1.使用信息熵,基尼寻找最优划分
2.使用决策树解决回归问题
模拟使用信息熵划分:
这里我们模拟使用信息熵进行划分,信息熵公式如下:
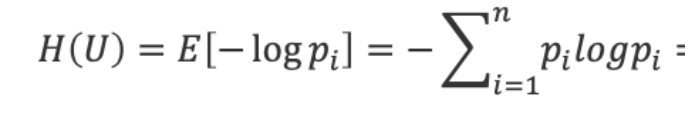
首先对每个属性尝试分类并计算出信息熵,从结果可以看出第0维度的信息熵最小,即纯度最高,为0.462.

所以我们接下来用第0维度的属性进行决策划分,可以看出划分后的左子树的信息熵为0,即全属于一个类,右子树的信息熵为0.693.

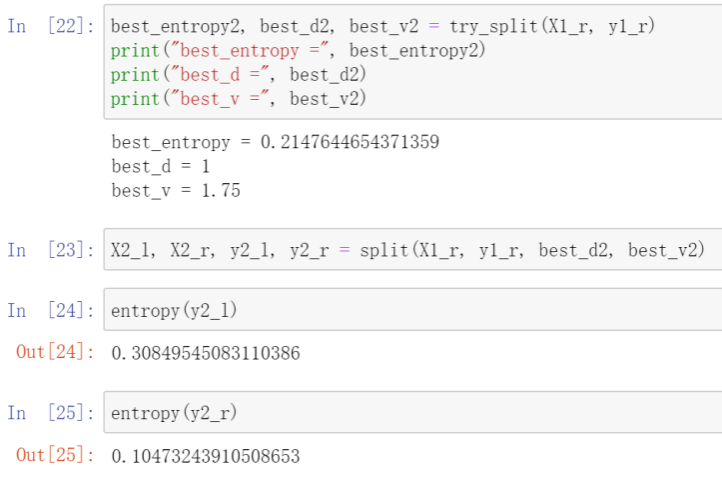
所以接下来我们只用对右子树进行划分,我们开始尝试对右子树进行决策划分,从结果可以看出第1维度的信息熵最小,即纯度最高,为0.214.所以我们接下来用第1维度的属性进行决策划分,可以看出划分后的左子树的信息熵为0.308,右子树的信息熵为0.104.
模拟使用基尼系数划分:
这里的代码跟模拟信息熵的差不多,只是讲指标改为基尼系数,基尼子树如下:
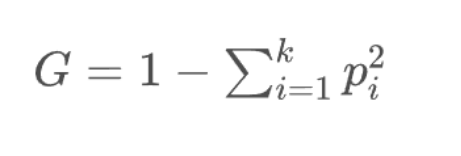
首先对每个属性尝试分类并计算出信息熵,从结果可以看出第0维度的信息熵最小,即纯度最高,为0.333.所以我们接下来用第0维度的属性进行决策划分,可以看出划分后的左子树的信息熵为0,即全属于一个类,右子树的信息熵为0.5.所以接下来我们只用对右子树进行划分,我们开始尝试对右子树进行决策划分,从结果可以看出第1维度的信息熵最小,即纯度最高,为0.110.所以我们接下来用第1维度的属性进行决策划分,可以看出划分后的左子树的信息熵为0.168,右子树的信息熵为0.042.

