练习使用支持向量机进行线性和非线性分类。
使用SMO算法,基于SVM识别手写数字。
SVM:
利用训练数据绘制SVM的决策边界。
使用测试数据来评估SVM分类器,并显示被错误分类的测试示例的比例
尝试正则化术语C的不同值,并报告你的观察结果。
手写数字识别:
第二部分是应用你的SVM分类器来识别手写的数字。在train-01-image.svm和test-01-images.svm中已经给出了用于训练和测试的数据集。为了简化事情,我们只区分0和1。训练数据集包含12665张图像,而测试数据集包含2115张图像。每一行代表一个图像,其中第一项是标签,而下面的第一项是像素的索引和相应的灰度值。注意,只给出灰度值的像素。您可以从给定的图像中提取本地二进制模式(LBP)特征1,或者对图像进行降采样,以减少必须处理的特征的数量。请仔细阅读并尝试阅读。这里给出了如何处理数据的例子。在报告中显示一些数据示例。通过训练数据来训练你的SVM模型,并应用它来识别测试数据集中给出的手写数字。

非线性SVM:
现在使用γ值分别为1、10、100和1000来训练您的模型,并为每个模型绘制决策边界(不使用等高线填充)。
SVM的实现就根据课上给出的公式计算:

然后我们将其转换成对偶问题,利用拉格朗日乘子处理待约束问题:

启用非线性SVM的一种方法是引入内核,线性不可分特征在映射到高维特征空间后往往会变成线性可分。不需要显式地计算特性映射φ(x(i)):只需要处理它们的内核,这更容易计算。高斯核公式如下:

SVM:
首先我们绘制训练数据集1 的散点图,可以发现两个类别之间的间隔较大,有明显的分界线存在,并且可以用线性SVM就可以解决。
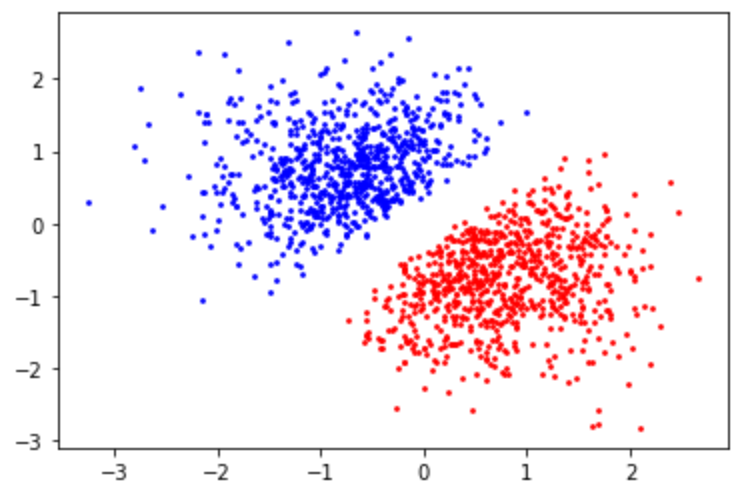
们用sklearn中的线性SVM进行训练并绘制决策边界,其中惩罚项系数C=1,发现决策边界有较好的效果,然后用测试集进行训练,发现正确率为1,即错误率为0。同时我们改变惩罚项系数再次训练,令C=0.001,然后用测试集进行训练,还是发现正确率为1,即错误率为0。



面是更多C 的取值以及对应分数:

然后我们绘制训练数据集2的散点图,可以发现两个类别之间的间隔较小,用线性SVM可能存在分类错误的情况。

我们用sklearn中的线性SVM进行训练并绘制决策边界,其中惩罚项系数C=0.001,发现决策边界离两个类都比较近,然后用测试集进行训练,发现正确率为0.948,即错误率为0.052。同时我们改变惩罚项系数再次训练,令C=0.1,然后用测试集进行训练,还是发现正确率为1,即错误率为0。



我们放大决策边界的位置,发现在惩罚项C=0.001时,有一个分类错误,还有一个在边界上:

手写数字:
1.在普通的SVM下,
测试集的准确率:99.74%,所以分类错误的比例为0.26%
训练集的准确率:99.71%,所以分类错误的比例为0.29%
下面是几张训练集上分类错误的图片:


下面是一张训练集上分类错误的图片:


通过图片可以发现,分类错误的原因很可能是书写不规范造成的,既不像0 也不是1 ,特征不够明显,而这些数据会成为噪声点误导模型。
在正则化SVM下:
我选择的惩罚项系数C分别为0.01,0.1,1,10,100,下图为模型在训练集上,在不同惩罚项系数下的准确率:

下图为模型在测试集上,在不同惩罚项系数下的准确率:

回答问题:
(i)从上述结果发现C=100时训练误差最大。
(ii)问题(i)中对应的测试误差为1-0.9960 = 0.0040,在matlab显示2115个测试数据错了17个。
(iii)由表中可以看C在10时测试误差和训练误差都很小,所以我认为C=10左右会使得测试误差很小。
非线性SVM:
首先我们绘制训练数据集3的散点图,可以发现两个类别之间有相互渗透的部分,用线性SVM不能得到很好的决策边界,所以我们采用核函数进行非线性的SVM。

这里我们使用高斯核函数,即RBF,其中gamma=1,然后绘制出决策边界,如下图所示:这是一个非线性的分类边界,虽然有一些分类错误,但这些点都是噪声点,所以我们得到了较好的决策边界。

下面是gamma=10的分类边界,与gamma=1相比,蓝色点的范围变大,分类边界没有之前那么平滑,显得有点崎岖,但总体来说也是较好的分类边界。

下面是gamma=100,与之前的相比,可以看见蓝色类别的样本点的分布曲线都比较窄,此时的决策边界就是这些蓝色类别样本点周围围绕的区域,只有样本点在这些区域内才判定样本点为蓝色类别,否则,将样本点判定为红色类别,这也出现了轻微的过拟合现象。

