题目:Face Hallucination Based on Key Parts Enhancement
中文:基于关键零件增强的脸部分割

摘要
- 幻觉的目的是从低分辨率的面部生成高分辨率的面部。
通用的超分辨率方法不能很好地解决此问题,因为人脸具有很强的结构。随着深度学习技术的飞速发展,出现了一些用于面部幻觉的卷积神经网络(CNN)模型,并实现了最先进的性能。在本文中,我们提出了一个**基于人脸五个关键部分的五分支网络。**该网络的每个分支旨在生成高分辨率的关键部分。最终的高分辨率面是五个分支的输出的组合。此外,我们设计了门控增强单元(GEU)并将其级联以形成我们的网络体系结构。实验结果证实,我们的方法可以生成令人愉悦的高分辨率面部。索引词-幻觉,卷积神经网络,超分辨率。
背景:通用超分辨方法不适用于人脸图像
方法:提出了一个**基于人脸五个关键部分的五分支网络。**该网络的每个分支旨在生成高分辨率的关键部分。最终的高分辨率面是五个分支的输出的组合。并且设计了门控增强单元(GEU)并将其级联以形成我们的网络体系结构。
结论:实验结果证实,我们的方法可以生成令人愉悦的高分辨率面部
引言
人脸超分辨服务于其他任务
- 人脸幻觉是人脸分析领域的一个基本问题,可以提高人脸相关任务的性能,如人脸属性分析,人脸对齐,人脸识别等。人脸幻觉的目的是从低分辨率(LR)生成高分辨率(HR)的人脸图像,这是图像超分辨率(SR)的特例。与普通图像SR方法相比[1,2],人脸幻觉的输入图像通常是模糊的,因此人脸幻觉需要更多的先验知识,挑战也相对较大。
面部姿势变化小的情况下,传统方法可用。
传统方法就是通过特征变换解决了LR和HR面部之间的映射。
- 在面部变化很小的前提下提出了早期的面部幻觉方法。 Wang等。 [3]已经通过特征变换解决了LR和HR面部之间的映射。杨等。 [4]通过稀疏表示解决了幻觉问题,可以从低维投影中准确地恢复高分辨率的人脸。杨等。文献[5]通过找到HR和LR图像块之间的匹配关系解决了该问题,并大大提高了人脸幻觉技术的性能。
基于深度学习的方法
- 近年来,随着深度学习技术在计算机视觉领域的广泛应用,研究人员通过深度学习技术解决了人的幻觉问题,并获得了更好的性能。周等。 [6]
设计了一种双通道卷积神经网络(CNN)以实现LR和HR人脸之间的映射,并且在人脸变化较大的情况下取得了良好的效果。在[7]中,Zhu等。提出了一种用于面部幻觉的深层级联双网络。当输入的人脸图像非常小时,网络也获得了良好的幻觉效果。 Yu等。 [8]提出了一种由上采样网络和鉴别网络组成的双重网络结构。借助判别网络,当以8倍放大倍数对小脸图像进行上采样时,上采样网络的性能可以得到显着改善。曹等。 [9]提出了一种基于人的注意力的幻觉模型,并通过深度强化学习对该模型进行了优化。该方法在几个常用数据集上可获得最佳性能。
