前言
最近要用到动态规划,所以这里研究一下。
1 问题描述
首先,背包问题主要有三类:
1)01背包问题
2)完全背包问题
3)多重背包问题
要了解背包问题,我可是查了很多资料,如今看来,只需要看:文献 [18], [19] 就ok。
其实我碰到的是一个完全背包问题,就是说给定的是:
一家店专门卖麦辣鸡翅,而且生意很不错,但是呢,这个价格有点奇葩,定价如下:
4个鸡翅XX块钱
5个鸡翅XX块钱
7个鸡翅XX块钱
8个鸡翅XX块钱
9 ...
10 ...
17 ...
18 ...
19 ...
20 ...
24 ...
这个列表列出了店家规定的价格(明显这家店的鸡翅不能一个一个买),而且一次买不同个数鸡翅价格不一样,比如买8个和买9个,单价就不一样。现在问道:
1)画出鸡翅和单价的曲线;
2)如果买218个鸡翅,怎么最划算?
2 解题过程
2.1 第一问:画图
import matplotlib.pyplot as plt
import pandas as pd
data=pd.read_csv('menu.csv').values
x=data[:,0].tolist()
y=[data[i][1]/data[i][0] for i in range(0,len(data))]
plt.plot(x,y)
plt.xlabel('Number of Chicken Wings')
plt.ylabel('Corresponding Unit Price')
plt.xticks(x,rotation=45,fontsize=5)
plt.yticks(y,fontsize=5)
plt.grid()
这段代码可以说是得意之作了,非常简洁(当然这个过程看了很多参考文献,不容易。还用了help函数)。
结果如下:
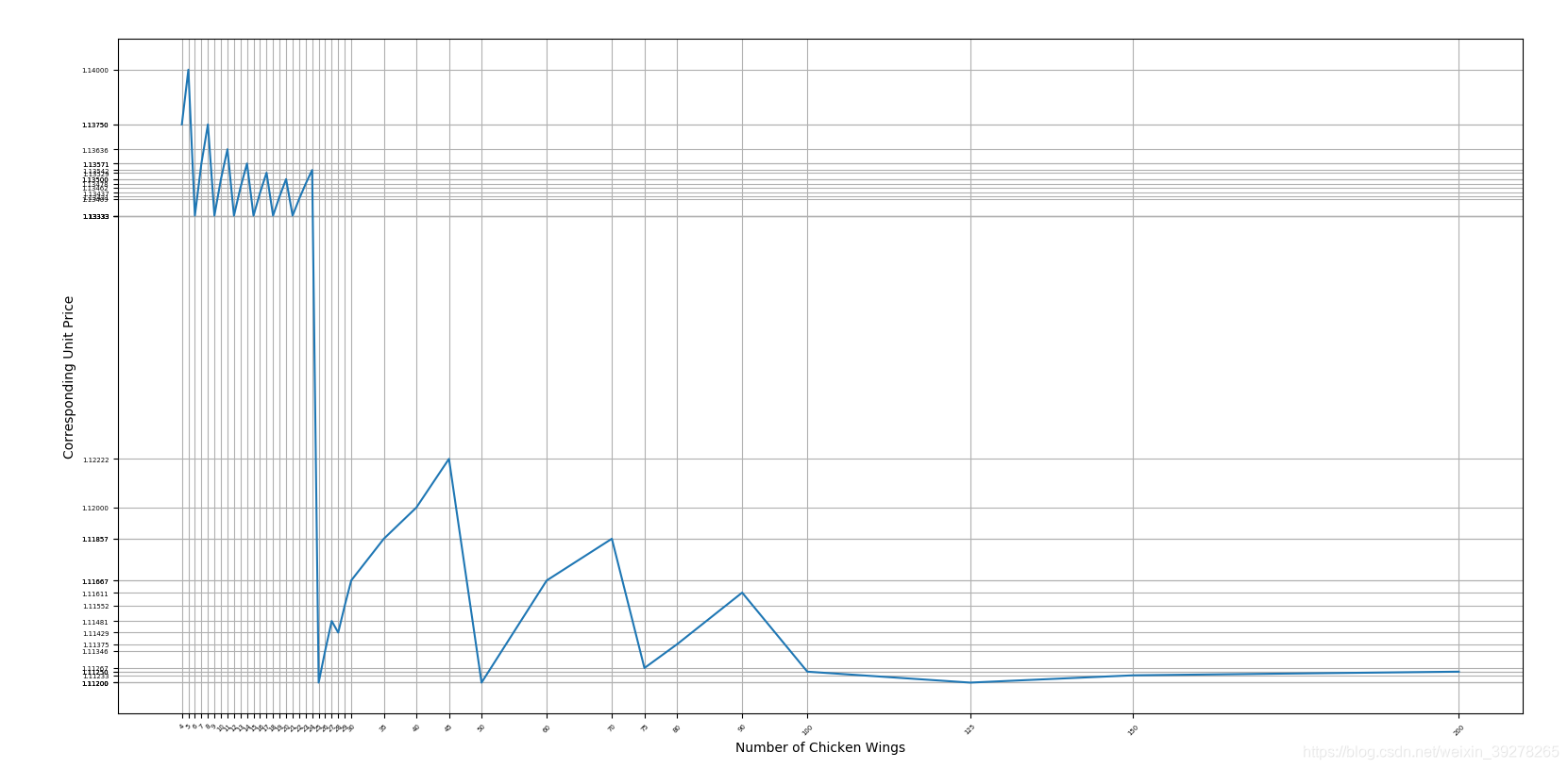
果然有点神奇。。。单价波动不小。。
2.2 第二问:动态规划求最优
一开始还没太明白动态规划,背包问题,看了[18],[19]还有很多文献后明白了,代码大概如下(比较粗糙):
# -*- coding: utf-8 -*-
"""
Created on Mon Dec 10 20:54:15 2018
@author: dehen
"""
# -*- coding: utf-8 -*-
"""
Created on Mon Dec 10 12:16:05 2018
@author: dehen
"""
#import matplotlib.pyplot as plt
#import csv
#import pandas as pd
#data1=csv.reader(open('menu.csv','r'))
#data=pd.read_csv('menu.csv').values #header=None
#print(pd.core.frame.DataFrame
#x,y=[],[]
#for i in range(0,len(data)):#or data.shape[0]
# x.append(float(data[i][0]))
# y.append(float(data[i][1])/float(data[i][0]))
import matplotlib.pyplot as plt
import pandas as pd
import math
data=pd.read_csv('menu.csv').values
x=data[:,0].tolist()
y=[data[i][1]/data[i][0] for i in range(0,len(data))]
#plt.plot(x,y)
#plt.xlabel('Number of Chicken Wings')
#plt.ylabel('Corresponding Unit Price')
#plt.xticks(x,rotation=45,fontsize=5)
#plt.yticks(y,fontsize=5)
#plt.grid()
#,purchase_x
purchase_x=[0 for i in x]
x_bkup=x.copy()
wings_num=218
max_value=10000
wings=[10000]*(wings_num+1)
#wings[0]=0
def get_better(value1,value2):
# return value1 if (value1/num1 != 0 and value1/num1 < value2/num2) else value2
return value1 if value1<value2 else value2
x=[int(i) for i in x]