下面是gamma=1000,与之前的相比,这里的分类边界非常离谱,只有非常接近蓝色点的区域才会被判别为蓝色,出现了明显的过拟合现象。

1.Different values Of C
在第一个数据集中,不同的C对于最后的准确率没有影响,都是100%,第二个对于不同的C准确率也非常高,说明这第一个数据集都存在一个线性可分的超平面。 但是C对于所决定的boundary的范围是有影响的,C越小,从而导致惩罚项权重变小,就会导致一个更大的margin,但是可能存在更多的误分类。
2.高斯分布曲线的形状都是相似的钟形图。
u决定分布图中心的偏移情况。
theta决定分布图峰值的高低,或者说钟形的胖瘦程度。
因为高斯函数中的theta和高斯核函数中gamma成倒数关系。所以:
高斯函数中theta越大、高斯分布峰值越小。theta越小、高斯分布峰值越大。
高斯核函数中gamma越大、高斯分布峰值越大,既钟形越窄。gamma越小、高斯分布峰值越小,既钟形越宽。
3.SMO
SMO就是把一个大的二次规划转化成多个小的二次规划
a. 根据预先设定的规则,从所有样本中选出两个
b. 保持其他拉格朗日乘子不变,更新所选样本对应的拉格朗日乘子
SVM代码:
高斯核函数和线性核:
function K = kernel(X,Y,type,gamma)
switch type
case 'linear' %线性核
K = X*Y';
case 'rbf' %高斯核
m = size(X,1);
K = zeros(m,m);
for i = 1:m
for j = 1:m
K(i,j) = exp(-gamma*norm(X(i,:)-Y(j,:))^2);
end
end
end
End
训练函数:
function svm = svmTrain(X,Y,kertype,gamma,C)
%二次规划问题,使用quadprog,详细help quadprog
n = length(Y);
H = (Y*Y').*kernel(X,X,kertype,gamma);
f = -ones(n,1);
A = [];
b = [];
Aeq = Y';
beq = 0;
lb = zeros(n,1);
ub = C*ones(n,1);
a = quadprog(H,f,A,b,Aeq,beq,lb,ub);
epsilon = 3e-5; %阈值可以根据自身需求选择
%找出支持向量
svm_index = find(abs(a)> epsilon);
svm.sva = a(svm_index);
svm.Xsv = X(svm_index,:);
svm.Ysv = Y(svm_index);
svm.svnum = length(svm_index);
svm.a = a;
end
预测函数:
function test = predict1(train_data_name,test_data_name,kertype,gamma,C)
%(1)-------------------training data ready-------------------
train_data = load(train_data_name);
n = size(train_data,2); %data column
train_x = train_data(:,1:n-1);
train_y = train_data(:,n);
%find the position of positive label and negtive label
pos = find ( train_y == 1 );
neg = find ( train_y == -1 );
figure('Position',[400 400 1000 400]);
subplot(1,2,1);
plot(train_x(pos,1),train_x(pos,2),'k+');
hold on;
plot(train_x(neg,1),train_x(neg,2),'bs');
hold on;
%(2)-----------------decision boundary-------------------
train_svm = svmTrain(train_x,train_y,kertype,gamma,C);
%plot the support vector
plot(train_svm.Xsv(:,1),train_svm.Xsv(:,2),'ro');
train_a = train_svm.a;
train_w = [sum(train_a.*train_y.*train_x(:,1));sum(train_a.*train_y.*train_x(:,2))];
train_b = sum(train_svm.Ysv-train_svm.Xsv*train_w)/size(train_svm.Xsv,1);
train_x_axis = 0:1:200;
plot(train_x_axis,-train_b-train_w(1,1)*train_x_axis/train_w(2,1),'-');
legend('1','-1','suport vector','decision boundary');
title('training data')
hold on;
%(3)-------------------testing data ready----------------------
test_data = load(test_data_name);
m = size(test_data,2); %data column
test_x = test_data(:,1:m-1);
test_y = test_data(:,m);
%find the test data positive label and negtive label
test_label = sign(test_x*train_w + train_b);
subplot(1,2,2);
test_pos = find ( test_y == 1 );
test_neg = find ( test_y == -1 );
plot(test_x(test_pos,1),test_x(test_pos,2),'k+');
hold on;
plot(test_x(test_neg,1),test_x(test_neg,2),'bs');
hold on;
%(4)------------------decision boundary -----------------------
test_x_axis = 0:1:200;
plot(test_x_axis,-train_b-train_w(1,1)*test_x_axis/train_w(2,1),'-');
legend('1','-1','decision boundary');
title('testing data');
%print the detail
fprintf('--------------------------------------------\n');
fprintf('training_data: %s\n',train_data_name);
fprintf('testing_data: %s\n',test_data_name);
fprintf('C = %d\n',C);
fprintf('number of test data label: %d\n',size(test_data,1));
fprintf('predict corret number of test data label: %d\n',length(find(test_label==test_y)));
fprintf('Success rate: %.4f\n',length(find(test_label==test_y))/size(test_data,1));
fprintf('--------------------------------------------\n');
end
主函数:
kertype = 'linear';
gamma = 0; C = 1;
predict1('training_1.txt','test_1.txt',kertype,gamma,C);
predict1('training_2.txt','test_2.txt',kertype,gamma,C);
手写数字代码:
化简数据:
function svm = re_hand_digits(filename,n)
fidin = fopen(filename);
i = 1;
apres = [];
while ~feof(fidin)
tline = fgetl(fidin); % 从文件读行
apres{i} = tline;
i = i+1;
end
grid = zeros(n,784);
label = zeros(n,1);
for k = 1:n
a = char(apres(k));
lena = size(a,2);
xy = sscanf(a(4:lena), '%d:%d');
label(k,1) = sscanf(a(1:3),'%d');
lenxy = size(xy,1);
for i=2:2:lenxy %% 隔一个数
if(xy(i)<=0)
break
end
grid(k,xy(i-1)) = xy(i) * 100/255; %转为有颜色的图像
end
end
svm.grid = grid;
svm.label = label;
end
svm1 = re_hand_digits('train-01-images.svm',12665);
svm2 = re_hand_digits('test-01-images.svm',2115);
train_x = svm1.grid; train_y = svm1.label;
test_x = svm2.grid; test_y = svm2.label;
