题目:Component Attention Guided Face Super-Resolution Network: CAGFace
中文:组件注意导向的人脸超分辨率网络:CAGFace

摘要
- 为了
充分利用人脸的基础结构,通过人脸数据集收集的集体信息以及在上采样过程中的中间估计,我们在本文中引入了针对4倍超分辨率人脸图像的全卷积多级神经网络。 。我们使用分段网络隐式施加了面部组件注意地图,以使我们的网络专注于面部固有模式。我们网络的每个阶段都由一个主干层,一个残留主干和空间上采样层组成。我们周期性地应用阶段来重构中间图像,然后重用其从空间到深度的转换版本来引导并逐步提高图像质量。我们的实验表明,与最新技术相比,我们的脸部超分辨率方法在数量上和感觉上都令人愉悦。
背景:为了充分利用人脸的基础结构、以及在上采样过程中的中间估计
方法:我们网络的每个阶段都由一个主干层,一个残留主干和空间上采样层组成。我们周期性地应用阶段来重构中间图像,然后重用其从空间到深度的转换版本来引导并逐步提高图像质量
结论:实验表明,与最新技术相比,我们的脸部超分辨率方法在数量上和感觉上都令人愉悦。
结论
说明这个网络结构不是端到端的。
- 我们表明,隐式设置注意图和使用中间和最终升级阶段的损失函数来规范超分辨率过程可以显着改善性能,如我们的上等结果所示。我们基于补丁的方法具有处理任何输入尺寸图像的优势。作为未来的工作,我们计划以端到端的方式训练整个网络,包括组件细分部分。
引言
废话
- 我们的大脑非常适合感知面部。除了枕叶的视觉皮层外,大脑的整个部位称为梭状回,被用来解释和形成面部的心理表征[36]。从幼儿期到出生后不久,人脑就具有面部推理能力,并且对面部图像的兴趣比其他任何模式都要多[38]。作为一个物种,我们几乎痴迷地监视并密切关注微妙的细节,以使他们能够深入了解我们周围其他人的出身,情感状态,内部思维过程,参与程度和健康素质。与其他物体类别相比,我们大多数人对面孔的关注程度更高。支持这一点的许多注视追踪研究表明,个人资料图片或头像是在社交媒体资料上吸引人们眼球的第一位[50]。带有人脸的图片比没有脸的图片更有可能获得喜欢。不足为奇的是,几乎有三分之一的社交媒体图像是自拍照,而超过一半的图像是用与面部相关的标签来标记的。
- 脸部的分辨率是至关重要的因素,在个体和文化之间的高分辨率下,自然界似乎更具吸引力[29,34]。尤其是眼部和嘴部区域对于面部感知以及面部神经反应至关重要[44,9]。此外,面部特征的解释取决于面部上下文中各部分的相对排列[37]。因此,注意选择和指导是高分辨率刺激的重要元素,用于建模过程、视觉处理。
服务于人脸对齐和人脸识别