决策树解决回归问题:
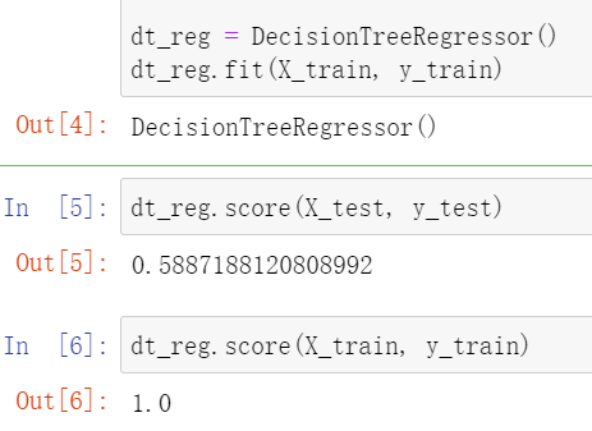
这里我们使用决策树进行回归问题,将数据集划分为训练集和测试集后,我们用决策树进行训练并分别训练集和测试集查看得分:可以看出在训练集上得分为1.0,但是在测试集上得分只有0.588,比较低,说明可能出现了过拟合现象。
使用信息熵寻找最优划分:
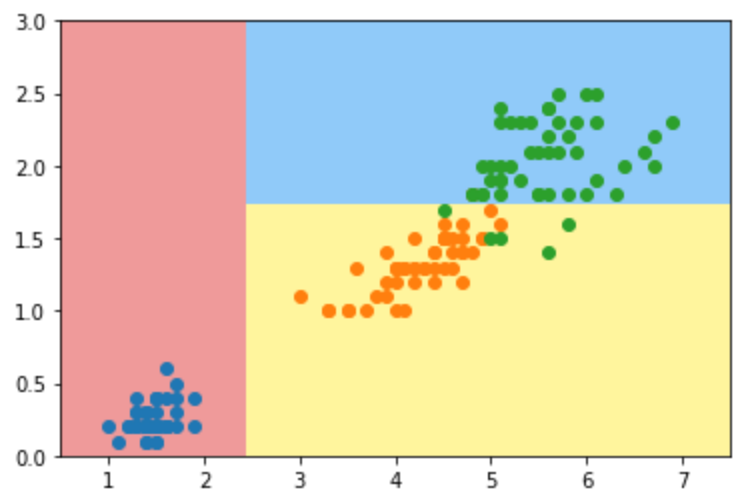
下图为我们使用sklearn中的决策树进行训练,DecisionTreeClassifier(max_depth=2,criterion="entropy",random_state=42),其中决策树最大深度,即树的层数为2;特征选择标准为信息熵。然后绘制出图像,如下图所示。可以发现单变量的决策树的决策边界都是与坐标轴平行,在这个数据集还可以较好的分类。

基尼系数:
下图为我们使用sklearn中的决策树进行训练,DecisionTreeClassifier(max_depth=2,criterion="gini",random_state=42),其中决策树最大深度,即树的层数为2;特征选择标准为基尼系数。然后绘制出图像,如下图所示。可以发现在这个数据集下,由基尼系数决定的分类边界与信息熵决定的分类边界相差不大。
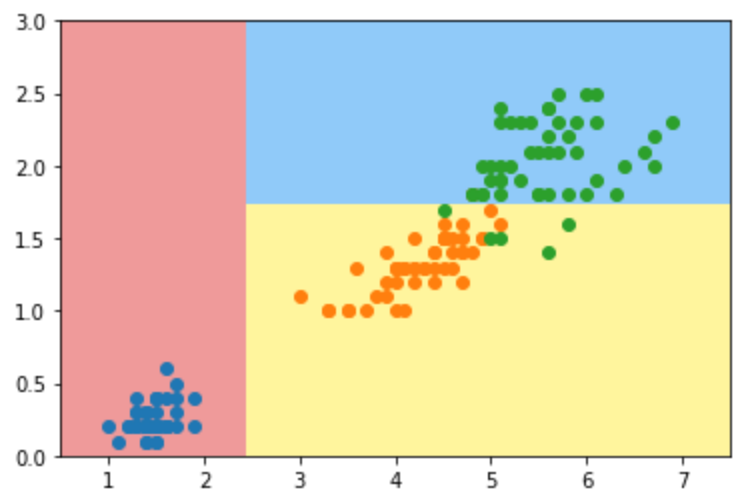
CART 和 决策树的超参数:
下图为sklearn中的make_moons数据集,并将噪声设置为0.25,散点图如下所示:

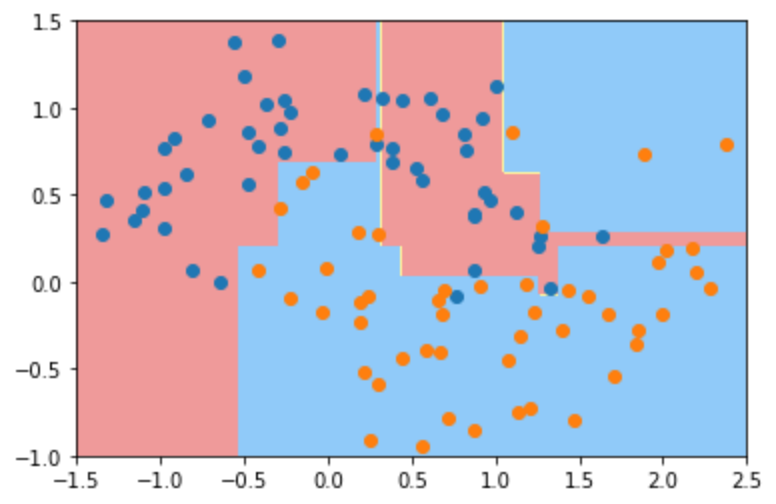
然后我们用sklearn中的决策树进行训练,其中分类器使用默认的参数,即不限制最大深度等等,得到的分类边界如下,可以发现这个决策边界形状相对不规则,发生了过拟合。
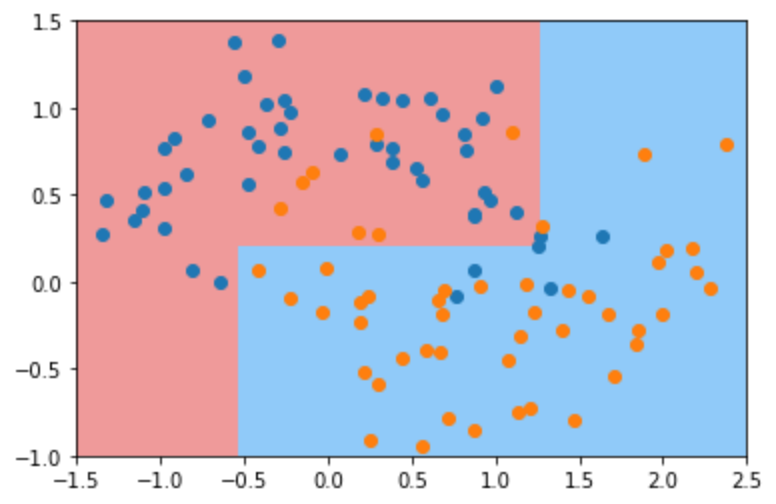
这里我们限制决策树的最大深度为2,此时绘制出来的决策边界非常清晰,没有那种特别不规则的边界。决策树模型不会针对某几个特别的样本点进行特殊的变化。相对于前面默认参数的决策树,显然指定参数max_depth = 2 的决策树模型的过拟合程度降低。当然此时的模型又可能欠拟合。
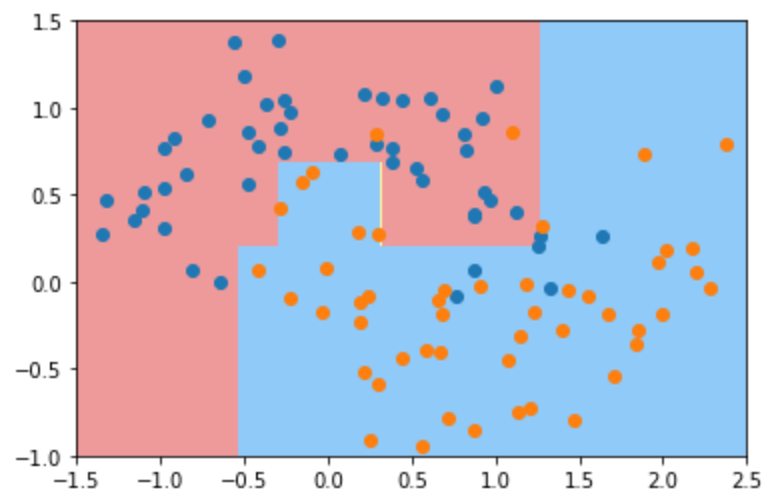
然后我们调整对于一个节点至少要有10个样本数据才对这个节点继续拆分下去,此时的决策边界比较合理,相比较于最大深度为2的,不在欠拟合。显然,将 min_samples_split 参数的值设置的越低,决策树模型越容易发生过拟合。 考虑极端情况下,如果将 min_samples_split 设置的值大于等于样本总数,此时仅有的根节点不需要进行划分,显然此时仅有一个根节点的决策树模型欠拟合。
然后我们调整对于一个叶子节点至少有6个样本,同上一个一样,该决策边界效果比较好,过拟合与欠拟合都不大明显。显然,将 min_samples_leaf 参数的值设置的越低,决策树模型越容易发生过拟合。 考虑极端情况下,如果将 min_samples_leaf 设置为 1,对于只有一个样本点的叶子节点,在具体预测的时候,测试样本点需要根据所到达的叶子节点上的样本点来决定预测的类别(或目标),而如果此时叶子节点仅有一个样本点,那么测试样本点非常容易受到这一个样本点的影响,测试样本点的预测类别(或目标)会变得非常敏感。
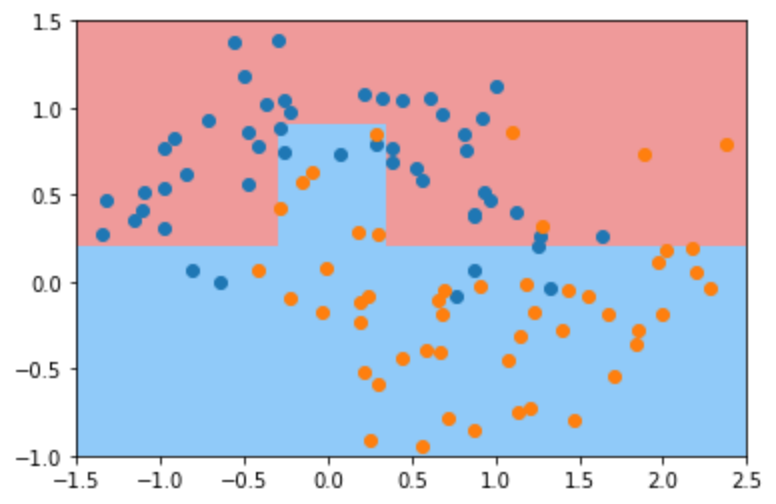
然后我们调整最多可以有4个叶子节点,发现该决策边界也比较简单,可能存在欠拟合现象,显然,将 max_leaf_nodes 参数的值设置的越高,决策树模型越容易发生过拟合。