for pos in range(0,len(x)):
wings[x[pos]]=x[pos]*y[pos]
wings_bkup=wings.copy()
for pos in range(0,len(x)):
for num in range(x[pos],wings_num+1):
# for num in range(wings_num,x[pos]-1,-1):
# for num in range(wings_num,x[pos],-1):
# if num>x[pos]:
# wings[num]=get_better(wings[num],wings[num-x[pos]]+x[pos]*y[pos])
if wings[num-x[pos]]+x[pos]*y[pos] <= wings[num]:
wings[num]=wings[num-x[pos]]+x[pos]*y[pos]
# if num==wings_num:
# print('here better',x[pos])
# print(num)
#x[pos]*y[pos]) wings[x[pos]]
# print(wings[num])
#j = len(x)-1
j=0
res = [0]*len(x)
wn = wings_num;
sum=0
print(wings[wings_num])
while wings_num >= x[0]:
for pos in range(0,len(x)):
if wings[wings_num]==wings[wings_num-x[pos]]+x[pos]*y[pos]:
wings_num-=x[pos]
sum+=x[pos]*y[pos]
print('choose ',x[pos],pos,wings_num,y[pos])
if wings[wings_num]==wings_bkup[wings_num]:
sum+=wings_bkup[wings_num]
print('choose ',wings_num)
break
print('sum is',sum)
#wings[wings_num]=wings[wings_num-x[pos]]+x[pos]*y[pos] pos
#wings_num-=x[pos]
#wings[wings_num]=wings[wings_num-x[pos]]+x[pos]*y[pos] pos
#while(j!=-1):
#while j!=len(x):
# if wings[wn]==wings[wn-x[j]]+x[j]*y[j]:
# print('choose ',j)
# wn-=x[j]
# sum+=x[j]*y[j]
# continue
# j+=1
# j+=1#continue
# j-=1
#print('sum is:',sum,sum+x[37]*y[37]==wings[wings_num])
#for pos in range(0,len(x)):
# if
#
#while(j!=-1):
# count = int(math.floor(wn/x[j]))
# print('count is:',count)
# for k in range(count,0,-1):
# if(wings[wn] == (wings[wn-x[j]*k]+k*x[j]*y[j])):
# print('dale',k,wn,x[j],x[j]*k,wings[wn-x[j]*k],k*x[j]*y[j],wings[wn],y[j])
# res[j] = k
# wn = wn - k*x[j]
# print(wn)
# break
# j-=1
#print(wings[wings_num])
#for i in range(0,len(res)):
# print(res[i])
这么多注释行足以看出我的尝试之多。。。
242.79999999999995
choose 9 5 209 1.1333333333333333
choose 28 24 181 1.1142857142857143
choose 28 24 153 1.1142857142857143
choose 125 37 28 1.112
choose 28
sum is 242.8
动态规划的第二种实现(改变初始化的方式)
而且有意思的是,我注释掉:
for pos in range(0,len(x)):
wings[x[pos]]=x[pos]*y[pos]
同时在前面加上:
wings[0]=0
会得到不一样的也是最优方案的结果:
The cheapest total price for buying 218 wings is : 242.8
