题目:SAAN: Semantic Attention Adaptation Network for Face Super-Resolution
中文:SAAN:面向人脸超分辨的语义注意自适应网络
摘要
- 人脸超分辨率(Face SR)是SR的一个子域,可从低分辨率的人脸图像中重建高分辨率的人脸图像。
面部的先验知识被广泛用于恢复更真实的面部细节,这将增加网络的复杂性,并在训练和评估阶段引入额外的知识提取过程。为了解决上述问题,我们提出将人脸语义先验提取和人脸SR与注意力自适应模型相结合,并设计用于人脸SR的语义注意力自适应网络(SAAN)。具体来说,我们通过采用语义注意自适应(SAA)模型将提取人脸先验知识的能力转移到SR网络中,共同训练人脸语义解析网络和人脸SR网络。这样,我们的SR网络就可以在测试阶段独立工作,而无需使用现有的知识提取网络。为了生成逼真的面部图像,我们还利用GAN损失来丰富更多细节的纹理(即SAAN-G)。在基准数据集上进行的大量实验表明,我们的SAAN和SAAN-G在质量和效率上都达到了最新水平。索引词-人脸超分辨率,卷积神经网络,人脸语义解析,注意力适应
背景:面部的先验知识应用于人脸幻觉将增加网络的复杂性
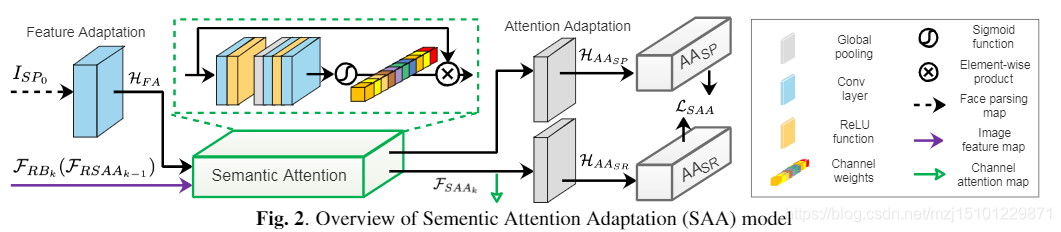
方法:采用语义注意自适应(SAA)模型将提取人脸先验知识的能力转移到SR网络中,共同训练人脸语义解析网络和人脸SR网络。也就是一边提取先验一边超分辨、
结论:大量实验表明,我们的SAAN和SAAN-G在质量和效率上都达到了最新水平。
引言
FSR服务于其他任务
- 人脸超分辨率(人脸SR)又称人脸幻觉,旨在从低分辨率(LR)的图像中恢复高分辨率(HR)的人脸图像。人脸SR是其他相关人脸分析问题的基本任务,例如人脸解析[1],人脸识别[2、3]和人脸对齐[4、5、6]。
主流方法就是学习HR和LR之间的映射
