本文是参考网络上的博客总结目标检测应用的基础知识!!!
1.目标检测
“目标检测”主要解决两个问题:图像上多个目标在哪里(位置),是什么(类别)
人们一般把其发展历程分为3个阶段:
a.传统的目标检测方法
b.两阶段检测器
以R-CNN为代表的结合region proposal和CNN分类的目标检测框架(R-CNN, SPP-NET, Fast R-CNN,Faster R-CNN, R-FCN)
c. 单阶段检测器
以YOLO为代表的将目标检测转换为回归问题的端到端(End-to-End)的目标检测框架(YOLO, SSD)
2.常用数据集
Pascal VOC 2012、PascalVOC 2007、ILSVRC 2012
ILSVRC 2012样本集上仅有图像类别标签,没有图像物体位置标注;
PASCAL VOC 2007样本集上既有图像中物体类别标签,也有图像中物体位置标签;
3.有监督预训练
也称之为迁移学习,举例说明:若有大量标注信息的人脸年龄分类的正负样本图片,利用样本训练了CNN网络用于人脸年龄识别;现在要通过人脸进行性别识别,那么就可以去掉已经训练好的人脸年龄识别网络CNN的最后一层或几层,换成所需要的分类层,前面层的网络参数直接使用为初始化参数,修改层的网络参数随机初始化,再利用人脸性别分类的正负样本图片进行训练,得到人脸性别识别网络,这种方法就叫做有监督预训练。
这种方式可以很好地解决小样本数据无法训练深层CNN网络的问题,我们都知道小样本数据训练很容易造成网络过拟合,但是在大样本训练后利用其参数初始化网络可以很好地训练小样本,这解决了小样本训练的难题。
4. Selective Search算法
首先利用图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
5. 感受野
在卷积神经网络CNN中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野(receptivefield)。感受野是CNN中feature map上的一个点对应输入图上的区域。
6. 模型的评价指标
Recall(召回率、查全率)
召回率是从数据集的同一标签的样本抽样概率
Precision(准确率、查准率)
准确率是从已经预测为同一类别的样本抽样概率
P-R曲线
横坐标为召回率,纵坐标为准确率
AP(单个类别的平均精度)
计算平均的检测精度,用于衡量检测器在每个类别上的性能好坏
mAP(平均多个类别的平均精度)
用于评价多目标的检测器性能,衡量检测器在所有类别上的性能好坏,即得到每个类别的AP值后再取所有类别的平均值
7. 端到端(end-to-end)
一端输入原始图像,另一端输出预测结果
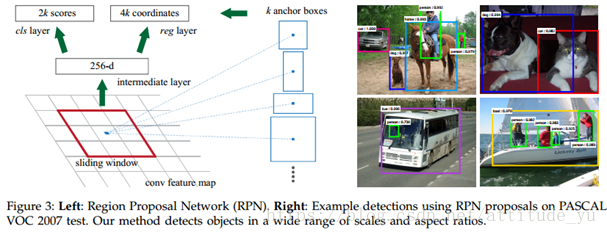
8. Anchors
共享卷积层的最后一层大小为W×H特征图上,每个3x3滑动窗口对应于原图上k种不同长宽比例、不同面积区域的卷积与池化。这k种原图区域中心点和滑动窗口的中心点是一样的。也就是说,通过滑动窗口和k个不同长宽比例、不同面积的anchor,可以逆向推导出 W*H*k 在原始图片上的proposal。reg层具有W*H*4*k个输出,即W*H*k个框的坐标,并且cls层输出W*H*2*k个预测得分,其估计每个建议框是目标或不是的概率。
9.非极大值抑制
使用极大概率的候选框抑制其它位置相近的候选框。如果有两个框重叠的部分比较多,就把概率低的剔除掉。
a.从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值
b.假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,保留下来
c.从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是保留下来的第二个矩形框
d.一直重复这个过程,直到所有被保留下来的候选框(有可能存在同一类别的多个目标)
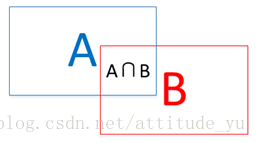
10.Intersection of Union(IoU)
IoU=(A∩B)/(A∪B)
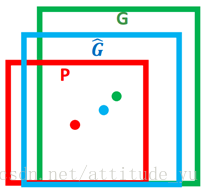
11.边框回归
框的表示使用四维向量表示(x,y,w,h),基于预测框和真实框而通过所学习的关系,使预测框经过映射得到一个跟真实框更加接近的回归窗口。
a.经过真实框和预测框计算得到的需要的平移量(tx,ty)(tx,ty)和尺度缩放(tw,th)(tw,th):
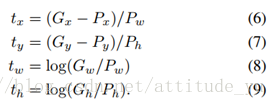
b.根据所求变换关系的目标函数,获得最优化问题:
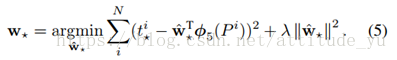
c.在学习这些变换关系函数后,通过应用变换将预测框转换为预测的接近真实框的预测框:
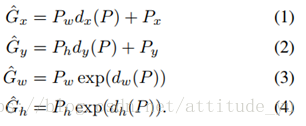
12. ROI Pooling Layer
特征图上的每一个RoI都由一个四元组(r,c,h,w)表示,其中(r,c)表示左上角,而(h,w)则代表高度和宽度。RoI 最大池化将每个候选区域均匀分成 H × W 块,每块是将 h×w RoI窗口划分为 h / H × w /W的子窗口网格,然后将每个子窗口中的值max pooling到相应的输出网格单元。从而将特征图上大小不一的RoI区域转化成固定大小的 H*W 的特征图,送入下一层。
参考资料:
1. 网络上的各篇相关博客(因为是笔记,所以链接也早已找不着了,无法再次注明了。。。)