策树的问题:
这是之前运用决策树得到的分类边界,跟之前一样。
我们将数据集中的一个第138行数据删除,然后运用决策树得到的分类边界如下:所以我们可以发现决策树对样本数据中的个别数据非常敏感,这个敏感体现在如果对样本数据进行少许改动,决策边界都会发生巨大改变。

决策树算法的优点:
既可以用于分类又可以用于回归
天生可以处理多分类问题,不需要进行特殊处理。
基本不需要预处理,不需要提前归一化和处理缺失值,既可以处理离散值也可以处理连续值
不容易受数据中异常值影响,鲁棒性好
集成学习:现在很多强大的集成学习器都是以决策树为基学习器的,如随机森林,GBDT,Adaboost
可作为有效工具来帮助其他模型挑选特征
简单直观,解释性强。(可以将决策树看成一个if-then规则的集合:由决策树的根结点到叶结点的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。)
可以交叉验证的剪枝来选择模型,从而提高泛化能力。
对数据分布没有特别严格的要求,可以同时发现数据中线性和非线性的关系
使用决策树预测的代价是O(log2m)。 m为样本数。
决策树算法的缺点:
容易过拟合,泛化能力不强。可以通过剪枝、设置节点最少样本数量、限制决策树深度来改进。
决策树为非参数学习,对个别数据敏感,样本发生一点点的改动,就会导致树结构的剧烈改变。可通过集成学习之类的方法解决。
寻找最优的决策树是一个NP难的问题,一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。可以通过调节样本权重来改善。
有些比较复杂的关系,决策树很难学习,比如异或。可以换神经网络分类方法来解决。