论文地址:http://papers.nips.cc/paper/7358-kdgan-knowledge-distillation-with-generative-adversarial-networks.pdf
github地址:https://github.com/xiaojiew1/KDGAN/
Motivation
在训练轻量级分类器时,知识蒸馏虽只需少量样本和训练次数就能收敛,但难以从teacher那里学习到真实的数据分布(real data),而另一种方法,通过GAN对分类器进行对抗性训练学习数据的真实分布,却由于高方差的梯度更新,需要很长时间才能达到平衡。为了解决上述限制,本文提出KDGAN的框架,该框架由一个分类器(student net)、一个teacher net和一个discriminator组成。分类器和教师通过蒸馏损失相互学习,并通过对抗性损失对分类器进行对抗性训练。
Method
文章以多标签分类任务为例展开研究。KDGAN的框架如图所示。除了KD中的teacher net到分类器的蒸馏损失以及NaGAN(naive gan)中的分类器和discriminator的对抗损失外,作者还定义了从分类器到teacher net的蒸馏损失以及teacher net与discriminator之间的对抗性损失。即分类器与teacher net均作为generator,生成的标签均被discriminator视为假。同时,分类器和teacher net通过互相蒸馏软标签的方式互相学习彼此的知识,从而就生成什么伪标签达成一致。

为了加快KDGAN的训练,作者一方面经验性地认为分类器接收到的梯度中来自teacher的梯度的方差会小于discriminator的梯度的方差,因此加权平均后小于原来只用GAN训练的梯度方差,从而能够快速收敛。两一方面,由于分类器和teacher生成的离散样本是不可微的,因此作者使用Gumbel-Max技巧将离散样本的分布转化为连续的分布。从而能够传递梯度值。
模型的具体算法步骤如下:其中,三个部分都需要经过预训练,接着在每个epoch中依次更新三个部分数次。

Experiment
KD loss:L2loss、KL Divergence
实验次数:10次
应用场景:模型压缩,图像标签推荐
数据集:MNIST,CIFAR-10,YFCC100M
Results
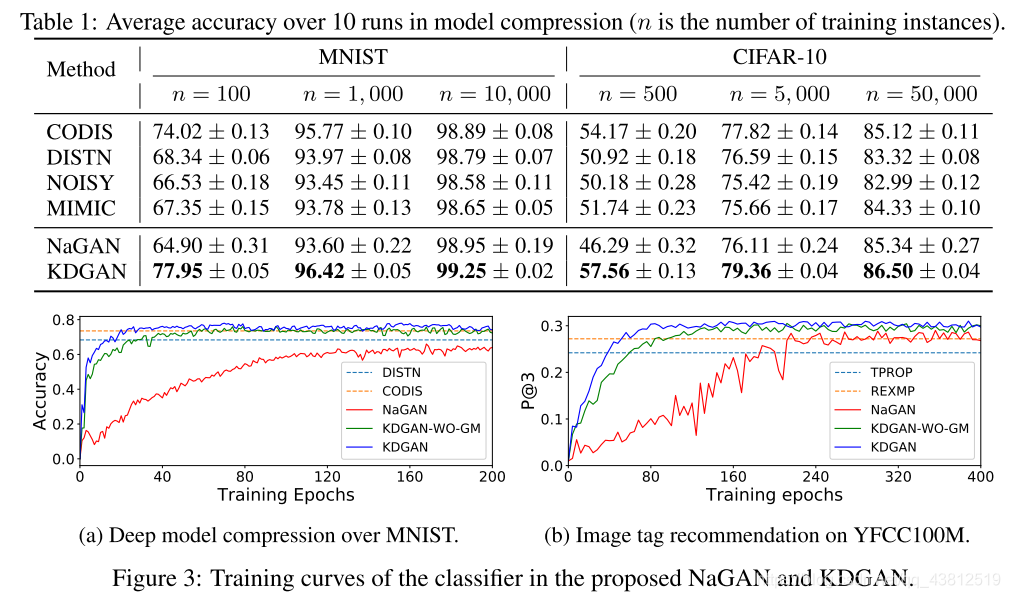
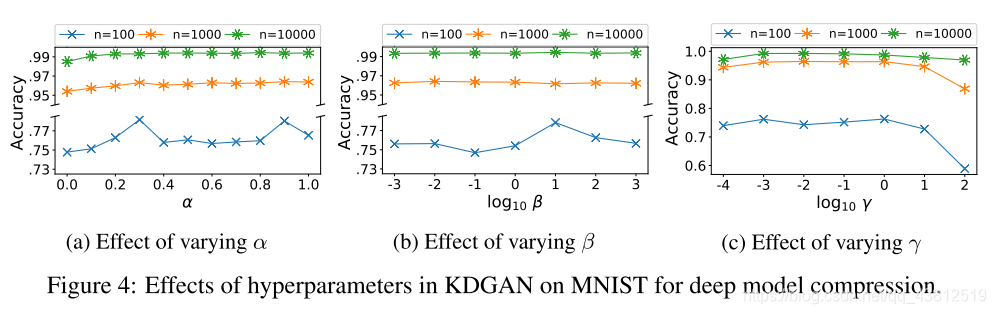
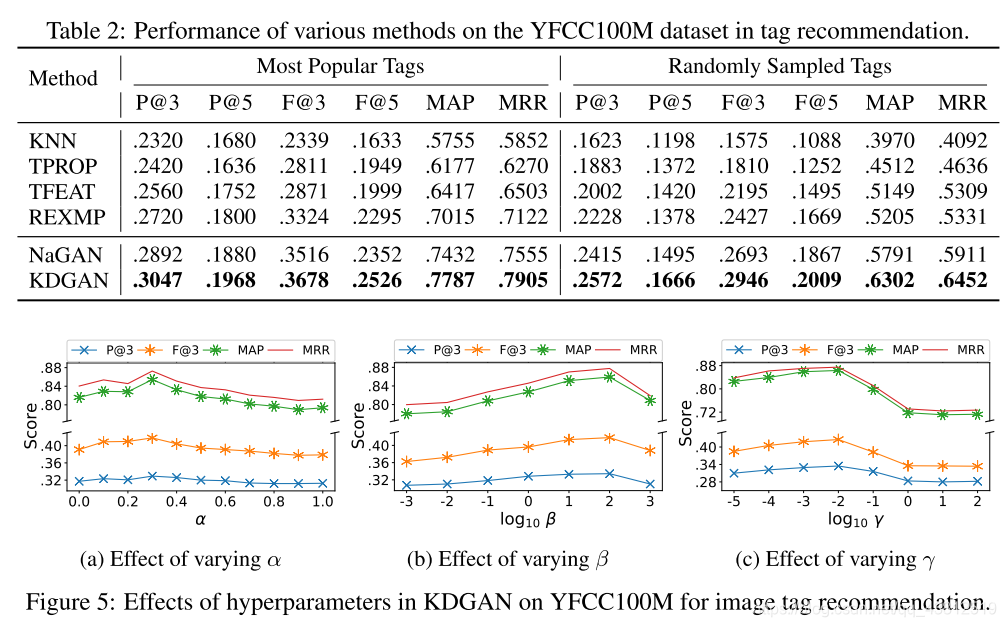
Thoughts
和我想象的KDGAN不太一样,有必要复现一下。