我们提出的方法
-
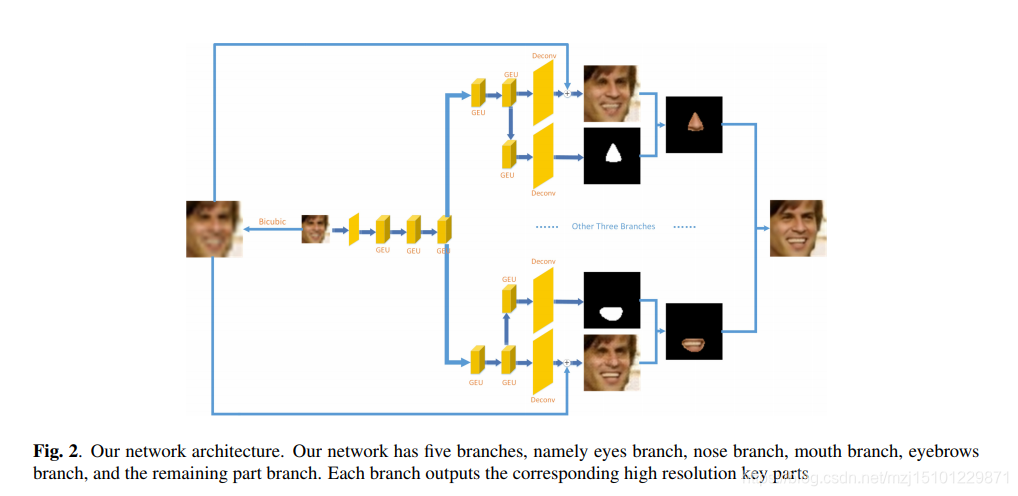
受CNN在计算机视觉任务中最近成功的启发,我们提出了一个五分支网络进行幻觉。我们的方法如图1所示。每个子网旨在生成人脸的不同HR关键部分。
-
由于不同关键部分的模式不同,因此使用五分支网络分别学习每个关键部分要比仅使用一个网络来学习LR和HR人脸之间的映射要好。实验结果表明我们的方法可以产生令人愉悦的HR结果。
-
我们的主要贡献可以归纳为:
- 1)我们基于人脸的五个关键部分,即眼睛,鼻子,眉毛,嘴巴和其余部分,提出了用于面部幻觉的五分支CNN模型。每个子网负责生成HR关键部分。
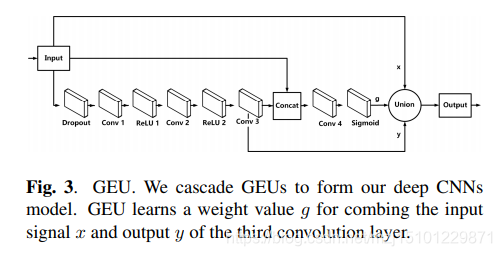
- 2)对于每个子网,我们设计门控增强单元(GEU)并将其级联以形成我们的网络体系结构。设计门控块的主要思想是
用可训练的权重值连接门控块的输入和门控块的输出。 - 3)我们介绍了一种训练五分支网络的技巧,并通过实验结果证明了该模型的优越性。本文的其余部分安排如下。在第2节中,我们描述了提议的五分支网络。然后,我们将提供实验结果并在第3节中讨论拟议的深层CNN模型的结果。最后,在第4节中得出结论。
结论
- 在本文中,我们提出了一个五分支网络的幻觉网络。这个五分支网络旨在生成人脸五个关键部分的高分辨率图像。因此,
通过组合每个分支的输出可获得最终的高分辨率图像。此外,我们提出了门控增强单元,以进一步改善面部幻觉的性能。除此之外,我们介绍了一种训练五分支网络的技巧。实验结果表明,与最新技术相比,我们提出的模型可以产生令人愉悦的结果。

图1.建议的方法。对于输入的LR图像,我们将其发送到建议的五分支网络。每个子网都会生成一个HR关键部分及其掩码。最后,我们根据输出掩码组合每个分支的输出,并获得HR输出
图2.我们的网络架构。我们的网络有五个分支,即眼睛分支,鼻子分支,嘴巴分支,眉毛分支和其余部分分支。每个分支输出相应的高分辨率关键部分
图3. GEU。我们将GEU级联以形成我们的深层CNN模型。 GEU学习一个权重值g,用于合并第三卷积层的输入信号x和输出y
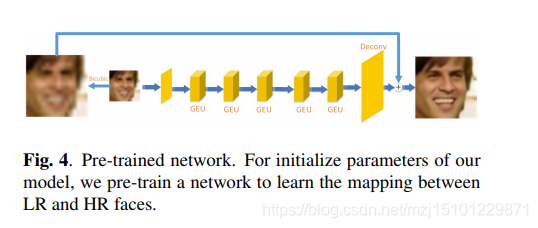
图4.预训练网络。对于模型的初始化参数,我们预训练网络以学习LR和HR面孔之间的映射
图5.测试数据集上×4的可视结果。从左到右:基本事实,双三次插值,SRCNN [1],VDSR [2]和Ours。