【论文泛读】 知识蒸馏:Distilling the knowledge in a neural network
文章目录
2022.5.26-2022.5.29
论文链接:Distilling the knowledge in a neural network
知识蒸馏(Knowledge Distillation)是一种模型压缩方法,由深度学习三巨头Hinton老爷子在2015年提出。深度学习在计算机视觉、语音识别、自然语言处理等内的众多领域中均取得了令人难以置信的性能。但是,大多数模型在计算上过于昂贵,无法在移动端或嵌入式设备上运行。因此需要对模型进行压缩,且知识蒸馏是模型压缩中重要的技术之一。现如今,知识蒸馏被广泛的用于模型压缩和迁移学习当中,这篇就是知识蒸馏的开山之作,今天我也一起读一下这篇论文,学习学习。
文章的标题是Distilling the Knowledge in a Neural Network,那么说明是神经网络的知识呢?一般认为模型的参数保留了模型学到的知识,因此最常见的迁移学习的方式就是在一个大的数据集上先做预训练,然后使用预训练得到的参数在一个小的数据集上做微调(两个数据集往往领域不同或者任务不同)。例如先在Imagenet上做预训练,然后在COCO数据集上做检测。在这篇论文中,作者认为可以将模型看成是黑盒子,知识可以看成是输入到输出的映射关系。因此,我们可以先训练好一个teacher网络,然后将teacher的网络的输出结果 q q q作为student网络的目标,训练student网络,使得student网络的结果 p p p 接近 q q q,这就是论文的基本思想。

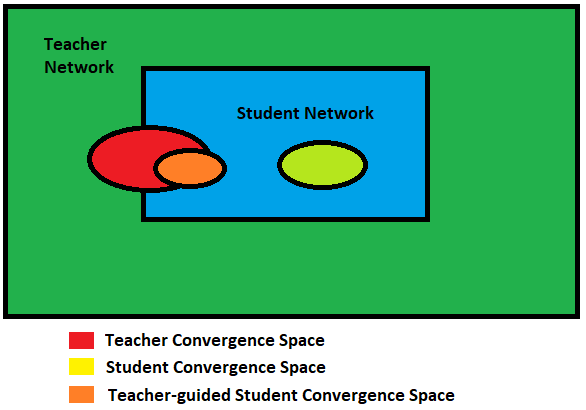
首先可以思考一个问题,知识蒸馏和从头训练一个网络有什么不同
这样和从头训练一个模型有什么不一样?
显然,模型越复杂,理论搜索空间越大。但是,如果我们假设较小的网络也能实现相同(甚至相似)的收敛,那么教师网络的收敛空间应该与学生网络的解空间重叠。
不幸的是,仅凭这一点并不能保证学生网络收敛在同一点。学生网络的收敛点可能与教师网络有很大的不同。但是,如果引导学生网络复制教师网络的行为(教师网络已经在更大的解空间中进行了搜索),则其预期收敛空间会与原有的教师网络收敛空间重叠。
摘要 Abstract
要提高几乎所有机器学习算法的性能,一个非常简单的方法是在同一个数据上训练许多不同的模型并集成平均它们的预测效果。不幸的是,使用集成模型进行预测是很麻烦的,而且可能计算成本太高,不能部署到大量用户,特别是当单个模型是大型神经网络时。有研究表示,将集成模型中的知识压缩到易于部署的单个模型是有可能的,我们使用不同的压缩技术进一步发展了这种方法。
我们在MNIST上取得了一些令人惊喜的结果,并且我们表明,通过将集成模型的知识提炼到单个模型中可以显著改进大量应用于商业系统的语音模型。我们还引入了一种新型的由一个或多个完整模型和许多能够学习区分完整模型会混淆的细粒度类的“专家模型”。不同于“专家模型”的混合,这些“专家模型”可以快速地并行训练。
介绍 Introduction
许多昆虫的幼年形态是最适合从环境中汲取能量和营养的,而成虫形态则完全不同,更适合旅行和繁殖等不同需求。昆虫的类比表明我们可以训练非常复杂的模型,其易于从数据中提取出结构。这个复杂的模型可以是独自训练模型的集成,也可以是一个用强大正则器如 d r o p o u t dropout dropout训练的单个大模型。一旦复杂模型训练完毕,之后我们可以使用一种不同的训练方式,称之为“蒸馏”,将知识从复杂的模型(称之为 t e a c h e r teacher teacher模型)转移到更易于部署的小模型(称之为 s t u d e n t student student模型)中。

