版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/hongbin_xu/article/details/83861035
原文:Distilling the Knowledge in a Neural Network
Distilling the Knowledge
1、四个问题
-
要解决什么问题?
-
神经网络压缩。
-
我们都知道,要提高模型的性能,我们可以使用ensemble的方法,即训练多个不同的模型,最后将他们的结果进行融合。像这样使用ensemble,是最简单的能提高模型性能的方法,像kaggle之类的比赛中大家也都是这么做的。但是使用多个深度网络模型进行ensemble常常会有十分巨大的计算开销,而且算起来整个算法中的模型也会非常大。
-
这篇文章就是为了解决这个问题,提出一套方法,将一个ensemble中的知识信息压缩到一个小模型中,让最终的模型更易于部署,节约算力。
-
-
用了什么方法解决?
- 提出一种 **知识蒸馏(Knowledge Distillation)**方法,从大模型所学习到的知识中学习有用信息来训练小模型,在保证性能差不多的情况下进行模型压缩。
- 知识蒸馏:
- 将一个训练好的大模型的知识通过迁移学习手段迁移给小模型。
- 换成大白话说就是:先训练一个复杂的网络,然后再使用这个网络来辅助训练一个小网络;相当于大网络是老师,小网络是学生。
- 知识蒸馏:
- 提出一种新的**集成模型(Ensembles of Models)**方法,包括一个通用模型(Generalist Model)和多个专用模型(Specialist Models),其中,专用模型用来对那些通用模型无法区分的细粒度(Fine-grained)类别的图像进行区分。
- 提出一种 **知识蒸馏(Knowledge Distillation)**方法,从大模型所学习到的知识中学习有用信息来训练小模型,在保证性能差不多的情况下进行模型压缩。
-
效果如何?
- 文中给了一些语音识别等领域的实验,通过知识蒸馏训练得到的小模型的准确率虽不及大模型,但能比较接近了,效果也比较不错。
-
还存在什么问题?
- 虽然思想很简单,实际使用时还需要较多的trick,很难保证每次训练都能取得很好的效果。
2、论文概述
2.1、知识蒸馏(Knowledge Distillation)
- 对于多分类任务的大模型来说,我们通常都是希望最大化输出概率的log值,来获取准确的预测结果。然而,这么做会有一个副作用,就是会赋予所有的非正确答案一定的概率,即使这些概率值都很小。
- 这些非正确答案的相对概率,隐含了大模型在训练中倾向于如何泛化的信息。
- 为此,Hinton等人在论文中提出了soft target的概念。
- **soft target **指的是大模型最后输出的概率预测值,即softmax层的输出。
- 相对的,就有hard target,指的是数据集的标签了。
- 给softmax加入蒸馏的概念:
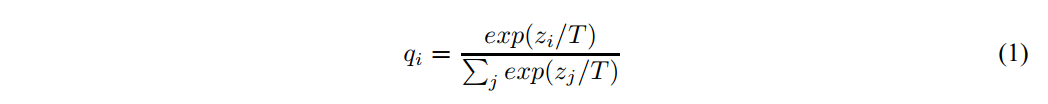
- 公式中的 表示“温度”。使用它的目的就是,让输出的softmax更平滑,分布更均匀,同时保证各项之间的大小相对关系不变。
- 时,上式就是平常使用的softmax函数。

- 上图摘自知乎,根据图很方便理解。
- 当我们不知道数据集的label时,可以直接使用大模型的soft target来训练小模型。训练的损失函数是cross-entropy。
- 当我们已知数据集的label时,可以将soft target和小模型预测值的cross-entropy与hard target和小模型预测值得cross-entropy进行加权求合,权重参数为 。这种方法得到的效果会更好。
- 实现流程:

2.2、distillation在特殊情况下相当于匹配logits(Matching logits is a special case of distillation )
- 再重复一遍,知识蒸馏(Knowledge Distillation)在特殊情况下相当于logits。
- 下式是cross-entropy到logit的梯度计算公式:
- 是大模型(cumbersome model)产生的logits, 是小模型(distillation model)的logits。
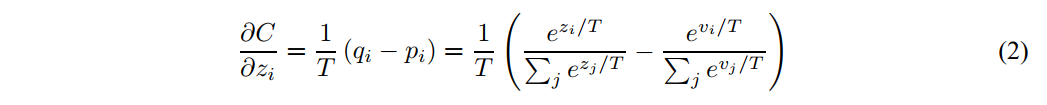
- 如果温度很高,即 很大,那么:
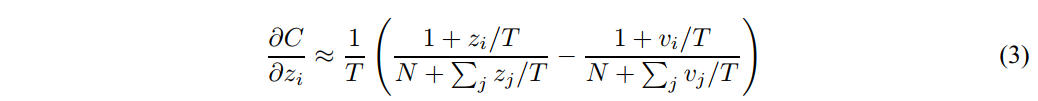
- 假设logits的均值均为0,即: 。则有:
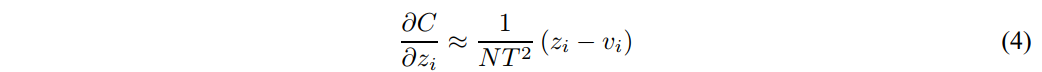
- 所以,在 很大且logit均值为0时,知识蒸馏就相当于标签匹配: 。
- 当T较小时,蒸馏更加关注负标签,在训练复杂网络的时候,这些负标签是几乎没有约束的,这使得产生的负标签概率是噪声比较大的,所以采用更大的T值(上面的简化方法)是有优势的。而另一方面,这些负标签概率也是包含一定的有用信息的,能够用于帮助简单网络的学习。这两种效应哪种占据主导,是一个实践问题。(注:我也不是很理解论文中的这段,简单点说,T就是个超参数,需要你自己调。)
2.3、在大数据集上训练专家模型(Training ensembles of specialists on very big datasets )
- 当数据集非常巨大以及模型非常复杂时,训练多个模型所需要的资源是难以想象的,因此作者提出了一种新的集成模型(ensemble)方法:
- 一个generalist model:使用全部数据训练。
- 多个specialist model(专家模型):对某些容易混淆的类别进行训练。
- specialist model的训练集中,一半是由训练集中包含某些特定类别的子集(special subset)组成,剩下一半是从剩余数据集中随机选取的。
- 这个ensemble的方法中,只有generalist model是使用完整数据集训练的,时间较长,而剩余的所有specialist model由于训练数据相对较少,且相互独立,可以并行训练,因此训练模型的总时间可以节约很多。
- specialist model由于只使用特定类别的数据进行训练,因此模型对别的类别的判断能力几乎为0,导致非常容易过拟合。
- 解决办法:当 specialist model 通过 hard targets 训练完成后,再使用由 generalist model 生成的 soft targets 进行微调。这样做是因为 soft targets 保留了一些对于其他类别数据的信息,因此模型可以在原来基础上学到更多知识,有效避免了过拟合。
- 实现流程:
