论文:Joint Face Detection and Alignment Using Multitask
Cascaded Convolutional Networks
简称MTCNN,是一个用于人脸检测与对齐的三级联CNN网络。
论文主要提出一个从粗到细的级联多任务框架用于人脸的检测与对其,并提出online hard sample mining strategy,该策略可以提升性能。
online hard sample mining strategy:训练过程中,对loss进行排序,根据排序结构选择N个loss值最大的样本进行反向传播,更新权重,即侧重对Loss值大(hard sample)进行权重调整,当然这里由于很多候选框对应的是同一个位置,loss值是相近的,所以针对这个问题,提出的解决方法是:对hard做nms,然后再选择样本反向传播,这里nms选择的IoU=0.7。
引言:
人脸检测的发展历程,先是VJ框架(Haar-Like + AdaBoost),然后再到DPM模型,再到深度学习方法的引入。
人脸对齐的发展历程,一般两种方法:回归,模板拟合方法。
然而,以往的人脸检测和人脸对齐方法忽略了这两种任务之间的内在相关性,虽然已有人试图共同解决这些问题,但这些方案仍然存在局限性。
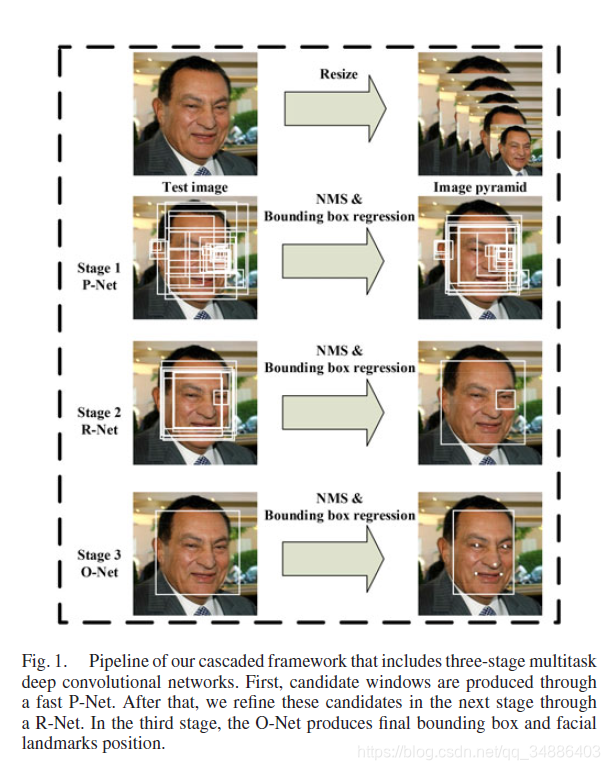
三级CNN
P-Net用于提出候选框,将所提候选框输入到R-Net中,再输入到O-Net中,最后输出bounding box 和facial landmark position
框架简述:
我们最初将图片resize到不同的尺度,以构建一个图像金字塔,这是以下三个阶段级联框架的输入。
Stage 1:P-Net,全卷积网络,获取候选人脸窗口及bounding box回归向量,然后根据估计的bounding box回归向量对候选对象进行校准。在此之后,我们采用非最大抑制(NMS)来合并高度重叠的候选对象。
Stage 2:R-Net,所有Stage 1产生的候选框将输入到R-Net中,这进一步筛选候选框,用bounding box回归进行校准,并进行nms。
Stage 3:O-Net,这一阶段类似于第二阶段,但在这一阶段,我们的目标是识别具有更多监督的面部区域,特别是,该网络将输出五个面部标志的位置。
训练
我们利用三项任务来训练CNN探测器:人脸/非人脸分类、边界框回归和面部标志定位。
由于我们在每个CNN包含不同的任务,所以在学习过程中有不同类型的训练图像,例如脸、非人脸和部分对齐的脸。
在这种情况下,有些损失函数[即(1)-(3)]没有使用。例如,对于背景区域的样本,我们只计算ldet i,另外两个损失设置为0。这可以通过示例类型指示符直接实现。
在训练中使用了Online Hard Sample Mining的策略,
实验
训练数据:
由于我们联合执行人脸检测和对齐,因此在培训过程中我们使用了以下四种不同类型的数据注释:
- negatives,候选框与真实边框(ground-truth )的交集比(IOU)小于0.3;
- positives,候选框与真实边框(ground-truth )的交集比(IOU)大于0.65;
- part faces,候选框与真实边框(ground-truth )的交集比(IOU)在0.4到0.65之间;
- landmark faces,脸标着五个地标的位置。
总训练数据由3:1:1:2(负数/阳性/部分面/地标面)数据组成。
每个网络的训练数据情况如下:
- P-Net:我们随机地从WIDER FACE中裁剪几个patch作为negatives、positives、part faces。然后,我们从 CelebA选取landmark faces。
- R-Net:我们使用框架的第一阶段从WIDER FACE中检测人脸以生成negatives、positives、part faces。而landmark faces则是从CelebA中提取。
- O-Net:类似于R-Net来收集数据,但是我们使用框架的前两个阶段来检测面孔以收集数据。