现有方法有限制,输入图像分辨率不能太低、不适用于面部姿势变化较大的人脸。
- 高分辨率的人脸图像不仅为人类观察提供了重要线索,而且为计算机分析提供了重要线索[12,73]。常见面部分析的表现-
当人脸分辨率低时,诸如人脸对齐[3]和识别[49]之类的定位技术会降低。为了提供一种从低分辨率(LR)副本中恢复高分辨率(HR)面部图像的可行方法,许多基于深度学习网络的面部超分辨率方法[74,67,68,66,75,5,8]这些方法中的一些探索了LR和HR脸部之间的直接图像强度对应关系,尽管仅限于低分辨率(例如16×16)输入图像,其中整个脸部都包括在图像中。由于训练和推理时间上的计算和内存需求,它们既不能处理较大的输入面部,也不能重新解析细粒度的特定于面部的模式。此外,它们在近额脸上的依赖性较低,这在流行的数据集中很普遍[35,20],限制了它们在较大的姿势变化中的使用,从而导致面部细节失真。解决该问题的幼稚想法是在训练阶段以较大的姿势变化来增加训练数据。然而,由于要建模的面部数据的方差增加以及面部地标的潜在错误定位,该策略导致效果欠佳的结果,这在大姿态变化下的小LR图像中是一项艰巨的任务。
传统的方法是全局方法,现在提出一个局部方法。
- 在本文中,与以往数十次尝试并通过其神经层应用整个面部图像的尝试相反,我们采用了一种基于补丁的面部超分辨率方法,该方法可在大型输入面部上高效运行。我们的直觉是,尽管要准确地检测到面部的面部地标具有挑战性,但可以估计基于补丁的面部成分注意图,并利用这些注意图来引导超分辨率过程以促进更自然,更准确分辨率增强。
提出我们的方法
-
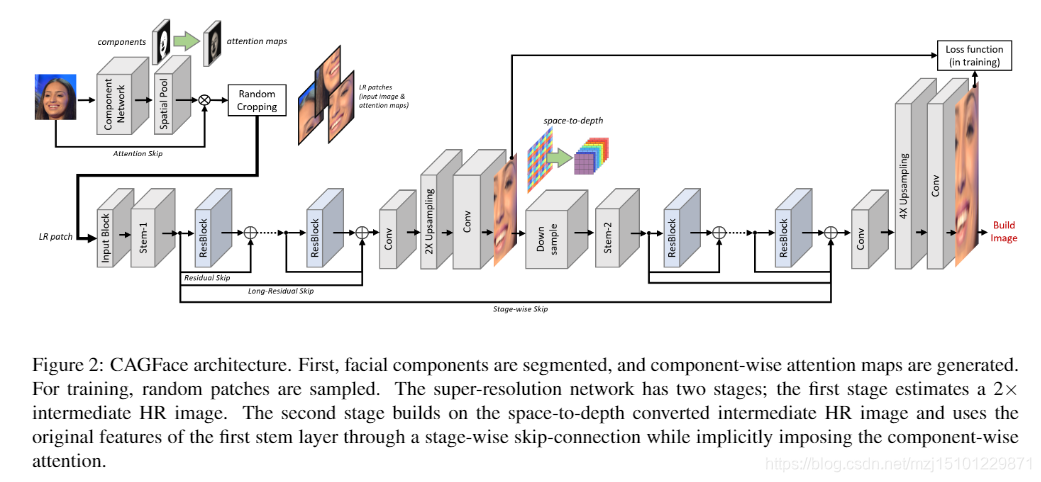
我们的模型包括一个离线训练的组件网络和两个超分辨率阶段。我们首先使用离线训练的神经网络对面部成分进行分割,这些成分可以是头发,皮肤,眼睛,嘴巴,眉毛,鼻子,耳朵,脖子和类似的面部区域。具体来说,我们使用三个组件;为简单起见,头发,皮肤和其他部位(眼睛,嘴巴,鼻子,眉毛,耳朵)。我们采用高斯平滑来降低分量分割误差的敏感性。我们将输入图像的像素值与每个组件热图相乘,以获得热图加权的组件,这使我们可以将组件强加为隐式注意先验。我们将原始图像和注意力图堆叠在一起。在训练阶段,我们
从该面部模型中随机抽取补丁,其中每个补丁都包括裁剪后的原始图像和相应的注意力图。随机采样会生成大小相同的补丁及其增强(翻转)版本。在测试中,我们逐块处理LRimage并汇总其HR估计值。 -