对于 t e a c h e r teacher teacher模型,其能够学习区分大量的类别,正常情况下,训练目标是最大化正确类别的平均对数概率,但这种**学习的副作用是训练的模型会将概率分配给错误的类别上,虽然这些概率值可能很小,但一些错误类别比其他错误类别的概率值大很多。**比如:一辆宝马车的照片可能有很小的概率被误认为垃圾车,但是仍比被误认为一根萝卜的概率大出很多。在错误类别上的相对概率可以反映出模型是如何进行泛化的,这也是模型学到的知识,教师网络可能可以从相关性的概率告诉学生如何去泛化。
通常上来说,我们认为模型学习到的参数代表着“知识”,这是无法迁移的,如果将模型参数定义为“知识”是无法进行操作的。论文中提出可以利用 t e a c h e r teacher teacher模型的类别概率作为 “软目标” 用于训练 s t u d e n t student student模型,概率中含有许多隐式的信息。
**当 s o f t soft soft t a r g e t target target具有高熵值,在训练每一个样本时软目标能够提供比 h a r d hard hard t r a g e t traget traget( s t u d e n t student student模型的 t r u t h g r o u n d t r u t h truthgroundtruth truthgroundtruth)更多的信息并且训练每一个样本时的梯度差异更小。因此,与 t e a c h e r teacher teacher模型相比, s t u d e n t student student模型训练数据要少得多,使用的学习率也高得多。**这一部分其实也是比较容易思考的,比如我们的硬目标只有一个数据,比如(0,0,1),我们只能从中学习正确的目标,但是不能得到其他的数据,但是对于我们的 t e a c h e r teacher teacher模型来说,他输出的是我们的软目标,里面包含着概率,比如(0.1,0.3,0.6),这个熵明显更高,包含着更多的信息,也能获取更多的知识。

- Hard-target:原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0。
- Soft-target:Teacher模型softmax层输出的类别概率,每个类别都分配了概率,正标签的概率最高。
如在MNIST数据集中做手写体数字识别任务,假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率会比其他负标签类别高;而另一个"2"更加形似"7",则这个样本分配给"7"对应的概率会比其他负标签类别高。这两个"2"对应的Hard-target的值是相同的,但是它们的Soft-target却是不同的,由此我们可见Soft-target蕴含着比Hard-target更多的信息。

**这是非常有价值的信息,它在数据上定义了丰富的相似性结构(例如,它说明了哪个版本的2 看起来像3 ,哪个像7 ),但它对迁移阶段的交叉熵代价函数的影响很小,因为这些概率值接近零。**之前研究的作者,解决这个的方法是利用 l o g i t s logits logits对未经过 s o f t m a x softmax softmax函数的值,而不是经过 s o f t m a x softmax softmax函数之后的概率值,然后将 t e a c h e r teacher teacher的 l o g i t s logits logits值和 s t u d e n t student student的 l o g i t s logits logits值的平方差作为最小化目标。
在介绍知识蒸馏方法之前,首先得明白什么是Logits。我们知道,对于一般的分类问题,比如图片分类,输入一张图片后,经过DNN网络各种非线性变换,在网络最后Softmax层之前,会得到这张图片属于各个类别的大小数值 z i z_i zi,某个类别的 z i z_i zi数值越大,则模型认为输入图片属于这个类别的可能性就越大。什么是Logits? 这些汇总了网络内部各种信息后,得出的属于各个类别的汇总分值 z i z_i zi,就是Logits,i代表第i个类别, z i z_i zi代表属于第i类的可能性。因为Logits并非概率值,所以一般在Logits数值上会用Softmax函数进行变换,得出的概率值作为最终分类结果概率。Softmax一方面把Logits数值在各类别之间进行概率归一,使得各个类别归属数值满足概率分布;另外一方面,它会放大Logits数值之间的差异,使得Logits得分两极分化,Logits得分高的得到的概率值更偏大一些,而较低的Logits数值,得到的概率值则更小。

**论文中,我们提出了一个通用的解决方案,叫做“蒸馏”,是提高 s o f t m a x softmax softmax最终值的温度,直到 t e a c h e r teacher teacher模型产生一个合适的软目标集。**当训练 s t u d e n t student student 模型来匹配这些软目标时,我们使用同样高的温度。 稍后说明,之前研究中直接 l o g i t s logits logits实际上只是蒸馏的一种特殊情况。我们还可以用这种方法在未标记的数据集中训练小模型,也可以用原始的数据集,这样我们可以进行一个扩充数据集操作。我们可以从下图看的出来,我们可以从 t e a c h e r teacher teacher模型中得到软目标,然后对 s t u d e n t student student模型进行训练。