choose 6 2 212 1.1333333333333333
choose 9 5 203 1.1333333333333333
choose 25 21 178 1.112
choose 28 24 150 1.1142857142857143
choose 50 30 100 1.112
choose 25 21 75 1.112
choose 50 30 25 1.112
choose 25 21 0 1.112
sum is 242.80000000000007
这里给出比较完整的,有注释的代码:
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 11 21:55:07 2018
@author: dehen
"""
import pandas as pd
data=pd.read_csv('menu.csv').values#这里是读文件
x=data[:,0].tolist() #将numpy转成list,方便后面的数据处理
y=[data[i][1]/data[i][0] for i in range(0,len(data))] # 计算单价,得到list
wings_num=218 # 要买的鸡翅数目
max_value=10000 # 设定的初始最大值,因为我们要买最便宜的,所以当然要设置成最大啦,不能像普通的背包问题,设为0
wings=[10000]*(wings_num+1) # 初始化 最大值, 注意:wings列表里面存的是总价格,如wings[n]表示买n个鸡翅的时候,最便宜的总价格。
wings[0]=0 # 让wings[0]设置为0,不然的话,没法迭代。而且0个鸡翅,总价格肯定是0
x=[int(i) for i in x] #转成int,方便下面的迭代
wings_bkup=wings.copy() #备份wings,方便后面回溯出最优方案
# 这一段代码是动态规划的核心代码了
for pos in range(0,len(x)):
for num in range(x[pos],wings_num+1): # 从x[pos]开始,到wings_num结束,因为range的原因,所以在range的时候用wings_num+1
# 这个for循环非常讲究。具体参考 背包问题(转自背包九讲+对应题目) http://www.cnblogs.com/fht-litost/p/9204147.html 完全背包问题
if wings[num-x[pos]]+x[pos]*y[pos] <= wings[num]: # 状态转移方程
wings[num]=wings[num-x[pos]]+x[pos]*y[pos] # 如果满足条件,就改变wings[num]的值
print("The cheapest total price for buying 218 wings is :",wings[wings_num])
sum=0 #回溯的时候,检查总价格对不对 identify the total price 其实也可以不要,只不过我自己想看下这样的sum和当时动态规划的sum有什么不一样
while wings_num >= x[0]: # 当wings_num比x[0]大,那就执行while下面的语句
for pos in range(0,len(x)): # 回溯
if wings[wings_num]==wings[wings_num-x[pos]]+x[pos]*y[pos]: #反向判断
wings_num-=x[pos] # 说明这个x[pos]是被选中了,那么就改变wings_num的值,表明剩下的鸡翅数
sum+=x[pos]*y[pos] # 计算价格
print('choose ',x[pos],pos,wings_num,y[pos]) #输出选择信息
if wings[wings_num]==0: # 终止条件,就是鸡翅都选完了
break
if wings[wings_num]==wings_bkup[wings_num]: # 如果只剩最后一次选取了,就执行这个循环。wings_bkup[wings_num]表明最初始的原始价格赋值
sum+=wings_bkup[wings_num]
print('choose ',wings_num)
break
print('sum is',sum)
2.2-2 其实还可以递归求解
因为218是个比较巧妙的数字,刚好可以用贪心算法,递归求解,就是每次选单价最小的,直到选满218个鸡翅。
import matplotlib.pyplot as plt
import pandas as pd
data=pd.read_csv('menu.csv').values
