概念
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
我把决策树理解为通过一次一次对各种情况的条件判断,从而获得正确的决断。
例子
下图为一张银行贷款数据表格,包含了一个人的id,年龄,是否有工作、房子以及信贷情况,并且根据给出了能否获得贷款的状态。其中最后一列为能否获得贷款
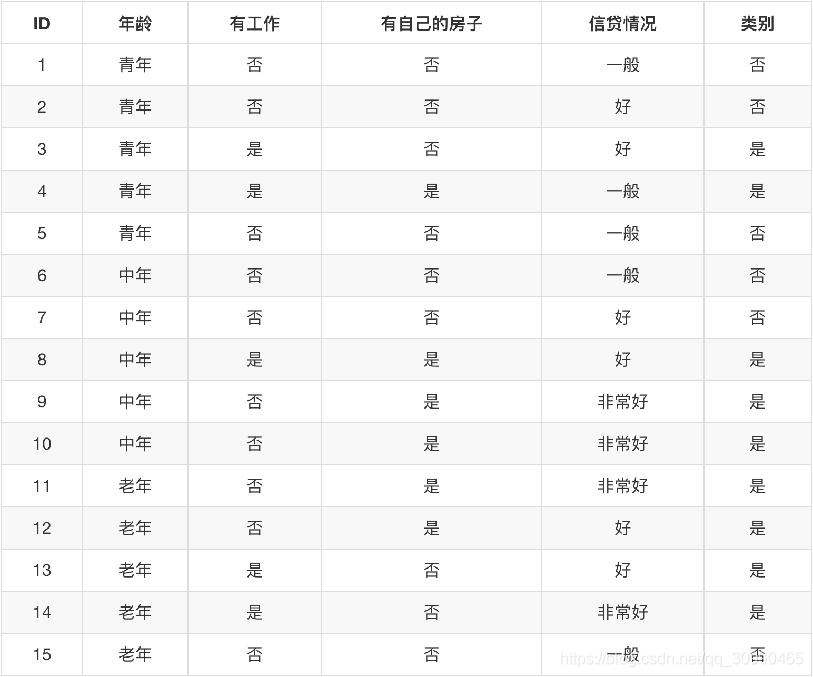
在这里我们可以把年龄分为
把工作分为
房子分为
信贷情况分为
那么我们可以进行组合从而判断一个人是否能够得到贷款:如:
我们把不同的条件组合成一个自上而下的树,我们通过判断从而确定是否贷款,那么如何确定哪一个作为根节点(上方),哪一个作为子节点(下方)呢?这就需要借助信息熵的相关知识了了
信息熵
信息熵这个词是C.E.香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
我们可以理解为一个物体或事件内的信息混乱程度,比如如果是有工作就可以贷款,没工作就不可以贷款,那么这样就可以表明贷款这件事的混乱程度较低。但如果要综合考虑工作、房子、年龄等因素则这件事的混乱程度就高。
当不确定性越大时,熵的值越大。我们假设H(X)为熵的值,p为一件事发生或不发生的概率。当p=0或者p=1时完全没有不确定性,此时熵值为0,当p的值为0.5时不确定性最大,熵值为1.如下图
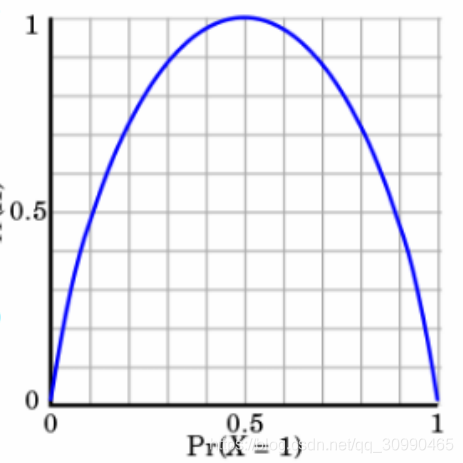
其中纵坐标为H(x)的值,横坐标为p
而我们选择节点的依据是信息增益
信息增益
在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。
那么我们选择的这个节点要确保他能够最大限度的降低整个系统的不确定性程度。
信息熵与信息增益的计算
信息熵的计算公式如下:
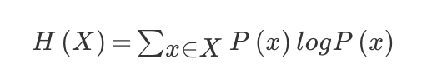
其中p(x)为某件事发生的概率,logP(x)则取其对数。
信息增益的计算公式如下:
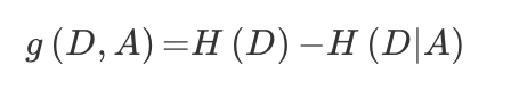
H(D)为D事件的信息熵,而H(D|A)为给定特征A下D的信息熵。
通常H(D)经过计算后已确定,当H(D|A)的熵越小说明在A特征下不确定性越小,则计算后g(D,A)越大,信息增益越大,我们就越倾向于选取A特征作为节点。
例如:在上式银行贷款的例子中:
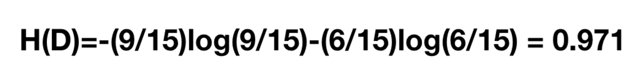
其中15为一共15个样本,9代表我们可以贷款的样本有9个,6代表不可以贷款的样本。
紧接着我们假设:
则有

其中H(D1)表示年龄如果是青年情况下是否可以贷款的信息熵,5表示5个样本,2表示可以贷款人数,3表示不可以贷款人数,其他同理。
我们通过H(D)-H(D|
)得到年龄条件下的信息增益,同样我们也可以算出其他情况下的信息增益。
g(D,
)= 0.170
g(D, )=0.324
g(D, )=0.420
g(D, )=0.363
的信息增益最大,因此我们选择 作为根节点,以此类推
决策树算法
ID3
ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
简单理解就是ID3优先考虑信息增益较大的节点
C4.5
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
- 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
- 在树构造过程中进行剪枝;
- 能够完成对连续属性的离散化处理;
- 能够对不完整数据进行处理。
简单理解就是C4.5使用的是信息增益比,而不是单纯的选择最大信息增益的特征,会考虑到自身的熵值,信息增益比会在信息增益基础上增加一个惩罚参数,当特征个数多时惩罚参数小,反之则惩罚参数大。从而避免偏向于选择取值多属性的不足
GINI系数
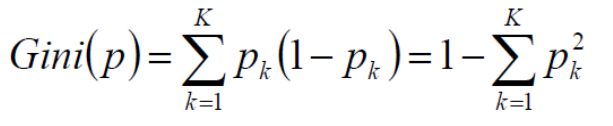
本质与计算熵类似,如当
时达到最大值,当
,得到基尼系数为0
连续值进行决策
可进行排序后进行二分,得到的则变为离散化数据
如:
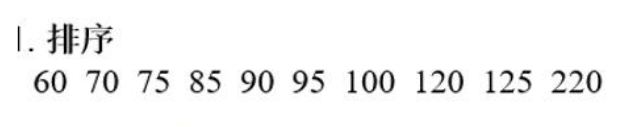
而后:

分割为两个部分。变为两个离散值
决策树的剪枝
剪枝的目的
决策树剪枝是指减少对每个节点的再次细分。
例如,可能一个人只要有房有工作就可以贷款,但也许样本中只出现了中年,并且有房有工作的情况,一旦划分过细,则即使青年有房有工作也会误判为无法获得贷款。
剪枝则能够有效的减少这样的问题,他能够避免过拟合的问题(即划分过细)。
剪枝策略分为两种,预剪枝和后剪枝。
预剪枝
边建立决策树边进行剪枝,这种方式更实用
通常它是通过限制深度,叶子节点个数,叶子节点样本数,信息增益量等方式进行实现
后剪枝
在决策树建立之后进行剪枝,通常是根据一定的衡量标准进行实现的