蒸馏 Distillation
神经网络通常使用 s o f t m a x softmax softmax输出层来生成类的概率,然后这一部分会对每一个 l o g i t s z i logits\ z_i logits zi生成对应的概率 q i q_{i} qi
q i = exp ( z i / T ) ∑ j exp ( z j / T ) q_{i}=\frac{\exp \left(z_{i} / T\right)}{\sum_{j} \exp \left(z_{j} / T\right)} qi=∑jexp(zj/T)exp(zi/T)
其中 T T T 表示温度,正常情况下设为 1.0 1.0 1.0 ,使用更高的 T T T 可以生成更加平滑的类概率分布。
最简单的蒸馏形式是通过在迁移集训练上student模型将知识迁移到student模型中,在迁移集中得每个样本使用由将温度 T T T 设置得 很高的teacher 模型生成软目标分布。在训练student模型时使用相同的高温,但在训练结束后,其使用温度 T = 1.0 T=1.0 T=1.0 。在训练 student模型时,我们使用两个不同目标函数的加权平均,形式如下:
cost function = CroEntropy ( y s , y t ) + ∣ α Cross Entropy ( y s , y ) \text { cost function }=\text { CroEntropy }\left(y_{s}, y_{t}\right)+\mid \alpha \operatorname{Cross} \operatorname{Entropy}\left(y_{s}, y\right) cost function = CroEntropy (ys,yt)+∣αCrossEntropy(ys,y)
其中CrossEntropy ( ∗ ) (*) (∗) 为交叉熵函数, y s y_{s} ys 表示student模型的预测结果, y s y_{s} ys 表示teacher模型的预测结果, y y y 是student模型的真实 标签。第一个交叉熵函数是student模型预测结果与软目标的交叉熵,其使用与训练该软目标的teacher中一样的温度。第二个目标函数 是student模型与真实标签的交叉熵,其温度设置为 1.0 1.0 1.0 。
 我们发现最好的结果是在第二个目标函数上使用较低的权值(即: α \alpha α 取小值) 。由于软目标产生的梯度缩放了 1 / T 2 1 / T^{2} 1/T2 ,因而在同时使 用软目标和硬目标时,将软目标的梯度乘以 T 2 T^{2} T2 是非常重要的。这确保了在实验过程中,如果用于蒸馏的温度发生改变,那么硬目标和软 目标的相对贡献大致保持不变。
我们发现最好的结果是在第二个目标函数上使用较低的权值(即: α \alpha α 取小值) 。由于软目标产生的梯度缩放了 1 / T 2 1 / T^{2} 1/T2 ,因而在同时使 用软目标和硬目标时,将软目标的梯度乘以 T 2 T^{2} T2 是非常重要的。这确保了在实验过程中,如果用于蒸馏的温度发生改变,那么硬目标和软 目标的相对贡献大致保持不变。
总结一下
-
应用蒸馏技术的大致流程如下图所示:

-
将 s t u d e n t student student模型在训练软目标时,要在高温环境下进行,即 T T T取一个较大的值,同时与它做交叉熵的 t e a c h e r teacher teacher模型的输出也要在相同的温度情况下
-
s t u d e n t student student的硬目标则在 T = 1 T=1 T=1情况下进行,并且总的优化目标是软目标和硬目标的加权和
蒸馏的一种特殊形式:直接Matching Logits
直接Matching Logits指的是,,直接使用softmax层的输入logits(而不再是输出)作为Soft target, 需要最小化的目标函数是Teacher模型和Student模型的logits之间的平方差, L logits = 1 2 ( z i − v i ) 2 L_{\text {logits }}=\frac{1}{2}\left(z_{i}-v_{i}\right)^{2} Llogits =21(zi−vi)2, 对 z i z_{i} zi 求梯度可得:
∂ L logits ∂ z i = z i − v i \frac{\partial L_{\text {logits }}}{\partial z_{i}}=z_{i}-v_{i} ∂zi∂Llogits =zi−vi
再看一般蒸馏中 L soft L_{\text {soft }} Lsoft 对 z i z_{i} zi 求梯度可得:
∂ C ∂ z i = 1 T ( q i − p i ) = 1 T ( e z i / T ∑ j e z j / T − e v i / T ∑ j e v j / T ) \frac{\partial C}{\partial z_{i}}=\frac{1}{T}\left(q_{i}-p_{i}\right)=\frac{1}{T}\left(\frac{e^{z_{i} / T}}{\sum_{j} e^{z_{j} / T}}-\frac{e^{v_{i} / T}}{\sum_{j} e^{v_{j} / T}}\right) ∂zi∂C=T1(qi−pi)=T1(∑jezj/Tezi/T−∑jevj/Tevi/T)
当 T → ∞ T \rightarrow \infty T→∞ 时, 有 z i T → 0 \frac{z_{i}}{T} \rightarrow 0 Tzi→0 和 v i T → 0 \frac{v_{i}}{T} \rightarrow 0 Tvi→0, 根据泰勒公式的一阶展开, 当 x → 0 x \rightarrow 0 x→0 时有 exp ( x ) → x + 1 \exp (x) \rightarrow x+1 exp(x)→x+1, 则有:
∂ C ∂ z i ≈ 1 T ( 1 + z i / T N + ∑ j z j / T − 1 + v i / T N + ∑ j v j / T ) \frac{\partial C}{\partial z_{i}} \approx \frac{1}{T}\left(\frac{1+z_{i} / T}{N+\sum_{j} z_{j} / T}-\frac{1+v_{i} / T}{N+\sum_{j} v_{j} / T}\right) ∂zi∂C≈T1(N+∑jzj/T1+zi/T−N+∑jvj/T1+vi/T)
此时, 假设 Logits 在每个样本上是零均值的, 则进一步近似:
∂ C ∂ z i ≈ 1 N T 2 ( z i − v i ) \frac{\partial C}{\partial z_{i}} \approx \frac{1}{N T^{2}}\left(z_{i}-v_{i}\right) ∂zi∂C≈NT21(zi−vi)
可见, 经过Softmax的蒸馏方式和直接Matching Logits的方式, 当温度 T → ∞ T \rightarrow \infty T→∞ 时Soft-target损 失函数部分是等价的, 即 Matching Logits是一般知识蒸馏方法的一种特殊形式。
对于蒸馏温度 T 的理解
在知识蒸馏中,需要使用高温将知识“蒸馏”出来,但是如何调节温度 T T T呢,温度的变化会产生怎样的影响呢?

温度 T T T 有这样几个特点:
- 原始的 s o f t m a x softmax softmax函数是 T = 1 T=1 T=1 时的特例; T < 1 T<1 T<1 时, 概率分布比原始更 “陡峭”, 也就是说, 当 T → 0 T \rightarrow 0 T→0 时, S o f t m a x Softmax Softmax 的输出值会接近于 H a r d − t a r g e t ; Hard-target; Hard−target; T > 1 T>1 T>1 时, 概率分布比原始更“平 缓"。
- 随着 T T T 的增加, S o f t m a x Softmax Softmax 的输出分布越来越平缓, 信息熵会越来越大。温度越高, $softmax $上各个值的分布就越平均, 思考极端情况, 当 T = ∞ T=\infty T=∞, 此时 s o f t m a x softmax softmax的值是平均分布的。
- 不管温度 T T T 怎么取值, S o f t − t a r g e t Soft-target Soft−target都有忽略相对较小的 p i p_{i} pi ( T e a c h e r Teacher Teacher模型在温度为 T \mathrm{T} T 时 s o f t m a x softmax softmax输出在第 i i i 类上的值) 携带的信息的倾向。
温度的高低改变的是 S t u d e n t Student Student模型训练过程中对负标签的关注程度。当温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大, S t u d e n t Student Student模型会相对更多地关注到负标签。
实际上,负标签中包含一定的信息,尤其是那些负标签概率值显著高于平均值的负标签。但由于 T e a c h e r Teacher Teacher模型的训练过程决定了负标签部分概率值都比较小,并且负标签的值越低,其信息就越不可靠。因此温度的选取需要进行实际实验的比较,本质上就是在下面两种情况之中取舍:
- 当想从负标签中学到一些信息量的时候,温度T应调高一些;
- 当想减少负标签的干扰的时候,温度T应调低一些;
总的来说, T T T的选择和 S t u d e n t Student Student模型的大小有关, S t u d e n t Student Student模型参数量比较小的时候,相对比较低的温度就可以了。因为参数量小的模型不能学到所有 T e a c h e r Teacher Teacher模型的知识,所以可以适当忽略掉一些负标签的信息。
最后,在整个知识蒸馏过程中,我们先让温度T升高,然后在测试阶段恢复“低温“( T = 1 T=1 T=1),从而将原模型中的知识提取出来,因此将其称为是蒸馏,实在是妙啊。
Experiment 实验
MNIST
在该数据集上,首先在60000个训练样本上训练了一个带有两个隐藏层 (每层有1200个单元) 的teacher网络,该网络使用 dropout和 weight-constraints的正则化方法。另外输入的图片在任意方向上抖动了两个像素。该网络取得了67个测试错误的结果,而一个带有 两个隐藏层 (每层有800个单元) 的student网络并不带正则方法取得了146个测试错误的结果。但如果这个student网络添加了由温度 设置为20的大网络软目标任务,则它的的测试错误结果为 74 个。这表明了软目标能够将大量的知识迁移到student网络中,其中包括了 从转译数据中学习到的如何泛化的知识,及时迁移数据集中不包含任何的转译。
当带有两层隐藏层的student网络中每个隐藏层中的单元数据超过 300 个时,所有高于8的温度设置都能得到相似的结果。但是将隐 藏层单元量急剧减小为 30 个时,温度在2.5-4之间的效果优于这个范围之外的温度设置。
我们尝试将迁移数据集中数字 3 的样本移除。因此从 student网络的观点看,数字 3 是一个从末见过的神秘数字。即使是这样, student网络也只造成了206个测试错误,其中133个是来自测试集中的1010个数字 3 。
speech recognition
第二个实验是在speech recognition领域,使用不同的参数训练了10个DNN,对这10个模型的预测结果求平均作为emsemble的结果,相比于单个模型有一定的提升。然后将这10个模型作为teacher网络,训练student网络。得到的Distilled Single model相比于直接的单个网络,也有一定的提升,结果见下表:

Training ensembles of specialists on very big dataset
在这一部分呢,实际上是与我们的知识蒸馏是无关的,和集成模型有点关系,他提出了一种专才模型的方法。
类似于我们可以用一部分模型来判断特定的一部分相似的类别,或者细粒度的类别,比如拉布拉多犬和田园犬以及各种犬科动物等等,专才模型对他们进行一个训练,然后多个专才模型进行训练,可以并行训练,各自互不干扰,所以训练速度是非常快的。
本文中作者是在Google自己的数据集上进行训练的,用了数据并行和模型并行的方法,得到的结果也是非常不错,我觉得在某一方面有特别多的启发,不过这一部分我觉得深究还是需要细看论文,就不在知识蒸馏领域讲集成学习了。
Discussion
论文展示了蒸馏在将一个集成模型或一个大的正则化模型中的知识迁移到一个小的student模型中效果良好。在MNIST任务 上,即使用于训练student模型的迁移集缺少一个或多个类的例子,蒸馏的效果也非常好。对于一个应用在安卓语音搜索中的深度声学模 型,我们表明训练一个集成的深度模型的几乎所有性能提高都能够提炼到一个大小相同的更易于部署的单一神经网络上。

总结
本文是知识蒸馏的早期文章之一,知识蒸馏是将teacher模型 (通常的大模型或集成模型) 的知识迁移到student模型(通常是小模型),具体做法是将teacher模型的学习到的类分类概率分布作为student模型学习的软目标,student模 型最终的目标函数是软目标与自身训练的硬目标的加权和。作者在 mnist任务和声学模型上进行实验,结果显示知识蒸馏的效果良好,能够将知识进行很好的迁移。文中作者还介绍了一种集成专家模型,能够对易于混淆的类别进行区分,并具有良好的并行性。本文知识蒸 馏主要有以下几个要点需要注意:
- 软目标需要在高温情况下进行 ( T T T 取较大值),而硬目标则为常规的 s o f t m a x s o f t m a x softmax 函数 ( T = 1.0 ) (T=1.0) (T=1.0)
- 软目标和硬目标的加权和作为最终优化目标时,软目标梯度更新时需要乘以 T 2 T^{2} T2
- 知识蒸馏有一定的防止过拟合的作用
- 知识蒸馏起到了与网络剪枝一样的效果,压缩了模型的大小并且保持了模型的性能
参考
- https://jishuin.proginn.com/p/763bfbd57a41
- https://www.bilibili.com/video/BV1N44y1n7mU/
- https://blog.csdn.net/ZY_miao/article/details/110182948