InfoGAN
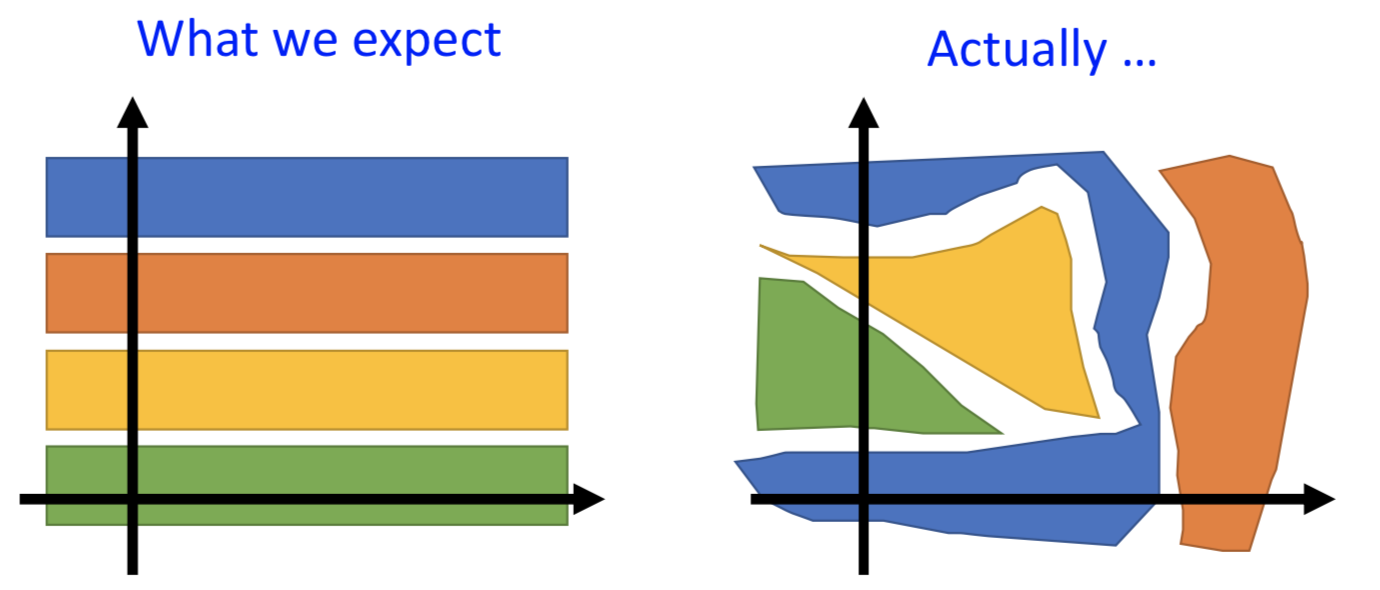
期望的是 input 的每一个维度都能表示输出数据的某种特征。但实际改变输入的一个特定维度取值,很难发现输出数据随之改变的规律。
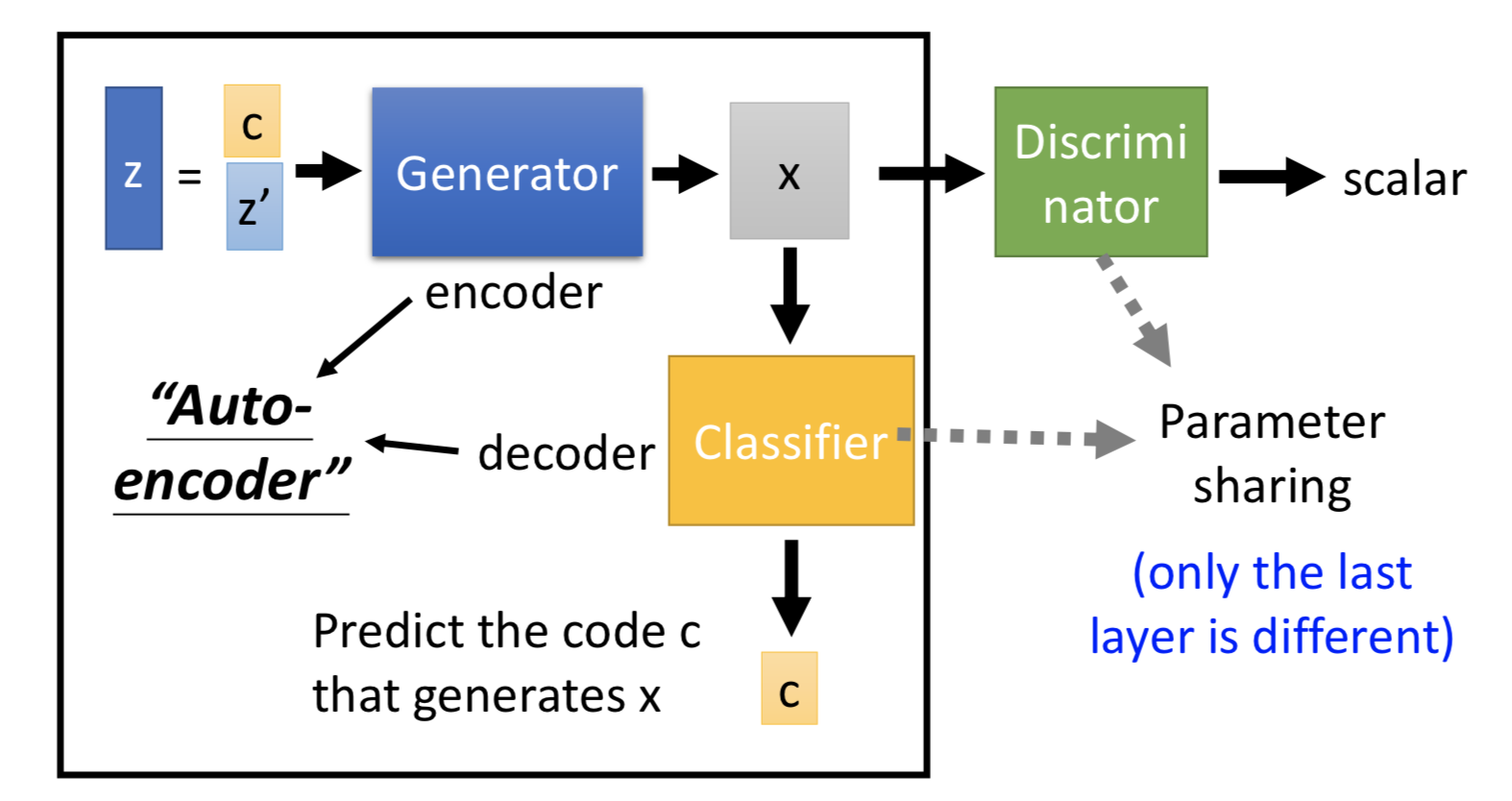
InfoGAN 就是想解决这个问题。在 GAN 结构以外,把输入 z 分成两个部分 c 和 z' ,然后根据 generated data x 来预测给到 generator 的 c 是什么,这里的ae 做的事情是 code-x-code。同时还需要 discriminator 来配合,x 还必须要足够像目标数据(要不 generator 直接把 c 复制过来就最容易让 classifer 预测对)。
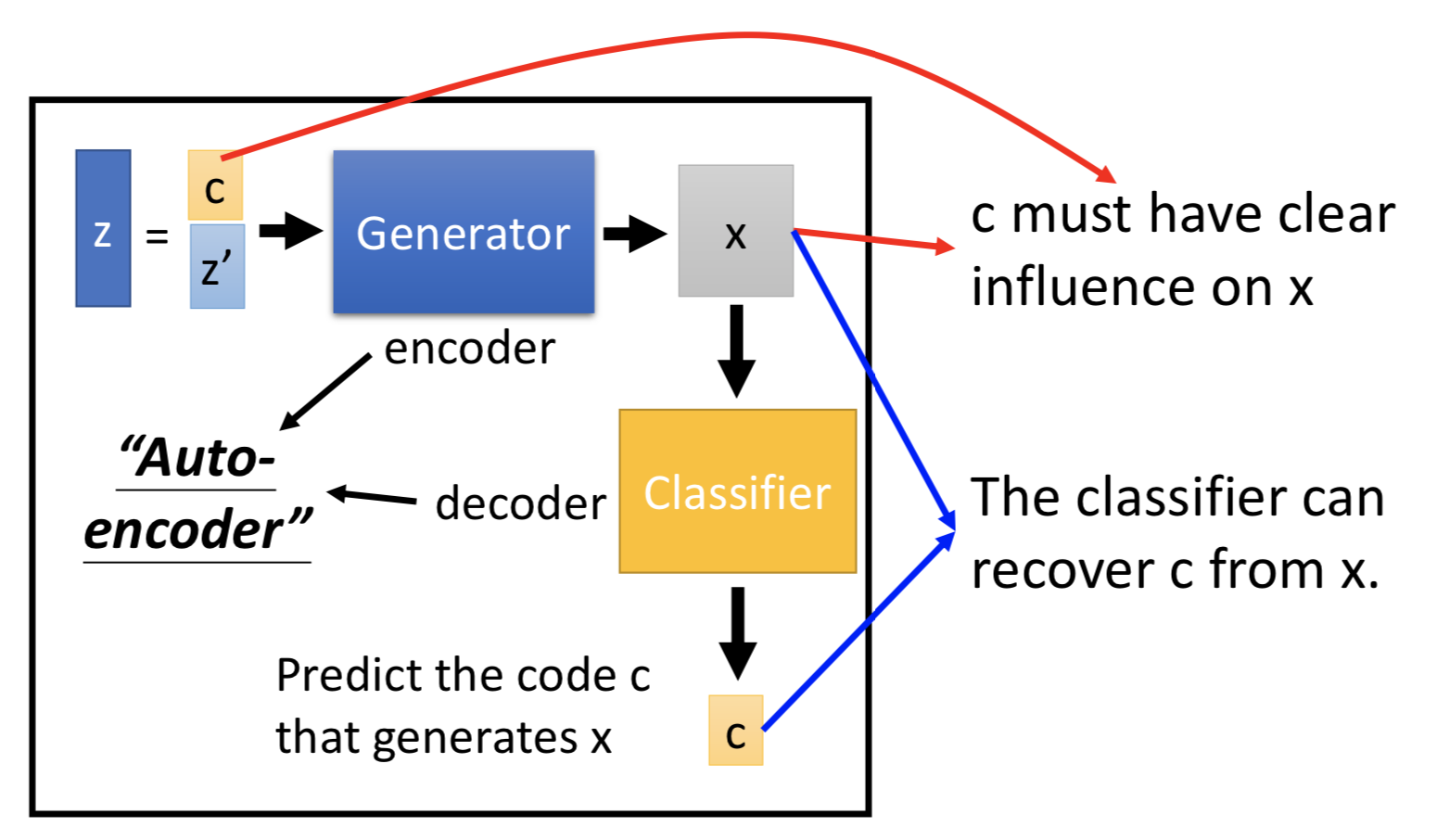
为了要让 classifer 可以成功从 x 中预测原来的 c(能反推回去),那 generator 就要让 c 的每一个维度都对 output 有一个明确的影响。就让 z' 去表示那些无法解释的特征。

VAE-GAN
可以看作用 GAN 来强化 VAE(让VAE生成的数据更加realistic),也可以看作用 VAE 来强化 GAN(原本的 GAN 是随机从 z 到 x,现在训练的时候 generator 还要尽可能好地重构 z 原本的 x,从一开始就知道一个 z 它对应的 x 应该是什么样,所以 VAE-GAN 训练会稳定一些)
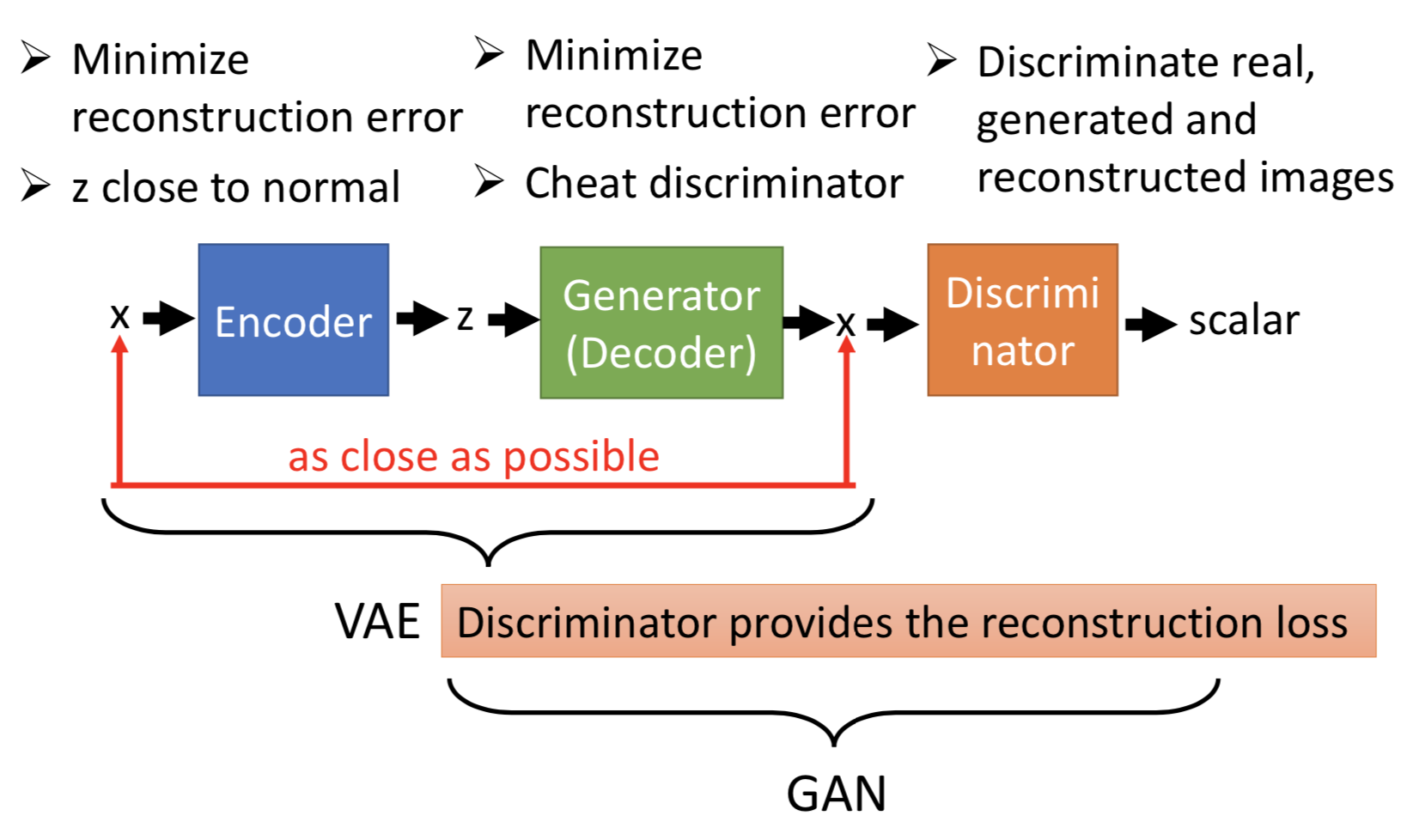
训练流程。其中,原本的真实数据 x 、VAE 从 x 经过 encoder 得到 z~ 再经过 decoder 生成的 x~ (重构)、从 P_z 中采样出来的 z 经过 generator 生成的 x^ (生成)。训练 VAE 的目标是,encoder 让后验分布P_ z~ | x 尽可能服从高斯并且重构误差越小越好;decoder 