x=data[:,0].tolist()
y=[data[i][1]/data[i][0] for i in range(0,len(data))]
plt.plot(x,y)
plt.xlabel('Number of Chicken Wings')
plt.ylabel('Corresponding Unit Price')
plt.xticks(x,rotation=45,fontsize=5)
plt.yticks(y,fontsize=5)
plt.grid()
#,purchase_x
purchase_x=[0 for i in x]
x_bkup=x.copy()
y_bkup=y.copy()
def purchase(total_num,x,y):
best_price_pos=y.index(min(y))
x_best = x[best_price_pos]
if total_num == 0:
return purchase_x
if total_num < x_best:
x.remove(x_best)
y.remove(min(y))
return purchase(total_num,x,y)
while total_num >= x_best:
total_num -= x_best
purchase_x[best_price_pos] += 1
# print('print',purchase_x[best_price_pos])
x.remove(x_best)
y.remove(min(y))
# print(len(x),len(y))
return purchase(total_num,x,y)
purchase(218,x,y)
total_price=0
print("\nThe best plan for buying 218 chicken wings is:\n")
while max(purchase_x) != 0:
pos=purchase_x.index(max(purchase_x))
print('Buy','%d' %x_bkup[pos],'wings for',purchase_x[pos])#,'times',y_bkup[pos])
total_price+=x_bkup[pos]*purchase_x[pos]*y_bkup[pos]
purchase_x[pos]=0
print('\nThe total cost for the best plan is : %.4f' %total_price)
输出:
The best plan for buying 218 chicken wings is:
Buy 25 wings for 8
Buy 6 wings for 3
The total cost for the best plan is : 242.8000
参考文献
[1] 动态规划. https://zh.wikipedia.org/wiki/动态规划
这里讲了DP的几个性质:
最优子结构性质。 如果问题的最优解所包含的子问题的解也是最优的,我们就称该问题具有最优子结构性质(即满足最优化原理)。最优子结构性质为动态规划算法解决问题提供了重要线索。
无后效性。 即子问题的解一旦确定,就不再改变,不受在这之后、包含它的更大的问题的求解决策影响。
子问题重叠性质。 子问题重叠性质是指在用递归算法自顶向下对问题进行求解时,每次产生的子问题并不总是新问题,有些子问题会被重复计算多次。动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只计算一次,然后将其计算结果保存在一个表格中,当再次需要计算已经计算过的子问题时,只是在表格中简单地查看一下结果,从而获得较高的效率。
基本介绍:
动态规划在查找有很多重叠子问题的情况的最优解时有效。它将问题重新组合成子问题。为了避免多次解决这些子问题,它们的结果都逐渐被计算并被保存,从简单的问题直到整个问题都被解决。因此,动态规划保存递归时的结果,因而不会在解决同样的问题时花费时间。
动态规划只能应用于有最优子结构的问题。最优子结构的意思是局部最优解能决定全局最优解(对有些问题这个要求并不能完全满足,故有时需要引入一定的近似)。简单地说,问题能够分解成子问题来解决。
[2] Python numpy 提取矩阵的某一行或某一列 https://blog.csdn.net/luoganttcc/article/details/74080768
这里讲了怎么提取numpy矩阵的某一列,如 a[:,0]
[3] Python使用pandas处理CSV文件的实例讲解. https://www.jb51.net/article/142430.htm
