1. 描述
第一个练习将为你提供线性回归练习。这些练习已经用Matlab进行了广泛的测试,但它们也应该在Octave中工作,它被称为“免费版的Matlab”。如果你使用的是Octave,那就是
一定要安装Image包(可在Windows中作为选项使用)安装程序,可从Octave-Forge获得Linux。
2.线性回归
回想一下,线性回归模型是
其中
是我们需要优化的参数,
是
- 维特征向量。给定一个训练集,
,我们的目标是找出
最佳值,使得目标函数
如图等式可以最小化
优化方法之一是梯度下降算法。算法迭代执行,并在每次迭代中,我们更新
遵循以下规则
其中
是所谓的学习率,基于我们可以调整收敛梯度下降。
表示对应
的系数。
3. 2D线性回归
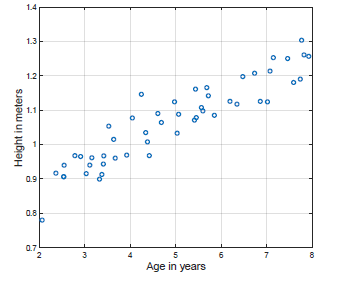
我们开始一个非常简单的情况,其中 .下载data1.zip,并解压缩文件(ex1x.dat和ex1y.dat)。这些文件包含一些测量身高的例子,对象是两岁到八岁之间的男孩。 值是以米为单位测量的高度, 值是对应于高度的男孩年龄。每个高度和年龄元组构成一个训练样例子 在我们的数据集中。有m = 50的训练例子,您将使用它们来开发使用梯度下降算法的线性回归模型,基于此,我们可以预测给定新年龄值的高度。在Matlab / Octave中,您可以使用命令加载训练集。
x = load ( ' ex1x . dat ' ) ;
y = load ( ' ex1y . dat ' ) ;
这将是我们针对 的监督学习问题的训练集功能(除了通常的 ,所以 )。 如果您正在使用Matlab / Octave,运行以下命令绘制训练集(并标记轴)
figure % open a new figure window
plot (x , y , ' o ' ) ;
ylabel ( ' Height in meters ' )
xlabel ( 'Age in years ' )
您应该看到一系列类似于图1的数据点。
m = length ( y ) ; % store the number of training examples
x = [ ones (m, 1 ) , x ] ; % Add a column of ones to x
从这一点开始,从这一点开始,您需要记住训练数据中的年龄值实际上位于x的第二列。 这在以后绘制结果时很重要。
我们为这个问题实现了线性回归。 线性回归模型在这种情况下是
(1)使用
的学习率实施梯度下降。初始化参数
,并从该初始起点开始一次梯度下降迭代。 记录第一次迭代后得到的
和
的值。
(2)继续运行梯度下降以进行更多迭代,直到
收敛为止(这将总共需要大约1500次迭代)。收敛后,记录你得到的最终值
和
,根据
,将你的算法中的直线绘制在与训练数据相同的图表上.绘图命令看起来像这样:
hold on % Plot new data without clearing old plot
plot ( x ( : , 2 ) , x*theta , '-' ) % remember that x is now a matrix
% with 2 columnsand the second
% column contains the time info
legend( ' Training data ' , ' Linear regression ' )
请注意,对于大多数机器学习问题,x是非常高的维度,因此我们无法绘制
,但是因为在这个例子中我们只有一个功能,能够绘制这个给我们一个很好的理智检查我们的结果。
(3)最后,我们想使用学到的假设做出一些预测。使用您的模型预测两个3.5岁和7岁男孩的身高。
4.理解
我们想更好地理解梯度下降的作用,并可视化参数
和
之间的关系。在这个问题中,我们将
制为3D表面图。(当应用学习算法时,我们不会通常尝试绘制
,因为通常
是非常高维的,所以我们没有任何简单的方法来绘制或可视化
, 但因为这个例子这里使用一个非常低维
,我们将绘制
获得更多的直觉关于线性回归。)
要在曲面图上获得最佳查看结果,请使用我们在下面的代码框架中建议的
值范围。
J_vals = zeros (100 , 100) ; % initialize Jvals to
% 100*100 matrix of 0's
theta0_vals = linspace (-3 , 3 , 100) ;
theta1_vals = linspace (-1 , 1 , 100) ;
% 对于linespace(x1,x2,N),其中x1、x2、N分别为起始值、终止值、元素个数。
for i = 1 : length (theta0_vals)
for j = 1 : length (theta1_vals )
t = [theta0_vals(i); theta1_vals(j)] ;
J_vals(i,j) = %% YOUR CODE HERE %%
end
end
% Plot the surface plot