让重构误差越小越好并且生成数据越像真实数据越好;discriminator 给真实数据 x 高分给生成和重构低分。

BiGAN (ALI)
encoder 和 decoder 不直接相连,而是通过共同骗过 discriminator 来实现互逆映射。和ae比起来,理想上最佳的结果可能是一样的,但是 BiGAN 的 ae 更能够抓住语义上的信息(比如可以从一只鸟重构到另一只不同的鸟,但仍然还是鸟)
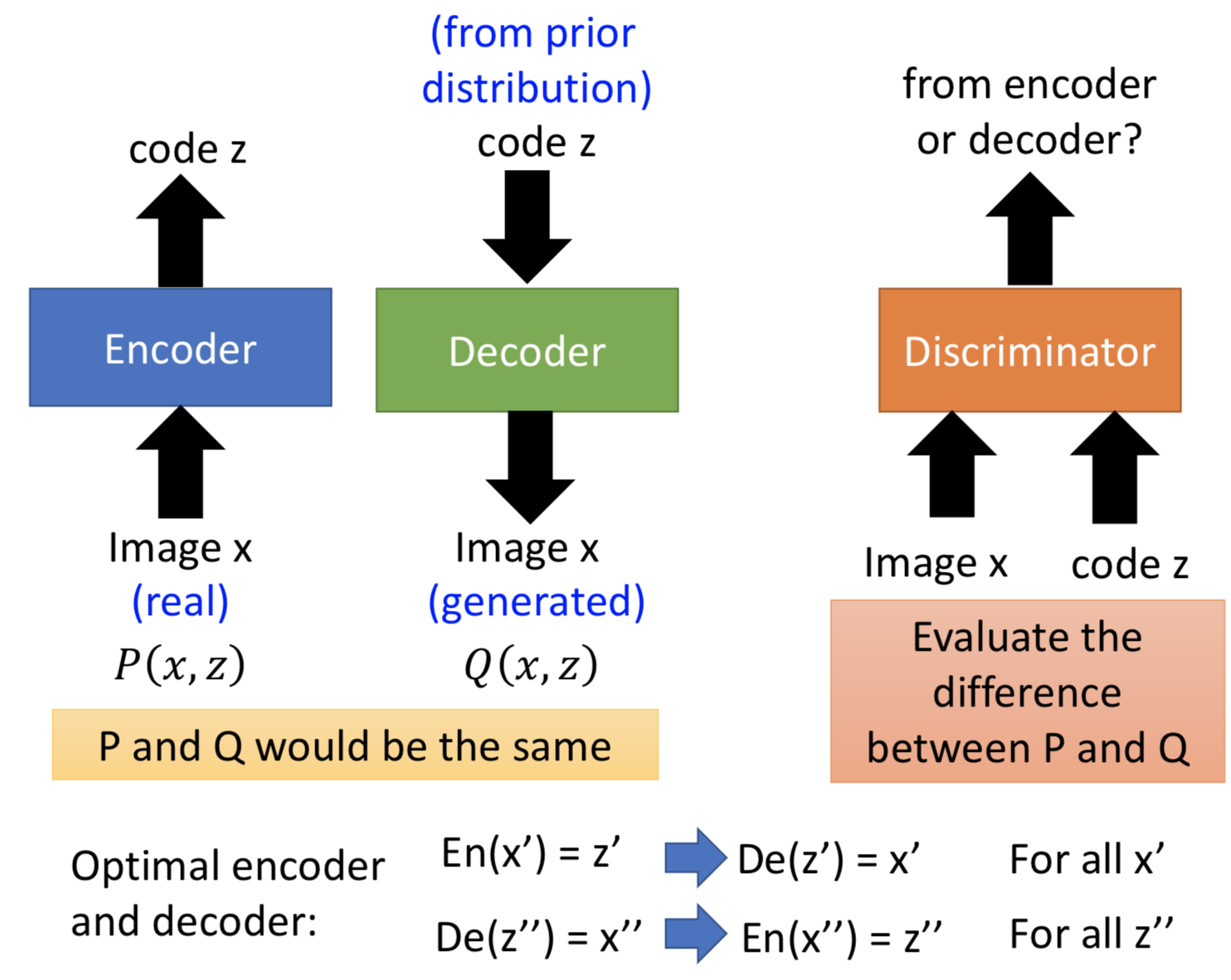
训练过程:

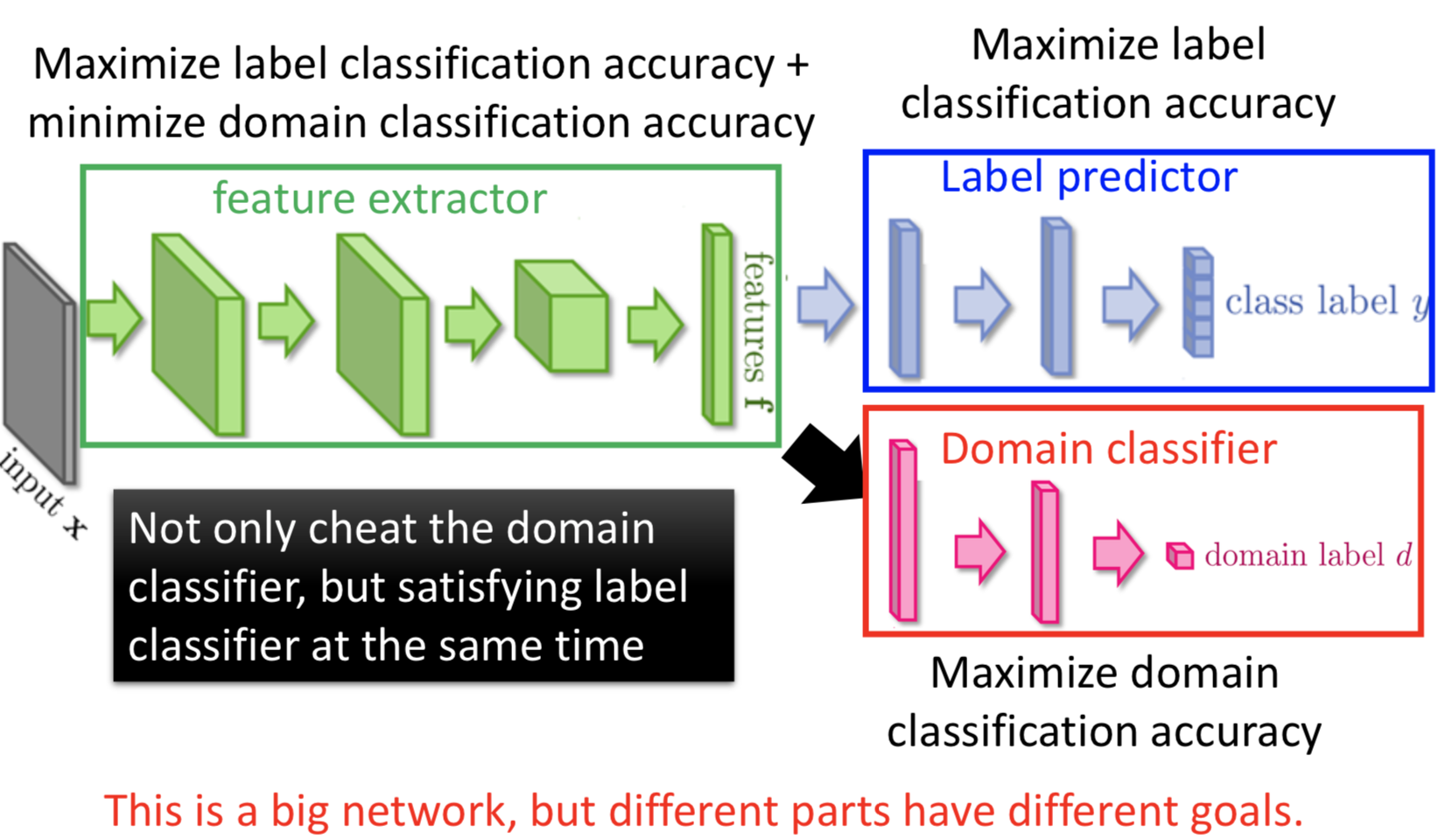
Domain-adversarial Training
需要用 generator 从不同的 domain 抽出特征,可以同分布。

实现方法就是,两个分类器既要让 label 分类正确,也要让 domain-label 分类正确;而特征抽取要让 label 正确但 domain 分不出来