这里讲了下pandas的索引,但是我还是使用索引失败了,显示没有,很尴尬。
[4] python中利用pandas读写csv文件。 https://www.cnblogs.com/ystwyfe/p/8289044.html
[5] python之pandas简单介绍及使用(一) https://www.cnblogs.com/misswangxing/p/7903595.html
这里介绍了下series和dataframe,还是挺有科普意义的。
[6] python之pandas用法大全. https://www.jb51.net/article/136360.htm
pandas的基本用法,函数之类的,还是可以的。
[7] 使用python读写CSV文件的三种方法 https://blog.csdn.net/u013555719/article/details/79293198
在这里学到了用pandas读取csv文件。
[8] python pandas读文件(不把第一行作列属性) https://blog.csdn.net/SZU_Hadooper/article/details/78913644
这里讲了怎么跳过第一行,不过我没用上。
最后,我想纯粹得到除第一行(标签)外的数据,还是在console用的help(pd.core.frame.DataFrame)找到了它的一个values
[9] python 类属性的访问. https://blog.csdn.net/Rubik_Wong/article/details/79848809
这里科普了下__dict__方法,我试了下:pd.core.frame.DataFrame.dict
[10] python—调用类属性的方法. https://blog.csdn.net/niedongri/article/details/79669612
从这里知道.values应该是一个类属性吧,,,
[11] matplotlib设置坐标轴. https://blog.csdn.net/xtingjie/article/details/71156743
这个让我知道怎么写plt.xticks,yticks函数。
但是主要还是得靠help(plt.xticks) (注意xticks后面是没有()的,不然就变成调用函数了…)
[12] python Matplotlib画图之调整字体大小的示例. https://www.jb51.net/article/128549.htm
这个告诉我如何控制字体大小。
[13] python matplotlib 画图刻度、图例等字体、字体大小、刻度密度、线条样式设置. https://blog.csdn.net/u010358304/article/details/78906768
更细致的讲解。同[12]
[14] python中寻找list中的最值和所对应的索引 https://blog.csdn.net/sinat_32547403/article/details/53374726
告诉我这个numpy矩阵转list的函数,是aa.tolist() aa是numpy矩阵。
[15] Python命名规范 https://blog.csdn.net/zhangzeyuaaa/article/details/78574919
告诉我文件名全小写,可以加入下划线提高可读性。
函数名的话:
函数名应该为小写,可以用下划线风格单词以增加可读性。如:myfunction,my_example_function。
注意:混合大小写仅被允许用于这种风格已经占据优势的时候,以便保持向后兼容。
[16] Python List remove()方法 http://www.runoob.com/python/att-list-remove.html
该方法没有返回值但是会移除列表中的某个值的第一个匹配项。
[17] python列表的三种删除方法 https://www.cnblogs.com/wrnb/p/8846213.html
可以用del aa[i]删除列表第i个位置的元素。
也可以用pop删除最后一个元素
还可以用remove。
[18] 背包问题详解:01背包、完全背包、多重背包 https://blog.csdn.net/na_beginning/article/details/62884939
在这里学会了01、完全、多重背包问题的解法。此外,我把这些C++程序都转成了python程序。
看来做什么都还是要动手啊!!!
不要说自己没理解理论,可以边做边理解的。!!!
[19] 背包问题(转自背包九讲+对应题目) http://www.cnblogs.com/fht-litost/p/9204147.html
这个讲的很强了算。