train = [train_x,train_y];
test = [test_x,test_y];
[row,col] = size(test);
fid=fopen('hand_digits_test.dat','wt');
for i=1:1:row
for j=1:1:col
if(j==col)
fprintf(fid,'%g\n',test(i,j));
else
fprintf(fid,'%g\t',test(i,j));
end
end
end
fclose(fid);
[row,col] = size(train);
fid=fopen('hand_digits_train.dat','wt');
for i=1:1:row
for j=1:1:col
if(j==col)
fprintf(fid,'%g\n',train(i,j));
else
fprintf(fid,'%g\t',train(i,j));
end
end
end
fclose(fid);
预测函数
function [test_miss,train_miss] = predict2(train_data_name,test_data_name,kertype,gamma,C)
%(1)-------------------training data ready-------------------
train_data = train_data_name;
n = size(train_data,2);
train_x = train_data(:,1:n-1);
train_y = train_data(:,n);
%(2)-----------------training model-------------------
%二次规划用来求解问题,使用quadprog
n = length(train_y);
H = (train_y*train_y').*kernel(train_x,train_x,kertype,gamma);
f = -ones(n,1); %f'为1*n个-1
A = [];
b = [];
Aeq = train_y';
beq = 0;
lb = zeros(n,1);
if C == 0 %无正则项
ub = [];
else %有正则项
ub = C.*ones(n,1);
end
train_a = quadprog(H,f,A,b,Aeq,beq,lb,ub);
epsilon = 2e-7;
%找出支持向量
sv_index = find(abs(train_a)> epsilon);
Xsv = train_x(sv_index,:);
Ysv = train_y(sv_index);
svnum = length(sv_index);
train_w(1:784,1) = sum(train_a.*train_y.*train_x(:,1:784));
train_b = sum(Ysv-Xsv*train_w)/svnum;
train_label = sign(train_x*train_w+train_b);
train_miss = find(train_label~=train_y);
%(3)-------------------testing data ready----------------------
test_data = test_data_name;
m = size(test_data,2);
test_x = test_data(:,1:m-1);
test_y = test_data(:,m);
test_label = sign(test_x*train_w+train_b);
test_miss = find(test_label~=test_y);
%(4)------------------detail -----------------------;
%print the detail
fprintf('--------------------------------------------\n');
fprintf('C = %d\n',C);
fprintf('number of test data label: %d\n',size(test_data,1));
fprintf('number of train data label: %d\n',size(train_data,1));
fprintf('predict corret number of test data label: %d\n',length(find(test_label==test_y)));
fprintf('predict corret number of train data label: %d\n',length(find(train_label==train_y)));
fprintf('Success rate of test data: %.4f\n',length(find(test_label==test_y))/size(test_data,1));
fprintf('Success rate of train data: %.4f\n',length(find(train_label==train_y))/size(train_data,1));
fprintf('--------------------------------------------\n');
end
非线性SVM代码:需结合上面SVM的部分代码
高斯核函数和线性核
function K = kernel(X,Y,type,gamma)
switch type
case 'linear' %线性核
K = X*Y';
case 'rbf' %高斯核
m = size(X,1);
K = zeros(m,m);
for i = 1:m
for j = 1:m
K(i,j) = exp(-gamma*norm(X(i,:)-Y(j,:))^2);
end
end
end
end
预测函数:
function test = predict3(train_name,type,gamma,C)
%-----------------------training data ready------------------------
train = train_name;
[m,n] = size(train);
train_x = train(:,1:n-1);
train_y = train(:,n);
pos = find(train_y == 1);
neg = find(train_y == -1);
plot(train_x(pos,1),train_x(pos,2),'k+');
hold on;
plot(train_x(neg,1),train_x(neg,2),'bs');
hold on;
%-----------------------training model--------------------------
%二次规划用来求解问题,使用quadprog
K = kernel(train_x,train_x,type,gamma);
H = (train_y*train_y').*K;
f = -ones(m,1);
A = [];
b = [];
Aeq = train_y';
beq = 0;
lb = zeros(m,1);
if C == 0
ub = [];
else
ub = C*ones(m,1);
end
a = quadprog(H,f,A,b,Aeq,beq,lb,ub);
epsilon = 1e-5;
%查找支持向量
sv_index = find(abs(a)> epsilon);
Xsv = train_x(sv_index,:);
Ysv = train_y(sv_index);
svnum = length(sv_index);
%make classfication predictions over a grid of values
xplot = linspace(min(train_x(:,1)),max(train_x(:,1)),100)';
yplot = linspace(min(train_x(:,2)),max(train_x(:,2)),100)';
[X,Y] = meshgrid(xplot,yplot);
vals = zeros(size(X));
%calculate decision value
train_a = a;
sum_b = 0;
for k = 1:svnum
sum = 0;
for i = 1:m
sum = sum + train_a(i,1)*train_y(i,1)*K(i,k);
end
sum_b = sum_b + Ysv(k) - sum;
end
train_b = sum_b/svnum;
for i = 1:100
for j = 1:100
x_y = [X(i,j),Y(i,j)];
sum = 0;
for k = 1:m
sum = sum + train_a(k,1)*train_y(k,1)*exp(-gamma*norm(train_x(k,:)-x_y)^2);
end
vals(i,j) = sum + train_b;
end
end
%plot the SVM boundary
colormap bone;
contour(X,Y,vals,[0 0],'LineWidth',2);
title(['\gamma = ',num2str(gamma)]);
end
主函数:
type = 'rbf';
train_name = load('training_3.text');
gamma = [1,10,100,1000];
C = 1;
for i = 1:length(gamma)
predict3(train_name,type,gamma(i),C);
if i ~= length(gamma)
figure;
end
end