每个超分辨率阶段都有三个主要组成部分,如图2所示;每个超分辨率阶段都有三个主要组成部分。混合输入补丁通道的主干层,将完全卷积块应用到低分辨率特征图上的残余主干以及重构高分辨率图像的空间上采样层。剩余主干由完全卷积的剩余单元组成。在一系列残差单元之后,我们嵌入了从第一个要素层到最后一个要素的直接跳过连接,以保持原始参考图像对最后一层的要素图的影响。因此,我们的主干条件是重建残差信息,其中包括缺少的高分辨率模式的可视数据。残留块和直接跳过连接还使我们能够加深主干网,从而提高了网络的整体表示能力,并为更高级别的卷积层增加了接收域的面积,从而实现了更好的上下文反馈。残留骨干网利用了前一阶段的低分辨率图像和空对地深度混洗后的高分辨率输出,从而可以在随后的阶段将初始模型转移到逐渐复杂的网络中。注意,每个状态都是独立网络。跟随残留骨干,我们应用空间上采样层从其特征图重建更高分辨率的图像。这些层使用具有已知权重的像素混洗;因此,我们不需要去卷积。残留的主干会准备最佳的可能特征图,这些特征图具有大量通道,并且空间上采样层会使用这些层滤镜的权重将这些特征图重新排列为高分辨率图像。
贡献如下
- 总而言之,本文的贡献是:
- •我们为单图像人脸超分辨率引入了基于补丁的,完全卷积的网络,该过程将补丁以其原始低分辨率处理,贯穿其主干和各层,然后进行重构
- •我们反复将超分辨率阶段应用于先前阶段重构的高分辨率输出上,以逐步增强估计的高分辨率细节。
- •如我们的实验所示,我们的方法表现不佳现有的脸部超分辨率方法在不引起感知伪像的情况下大幅度提高。

图1:我们的方法可以对任何大小的人脸图像进行4倍超分辨。第一行:64×64 LR输入和我们的结果。中线:以上图像的放大区域。最下面一行:输入的LR图像为256×256时的放大区域(有关整个图像及其超分辨部分,请参见补充)。请放大以获得最佳视图。
图2:CAGFace架构。首先,将面部组成部分进行分割,并生成针对各个组成部分的注意力图,然后进行随机采样以进行训练。超分辨率网络分为两个阶段:第一阶段估算2倍的中间HR图像。第二阶段基于空间深度转换的中间HR图像,并通过阶段跳跃连接使用第一茎层的原始特征,同时隐含地施加组件注意。
图3:来自组件网络的样本注意图
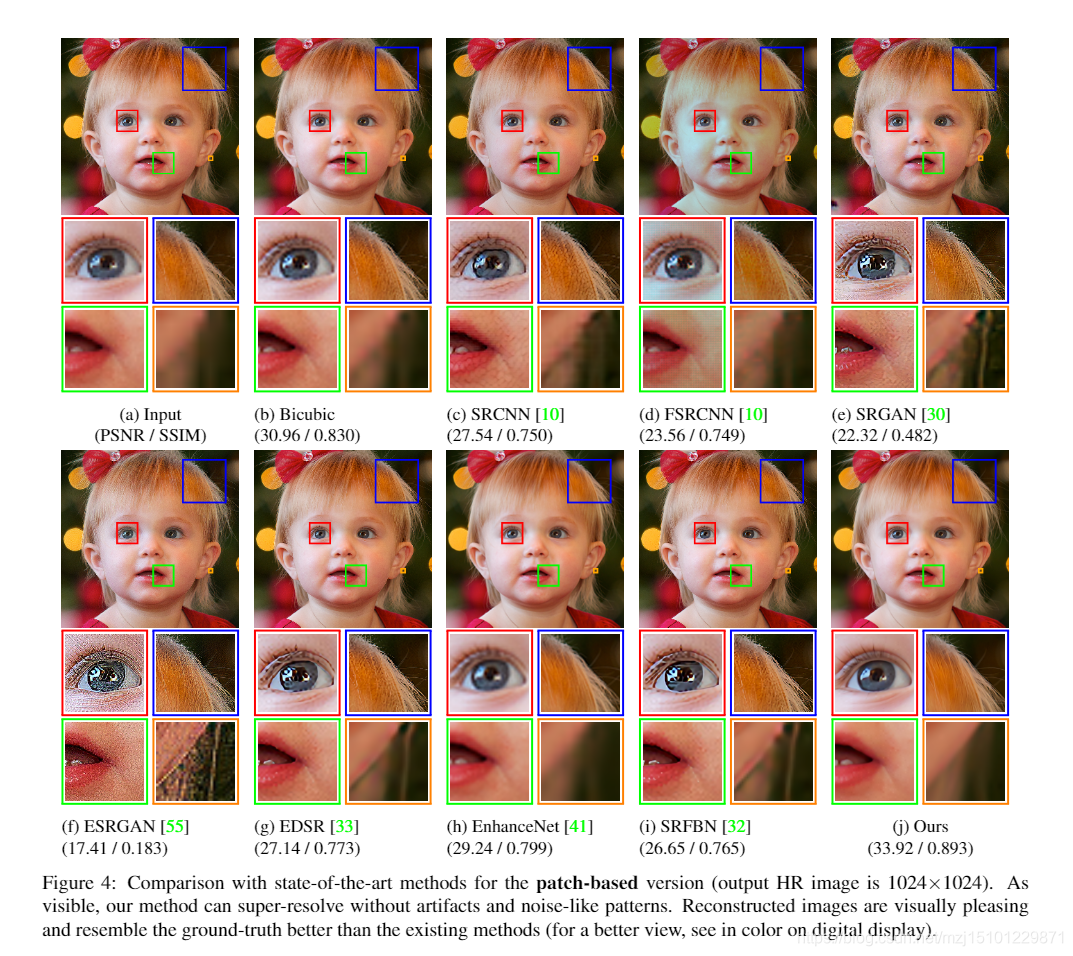
图4:与基于修补程序的版本的最新方法的比较(输出HR图像为1024×1024)。不可见,我们的方法可以超级分辨,而没有伪像和类似噪声的图案。重建后的图像在视觉上令人愉悦,并且比现有方法更像地面真实性(要获得更好的视图,请在数字显示屏上以彩色显示)。
图5:与最先进的全脸转换比较,即以64×64脸部图像作为输入进行训练,以生成4×HR输出,大小为256×256。可见,我们的方法也可为全脸训练产生出色的结果。