Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network"首次提出了知识蒸馏(暗知识提取)的概念,通过引入与教师网络(teacher network:复杂、但推理性能优越)相关的软目标(soft-target)作为total loss的一部分,以诱导学生网络(student network:精简、低复杂度)的训练,实现知识迁移(knowledge transfer)。
那什么是soft-target呢?与之对应的是hard-target,就是样本的真实标签,soft-target是teacher network的预测输出。
引进soft-target的原因是因为har-target的信息熵很低,soft target包含的信息量大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target就不会像hard target 那样只有马的index处的值为1,其余为0,而是在驴的部分也会有概率)。
这样做的好处就是表明这个图像除了像马更像驴一点,而不是车、人之类。
此外,当soft-target熵值较高时,相对hard-target,它每次训练可以提供更多的信息和更小的梯度方差,因此小模型可以用更少的数据和更高的学习率进行训练。
而这样的soft信息存在于概率中,以及label之间的高低相似性都存在于soft target中。但是如果soft targe是像这样的信息[0.98 0.01 0.01],就意义不大了,所以需要在softmax中增加温度参数T(这个设置在最终训练完之后的推理中是不需要的)。
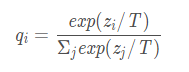
T就是调节参数,一般设为1。T越大,分类的概率分布越“软”
loss是两者的结合,Hindon认为,最好的训练目标函数为下图,并且第一个权重要大一点
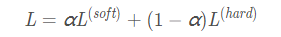
算法框架示意图如下:
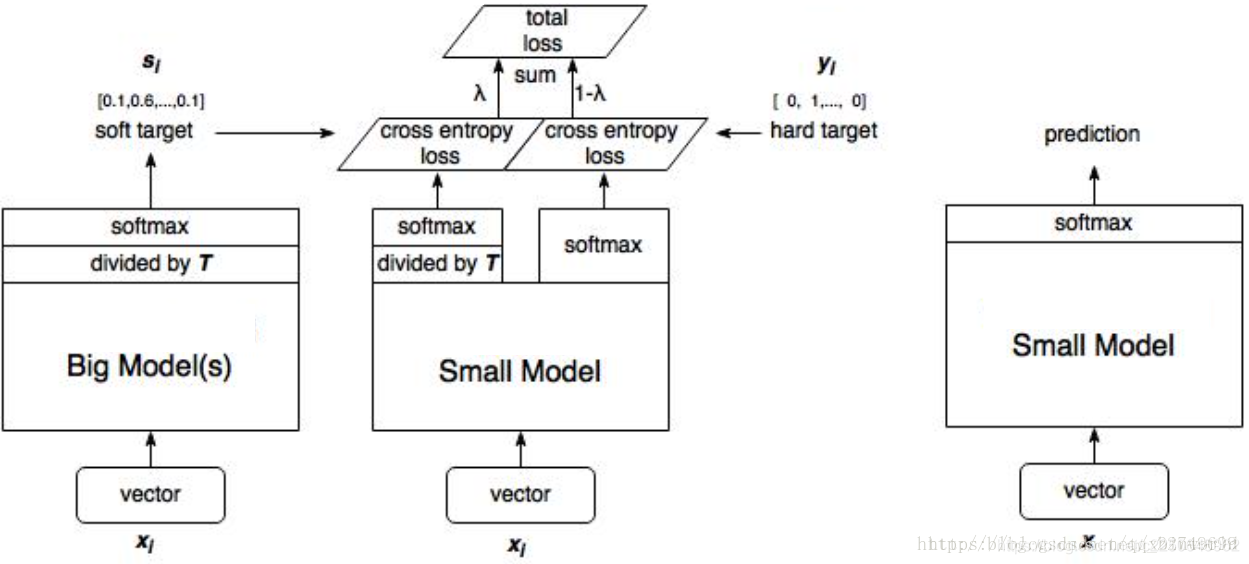
步骤如下:
- 使用hard-target训练大模型。
- 计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
- 训练小模型,小规模的神经网络用相同的T值来学习由大规模神经产生的软目标,接近这个软目标从而学习到数据的结构分布特征;在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
- 预测时,将训练好的小模型按常规方式(右图)使用。
知识蒸馏,简单来说就是利用一个复杂度高的大模型进行训练,得到类别概率分布(soft-target),然后利用这个概率分布的损失和真实标签(hard-target)的概率分布损失做加权,形成小模型的total损失来知道小模型学习。
至于为何要引入这个soft-target,是因为大模型学习得到的soft-target包含了很多类之间的信息(我觉得就是学习了很正确的类别之间的信息得到的,所以可以反过来说它包含了很多类别之间的信息,包含类别之间的相似度等。)
这个soft-targe我感觉跟label-smooth有点像,只是label-smooth并没有用到把label-smooth后的标签和真实标签结合在一起指导模型学习。
soft-target,可以理解为是学习得到的,更加准确的类似label-smooth后的值。
而label-smooth是认为指定的,存在不准确因素。
