(一)任务表述
- 图像理解的三大层次
图像水平的物体分类
通用目标检测
像素水平的物体分割

-
分类(Classification):是最简单、最基础的图像理解任务
ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。 -
检测(Detection):在目标定位中,通常只有一个或固定数目的目标;而目标检测更一般化,其图像中出现的目标种类和数目都不定。检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
-
分割(Segmentation):包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
(二)主要难题

两个相互竞争的目标:high quality/accuracy and high efficiency
(三)研究进展
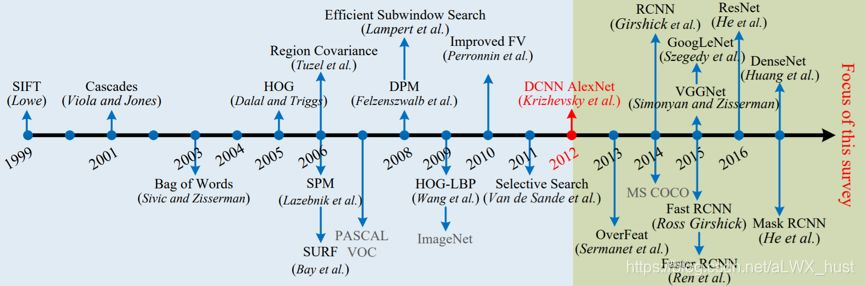
- 过去20年
- 基于深度学习的方法
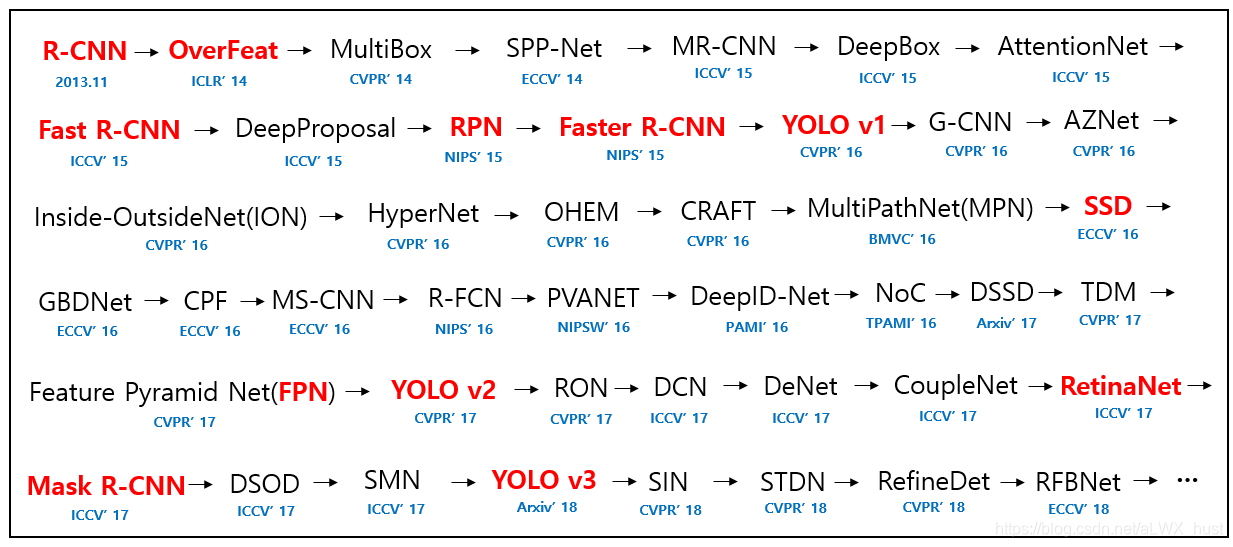
- 两大类别
- 两级式检测框架,包含一个产生候选区域(region proposals)的预处理步骤,使得整体流程是两级式的。
在检测准确率和定位精度上占优 - 单级式检测框架,即无候选区域的框架,不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。整个流程是单级式的。
在算法速度上占优