目录
写在前面
在秋招面试的过程中就能看出,当前大多数公司的视觉算法落地场景的主要还是Object Detection,这也是视觉领域目前最为成熟的领域。虽然检测的精度现在已经刷得很高,未来的研究价值仿佛不高,但掌握目标检测的前世今生和研究方法不仅能在工业界中产生实际价值,也能对Segmentation、Tracking、Video等领域未来的工业落地产生启发作用。之前也只是陆陆续续读过一些目标检测经典文章和方法,因此希望能通过阅读综述和整理之前的笔记,更好地加深记忆。
我的目标检测笔记分为四个部分,本文为第一部分:
(1)综述,包括传统方法与深度学习方法对比、发展现状、评价指标、数据集、检测流程与框架等;
(2)Anchor-Based经典模型分析,包括Two Stage模型Faster RCNN、 One Stage模型 SSD、YOLOv1-v3等;
(3)Anchor-Free发展和论文概述。包括对anchor-free模型的介绍、本质分析和论文阅读。
(4)目标检测常用技巧,包括Data Augmentation、OHEM、Deformable Conv、Focal Loss、SoftNMS等
问题描述
首先用一张经典的图来描述计算机视觉的四个基本任务。
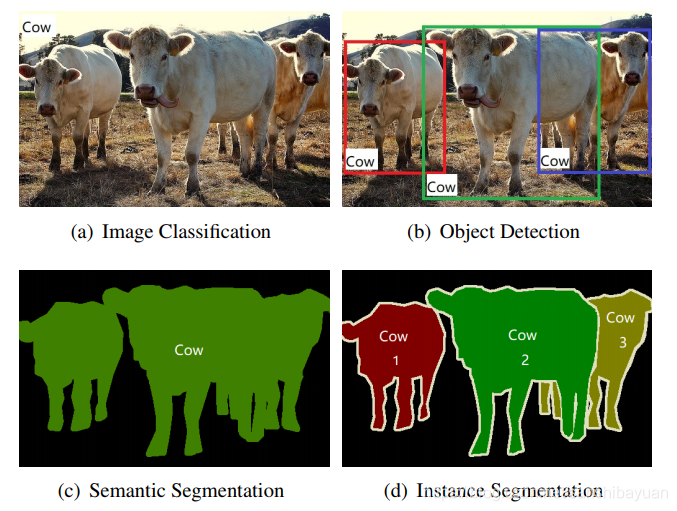
可以看到,目标检测(Object Detection)的目标即找出图像中所有感兴趣的物体,它通常包含物体定位(Localization)和物体分类(Classification)两个子任务,同时确定物体的类别和位置。这两个子任务也是后面所讲的检测流程与框架的核心出发点。
传统方法 VS 深度学习方法
在深度学习大规模流行(2013年)之前,目标检测与其他计算机视觉任务一样,多用基于手工特征的传统图像处理方法解决。下表总结了传统方法与深度学习方法的异同与优劣。可以看到,(1)两者有些思想是想通的,可以说深度学习方法借鉴了传统方法的优点;(2)总体来说,深度学习方法目前的优势更大,更占主流。
| 传统方法 |
深度学习 |
|
| 基本流程(相同) |
先生成proposals(ROI),再提取feature vector,最后对proposals进行分类 |
|
| 基本流程(不同) |
|
|
| 备注 |
|
|
| 优点 |
|
|
| 缺点 |
|
|
发展现状
检测流程
基于物体定位(Localization)和物体分类(Classification)两个子任务,现代目标检测技术的流程基本可以分为如下步骤,
- 输入图像;
- Backbone即主干网络,用以学习图片特征,一般复用图像分类网络;
- Head即出口,从图像特征中学习检测目标,如生成proposal(位置回归)与得到分类评分(类别预测),这两个任务常常是并行进行的,构成多任务的损失进行联合训练;
- Postprocess后处理,使用NMS等手段优化结果。
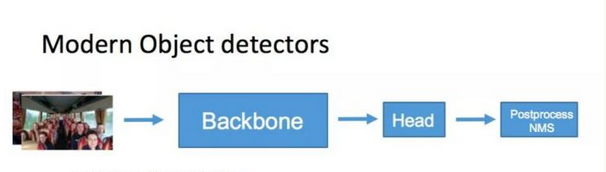
检测框架(One-Stage & Two-Stage)
One-Stage目标检测算法可以在一个stage直接产生物体的类别概率和位置坐标值,相比于Two-Stage的目标检测算法不需要Region Proposal阶段,整体流程较为简单。代表作有YOLO,SSD等;Two-Stage目标检测框架可以看作是进行两次One-Stage检测,第一个Stage初步检测出物体位置,第二个Stage对第一个阶段的结果做进一步的精化,对每一个候选区域进行One-Stage检测。代表作有Faster R-CNN系列。这些代表作都使用到了预先设置的Anchor,在Anchor-Based经典模型分析有详细的分析。
相比One-Stage,Two-Stage检测模型通常含有一个串行的头部结构,即完成前背景分类和回归后,把中间结果作为RCNN头部的输入再进行一次多分类和位置回归。这种设计带来了一些优点:
- 对检测任务的解构,先进行前背景的分类,再进行物体的分类,这种解构使得监督信息在不同阶段对网络参数的学习进行指导
