑
i
=
1
m
[
y
(
i
)
log
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
h
θ
(
x
(
i
)
)
)
]
L ( \theta ) = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } \left[ y ^ { ( i ) } \log \left( h _ { \theta } \left( x ^ { ( i ) } \right) \right) + \left( 1 - y ^ { ( i ) } \right) \log \left( 1 - h _ { \theta } \left( x ^ { ( i ) } \right) \right) \right] \tag{3}
L ( θ ) = m 1 i = 1 ∑ m [ y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] ( 3 )
(4)
min
θ
L
(
θ
)
=
1
m
∑
i
=
1
m
[
−
y
(
i
)
log
(
h
θ
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
log
(
1
−
h
θ
(
x
(
i
)
)
)
]
\min _ { \theta } L ( \theta ) = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } \left[ - y ^ { ( i ) } \log \left( h _ { \theta } \left( x ^ { ( i ) } \right) \right) - \left( 1 - y ^ { ( i ) } \right) \log \left( 1 - h _ { \theta } \left( x ^ { ( i ) } \right) \right) \right] \tag{4}
θ min L ( θ ) = m 1 i = 1 ∑ m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] ( 4 )
∇
θ
L
\nabla_\theta L
∇ θ L
L
L
L
(5)
∇
θ
L
=
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
(
i
)
\nabla _ { \theta } L = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } \left( h _ { \theta } \left( x ^ { ( i ) } \right) - y ^ { ( i ) } \right) x ^ { ( i ) } \tag{5}
∇ θ L = m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) ( 5 )
θ
\theta
θ
(6)
θ
←
θ
−
α
∇
θ
L
(
θ
)
\theta \leftarrow \theta - \alpha \nabla _ { \theta } L ( \theta ) \tag{6}
θ ← θ − α ∇ θ L ( θ ) ( 6 )
(7)
∣
L
+
(
θ
)
−
L
(
θ
)
∣
≤
ϵ
\left| L ^ { + } ( \theta ) - L ( \theta ) \right| \leq \epsilon \tag{7}
∣ ∣ L + ( θ ) − L ( θ ) ∣ ∣ ≤ ϵ ( 7 )
θ
=
0
\theta = 0
θ = 0
假设
ϵ
=
1
0
−
6
\epsilon = 10 ^ { - 6 }
ϵ = 1 0 − 6
收敛后得到的
θ
\theta
θ
计算每次迭代过程中的
L
(
θ
)
L(\theta)
L ( θ )
L
(
θ
)
L(\theta)
L ( θ )
收敛之后,使用
θ
\theta
θ
P
(
y
=
1
∣
x
;
θ
)
=
g
(
θ
T
x
)
=
0.5
P(y=1|x;\theta) = g(\theta^Tx) = 0.5
P ( y = 1 ∣ x ; θ ) = g ( θ T x ) = 0 . 5
θ
T
x
=
0
\theta^Tx = 0
θ T x = 0
θ
T
x
=
0
\theta^Tx = 0
θ T x = 0
测试1的成绩为20分和测试2为80分的学生不被录取的概率是多少?
我们的目标是使用牛顿方法去最小化这个函数。回想一下牛顿方法的更新规则是
θ
(
t
+
1
)
=
θ
(
t
)
−
H
−
1
∇
θ
L
\theta ^ { ( t + 1 ) } = \theta ^ { ( t ) } - H ^ { - 1 } \nabla _ { \theta } L
θ ( t + 1 ) = θ ( t ) − H − 1 ∇ θ L
(8)
H
=
1
m
∑
i
=
1
m
[
h
θ
(
x
(
i
)
)
(
1
−
h
θ
(
x
(
i
)
)
)
x
(
i
)
(
x
(
i
)
)
T
]
H = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } \left[ h _ { \theta } \left( x ^ { ( i ) } \right) \left( 1 - h _ { \theta } \left( x ^ { ( i ) } \right) \right) x ^ { ( i ) } \left( x ^ { ( i ) } \right) ^ { T } \right] \tag{8}
H = m 1 i = 1 ∑ m [ h θ ( x ( i ) ) ( 1 − h θ ( x ( i ) ) ) x ( i ) ( x ( i ) ) T ] ( 8 )
x
(
i
)
∈
R
n
+
1
,
x
(
i
)
(
x
(
i
)
)
T
∈
R
(
n
+
1
)
×
(
n
+
1
)
x^{(i)} \in R^{n+1}, x^{(i)}(x^{(i)})^T \in R^{(n+1) \times (n+1)}
x ( i ) ∈ R n + 1 , x ( i ) ( x ( i ) ) T ∈ R ( n + 1 ) × ( n + 1 )
h
θ
(
x
(
i
)
)
h_\theta(x^{(i)})
h θ ( x ( i ) )
y
(
i
)
y^{(i)}
y ( i )
θ
=
0
\theta = 0
θ = 0
L
(
θ
)
L(\theta)
L ( θ )
当收敛时
θ
\theta
θ
显示牛顿法中
L
L
L
画出决策边界
测试1的成绩为20分和测试2为80分的学生不被录取的概率是多少?
对比梯度下降法和牛顿法,你学到了什么?