- 最近,已经提出了许多方法来学习HR和LR之间的映射[7,8,9,10]。 Donget al。 [7]提出了一个基于CNN的图像SR框架(SR-CNN),该框架直接学习端到端映射,通过首先使用双三次插值进行上采样来从LR输入中恢复HR图像。 Lim等。 [8]提出了一种没有标准化层的增强的基于残留块的网络(EDSR),它引入了多尺度体系结构(MDSR),可以处理各种SR任务的多个尺度。毛等。 [9]提出了一种深背投影网络(DBPN),该网络可以很好地实现一般图像在8的比例因子下的超分辨率。文献[10]首先将残差信道注意网络(RCAN)引入图像超分辨率,它通过考虑特征通道之间的相互依赖关系来自适应地重新缩放特征,以实现高精度SR。
先验知识的人脸图像对于超分辨率将具有重要意义。
- 考虑到人脸超分辨率是一般图像超分辨率的一个特殊分支,并且不同人脸的组成部分基本相同,因此这种先验知识的人脸图像对于超分辨率将具有重要意义。 [11]提出GLN从面部图像中提取全局和局部信息。朱等。 [12]利用密集的对应域估计来恢复准确的脸部形状。面部成分可以帮助提高面部图像的分辨率[13,14]。 Chen等。 [15]在端到端的可训练人脸超分辨率网络(FSRNet)中优先利用面部几何形状。受RCAN的启发[10],Xinet等。 [16]提出了一种基于剩余频道注意力的多层次信息融合策略,并在像素和语义级别结合了人脸先验信息实现人脸超分辨率。
一些方法中的先验信息的提取需要独立的网络来训练。
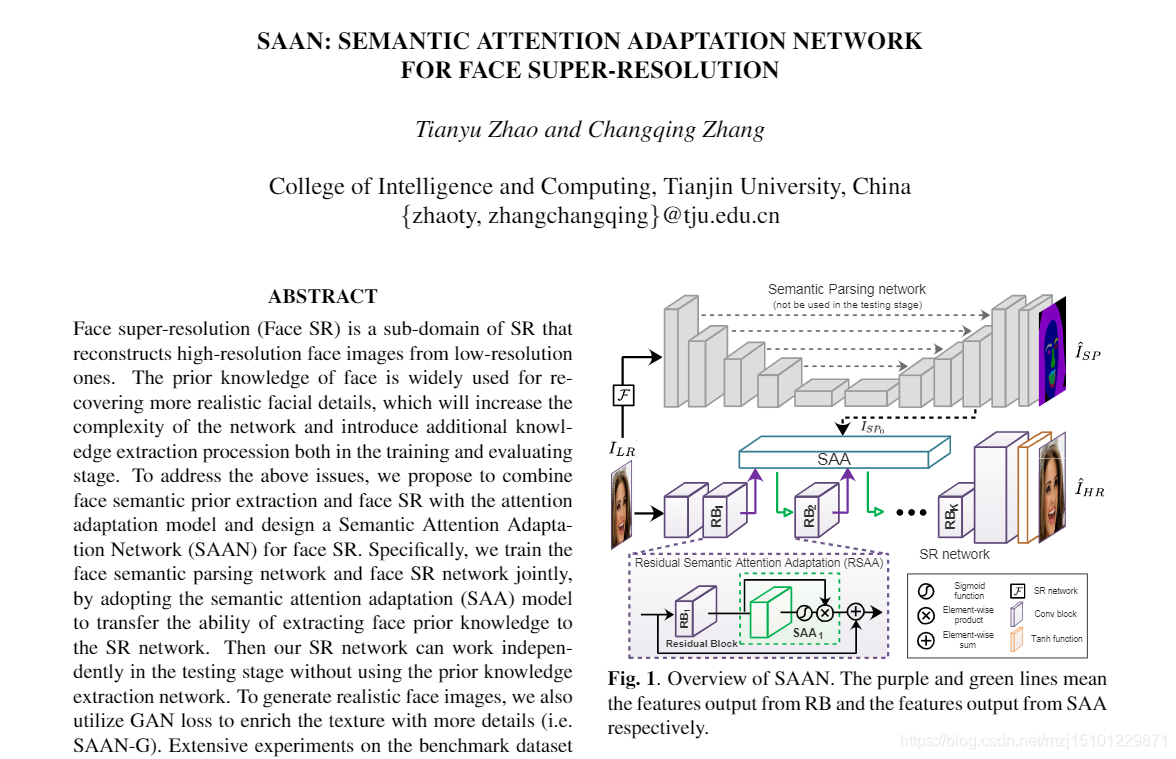
我们的方法是把先验提取的功能加到超分辨网络中。也就是让我们的SR网络具有提取面部先验知识的能力。
-
然而,在这些方法中,面对先验知识提取网络是独立训练的,这阻碍了其更新以为SR网络提取更多有用的信息,并且还导致在测试阶段需要解析(例如,语义分段),更多的计算。【为什么不从LR直接提取先验信息的原因】 **SR网络的性能取决于先验知识的质量,而很难从这样的低分辨率图像中提取先验知识。**在这项工作中,我们提出了一个语义注意适应网络(SAAN),该网络着眼于基于语义注意适应的端到端超分辨率(如图1所示)。在训练阶段,我们联合利用语义解析(SP)网络和超分辨率(SR)网络来提高面部语义解析和超分辨率的性能。受蒸馏学习启发[17],借助语义注意适应(SAA)模型,我们的SR网络具有提取面部先验知识的能力。因此,得益于SAA模型,我们的SR网络可以在测试阶段独立使用,而无需使用语义解析网络。总而言之,我们的SAAN的主要贡献如下:
-
主要贡献:
- 据我们所知,这是将语义注意力自适应模型引入超分辨率网络的第一种方法。
- 超分辨率网络和语义解析网络由SAA模型桥接。因此,通过联合训练,SR网络可以自适应地提取语义先验知识(而不是固定先验知识)来指导SR过程。
- 拟议的SR网络可以在测试阶段独立工作,而无需使用先验知识提取网络( •语义解析网络),从而降低了计算成本。
- 当超分辨率极低的分辨率(16×16像素)和未对齐的人脸图像超分辨率时,所提出的SAAN和SAAN-G达到了最新技术水平。
结论
我们的方法性能最好,并且在真实的低分辨人脸上效果很好。
- 在本文中,我们提出了针对人脸SR的语义注意适应网络(SAAN)。该方法通过注意力自适应模型联合训练人脸先验提取网络和人脸SR网络。通过加强语义注意适应(SAA)模型,我们的语义注意(SA)模型具有从LR人脸图像中提取人脸语义先验的能力。大量的实验结果表明,我们的SAAN可以达到当前最先进的faceSR方法的高性能PSNR / SSIM性能。而且,在未知降级因子的现实世界LR人脸图像上,SAAN-G令人信服地胜过其他竞争算法。
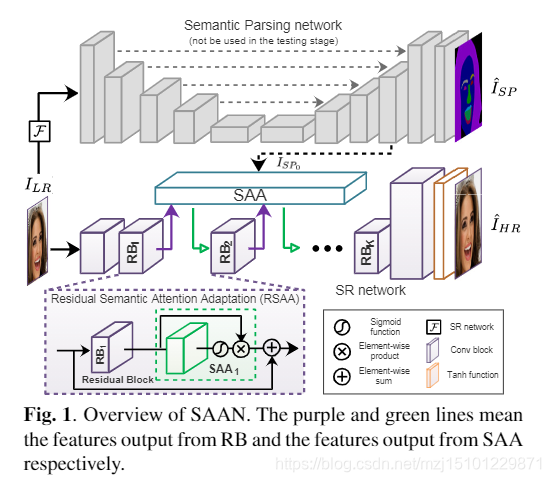
图1. SAAN概述。紫色和绿色线分别表示从RB输出的特征和从SAA输出的特征。
图。2.注意力适应(SAA)模型概述
图3.使用8比例因子的最新方法进行人脸超分辨率的结果
图4.先进的方法在比例尺8上的真实人脸超分辨率结果
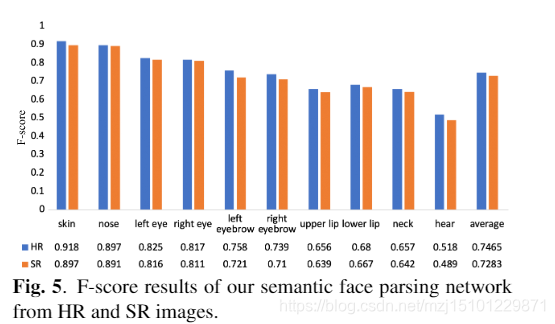
图5.我们从HR和SR图像获得的语义人脸分析网络的F分数结果。
图6.我们面部语义解析的视觉比较。 (a)地面真相HR图像(b)地面真相解析图(c)来自HR图像的结果(d)SR图像(e)SRimages的结果(f)三次三次上采样的图像(g)三次三次上采样的图像的结果。