- RPN网络为RCNN网络提供良好的先验,并有机会整理样本的比例,减轻RCNN网络的学习负担
这种设计的缺点也很明显:中间结果常常带来空间开销,而串行的方式也使得推断速度无法跟单阶段相比;级联的位置回归则会导致RCNN部分的重复计算(如两个RoI有重叠)。
另一方面,单阶段模型只有一次类别预测和位置回归,卷积运算的共享程度更高,拥有更快的速度和更小的内存占用。目前来看,两种类型的模型也在互相吸收彼此的优点,这也使得两者的界限更为模糊。
====================分割线==========================
Two Stage模型结构概述:

One Stage模型结构概述:

发展趋势(2019年底)
到了现在(2019年底),目标检测大趋势是Backbone网络使用NAS(神经网络自动设计)技术;检测框架采用One-Stage的anchor-free(不依赖检测框)。关于anchor-free,后续也将专门进行总结。
评价指标
IoU
IoU是预测框与ground truth的交集和并集的比值。这个量也被称为Jaccard指数,并于20世纪初由Paul Jaccard首次提出。为了得到交集和并集,我们首先将预测框与ground truth放在一起,如图所示。
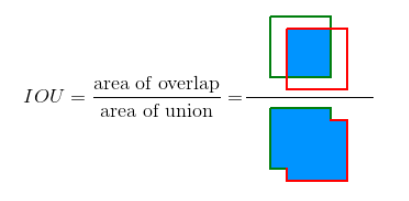
目标检测问题同时是一个回归和分类问题。首先,为了评估定位精度,需要计算IoU(Intersection over Union,介于0到1之间),其表示预测框与真实框(ground-truth box)之间的重叠程度。IoU越高,预测框的位置越准确。因而,在评估预测框时,通常会设置一个IoU阈值(如0.5),只有当预测框与真实框的IoU值大于这个阈值时,该预测框才被认定为真阳性(True Positive, TP),反之就是假阳性(False Positive,FP)。
mAP
mAP定义及相关概念
- mAP: mean Average Precision, 即各类别AP的平均值AP: PR曲线下面积
- PR曲线: Precision-Recall曲线
- Precision: TP / (TP + FP)
- Recall: TP / (TP + FN)
- TP: IoU>阈值的检测框数量(同一Ground Truth只计算一次)
- FP: IoU<=阈值的检测框,或者是检测到同一个GT的多余检测框的数量
- FN: 没有检测到的GT的数量
mAP计算步骤
- 首先统计检测出的boxes总数(N=TP+FN),并按照confidence排序;
- 随后根据设定好的IoU阈值(与GT),判断每个区域为TP或FP。如同一个GT检测出多个区域则只取confidence最大的为TP,其他全部算作FP;
- 依次添加box,计算累计recall,precision,取每个recall值下的最大precision;
- 计算P-R曲线面积,即该类别下的AP;
- 计算所有类别,平均,得到mAP。
对于目标检测,mAP一般在某个固定的IoU上计算,但是不同的IoU值会改变TP和FP的比例,从而造成mAP的差异。COCO数据集提供了官方的评估指标,它的AP是计算一系列IoU下(0.5:0.05:0.9,见说明)AP的平均值,这样可以消除IoU导致的AP波动。其实对于PASCAL VOC数据集也是这样,Facebook的Detectron上的有比较清晰的实现。
参考代码(Detectron)
Precision和recall的计算:
# 按照置信度降序排序
sorted_ind = np.argsort(-confidence)
BB = BB[sorted_ind, :] # 预测框坐标
image_ids = [image_ids[x] for x in sorted_ind] # 各个预测框的对应图片id
# 便利预测框,并统计TPs和FPs
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float) # ground truth
if BBGT.size > 0:
# 计算IoU
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
# 取最大的IoU
if ovmax > ovthresh: # 是否大于阈值
if not R['difficult'][jmax]: # 非difficult物体
if not R['det'][jmax]: # 未被检测
tp[d] = 1.
R['det'][jmax] = 1 # 标记已被检测
else:
fp[d] = 1.
else:
fp[d] = 1.
# 计算precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
这里最终得到一系列的precision和recall值,并且这些值是按照置信度降低排列统计的,可以认为是取不同的置信度阈值(或者rank值)得到的。然后据此可以计算AP:
def voc_ap(rec, prec, use_07_metric=False):
"""Compute VOC AP given precision and recall. If use_07_metric is true, uses
the VOC 07 11-point method (default:False).
"""
if use_07_metric: # 使用07年方法
# 11 个点
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t]) # 插值
ap = ap + p / 11.
else: # 新方式,计算所有点
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision 曲线值(也用了插值)
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
参考链接
目标检测中的mAP是什么含义?-知乎
Metrics for object detection -github
目标检测模型的评估指标mAP详解(附代码4
FPS
除了检测准确度,目标检测算法的另外一个重要性能指标是速度,只有速度快,才能实现实时检测,这对一些应用场景极其重要。评估速度的常用指标是每秒帧率(Frame Per Second,FPS),即每秒内可以处理的图片数量。当然要对比FPS,你需要在同一硬件上进行。另外也可以使用处理一张图片所需时间来评估检测速度,时间越短,速度越快。
常用数据集
目标检测常用的数据集包括PASCAL VOC,ImageNet,MS COCO等数据集,这些数据集用于研究者测试算法性能或者用于竞赛。
PASCAL VOC
PASCAL VOC(The PASCAL Visual Object Classification)是目标检测,分类,分割等领域一个有名的数据集。从2005到2012年,共举办了8个不同的挑战赛。PASCAL VOC包含约10,000张带有边界框的图片用于训练和验证。但是,PASCAL VOC数据集仅包含20个类别,因此其被看成目标检测问题的一个基准数据集。
ImageNet
ImageNet在2013年放出了包含边界框的目标检测数据集。训练数据集包含500,000张图片,属于200类物体。由于数据集太大,训练所需计算量很大,因而很少使用。同时,由于类别数也比较多,目标检测的难度也相当大。
COCO
另外一个有名的数据集是Microsoft公司建立的MS COCO(Common Objects in COntext)数据集。这个数据集用于多种竞赛:图像标题生成,目标检测,关键点检测和物体分割。对于目标检测任务,COCO共包含80个类别,每年大赛的训练和验证数据集包含超过120,000个图片,超过40,000个测试图片。测试集最近被划分为两类,一类是test-dev数据集用于研究者,一类是test-challenge数据集用于竞赛者。测试集的标签数据没有公开,以避免在测试集上过拟合。
参考文章
<Recent Advances in Deep Learning for Object Detection>