% Because of the way meshgrids work in the surf command , we
% need to t ranspose J_vals before calling surf , or else the
% axes will be flipped
Jval_s = Jval_s'
figure ;
surf(theta0_vals,theta1_vals,J_vals)
xlabel ('\theta_0 ');ylabel('\theta_1')

你应该得到类似于图2的图形。如果你使用Matlab / Octave,你
可以使用轨道工具从不同的视点查看此图。
这个3D表面与其值之间的关系是什么?你实现梯度下降的
和
是什么?通过冲浪和轮廓命令可视化关系。
备注:对于冲浪函数surf(x,y,z),如果x和y是向量,则x = 1:列(z)和y = 1:行(z)。 因此,实际上基于x(j)和y(i)计算z(i; j)。 该规则也适用于轮廓功能。 我们可以通过引入不同的间隔矢量,例如线性间隔矢量(空间)和对数间隔矢量(对数空间)来指定轮廓函数中轮廓的数量和分布。 在本练习中尝试两种方法,并选择更好的方法来改进插图。
5.多元线性回归
我们现在看一个更复杂的情况,其中每个训练数据包含多个特征。下载data1.zip,并从zip文件解压缩文件(ex2x.dat和ex2y.dat)。这是俄勒冈州波特兰市的一套房价培训,其中输出y是价格,输入x是生活区域卧室的数量。有m = 47个训练样例。
看一下输入x(i)的值,并注意生活区域大约是卧室数量的1000倍。 这种差异意味着预处理输入将显著提高梯度下降的效率。
在你的程序中,按标准偏差和比例缩放两种类型的输入将他们的方法设定为零。在Matlab / Octave中,这可以用
sigma = std ( x ) ;
mu = mean( x ) ;
x ( : , 2 ) = ( x ( : , 2 ) - mu( 2 ) ) . / sigma ( 2 ) ;
x ( : , 3 ) = ( x ( : , 3 ) - mu( 3 ) ) . / sigma ( 3 ) ;
5.1 使用J(θ)选择学习率
现在是时候选择学习率
了。 这部分的目标是选择一个好的学习率在如下范围
您将通过进行初始选择,运行梯度下降、观察成本函数,并相应地调整学习率。回想起在等式(2)中定义的成本函数。成本函数也可以以下面的矢量化形式写成
其中
当您使用Matlab / Octave等数值计算工具时,矢量化版本非常有用且高效。 如果您熟悉矩阵,您可以证明这两种形式是等价的
在上一个练习中,您在
和
的网格上计算出了
,现在使用当前梯度下降阶段的
计算
。单步执行多个阶段后,您将看到
随着迭代的进展而变化。
现在,以初始学习速率运行梯度下降约50次迭代。 在每次迭代中,计算
并将结果存储在矢量
中。在最后一次迭代之后,将
值绘制为迭代次数。 在Matlab / Octave中,步骤看起来像这样:
theta = zeros ( size ( x ( 1 , : ) ) ) ' ; % initialize fitting parameters
alpha = %% Your initial learning rate %%
J = zeros (50 , 1 ) ;
for num_iterations = 1:50
J ( num_iterations ) = %% Calculate your cost function here %%
theta = %% Result of gradient descent update %%
end
% now plot J
% technically , the first J starts at the zero-eth iteration
% but Matlab/Octave doesn ' t have a zero index
figure ;
plot ( 0 : 49 , J ( 1 : 50 ) , '-' )
xlabel ( 'Number of iterations ' )
ylabel ( ' Cost J ' )
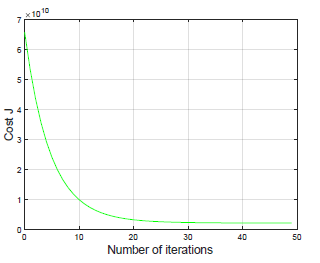
如果你选择了一个很好的范围内的学习率,你的图应该是如下图这样的。
plot ( 0 : 49 , J1 ( 1 : 50 ) , 'b-' ) ;
hold on ;
plot ( 0 : 49 , J2 ( 1 : 50 ) , ' r-' ) ;
plot ( 0 : 49 , J3 ( 1 : 50 ) , 'k-' ) ;
最后的参数’b-’,'r-'和’k-'为图表指定了不同的绘图样式。键入
help plot
Matlab / Octave命令行以获取有关打印样式的更多信息。
回答下列问题
- 随着学习率的变化,观察成本函数的变化。当学习率太小时会发生什么?太大了?
- 使用您找到的最佳学习率,运行梯度下降直到收敛找到
(a) 的最终值
(b)1650平方英尺和3间卧室的房屋预计价格。
进行此预测时,请不要忘记扩展功能!