题目:Deep Face Super-Resolution with Iterative Collaboration between AttentiveRecovery and Landmark Estimation
中文:Deep Face超分辨率,在Attention Recovery和Landmark估计之间进行迭代协作

摘要
可参考的创新点就是地标估计以及注意力融合模块加强指导先验信息
- 基于深度学习和面部先验的最新作品成功地解决了严重退化的面部图像。但是,现有技术无法充分利用现有方法,因为
诸如地标和成分图之类的面部先验总是通过低分辨率或粗糙的超分辨图像来估计的,这可能不准确,从而影响了恢复性能。本文提出了一种在两个递归网络之间进行迭代协作的深脸超分辨率(FSR)方法,该方法分别专注于面部图像恢复和地标估计。在每个循环步骤中,恢复分支机构利用地标的先验知识来获得更高质量的图像,从而有助于依次进行更准确的地标估计。因此,两个过程之间的迭代信息交互会逐步提高彼此的性能。此外,设计了一种新的注意融合模块以加强地标地图的指导,该地图可以单独生成面部成分并进行集中聚集以实现更好的修复效果。定量和定性实验结果表明,该建议方法明显优于最新的FSR恢复高质量人脸图像的方法。
背景:现有技术无法充分利用深度学习和先验知识进行人脸超分辨
方法:提出在两个递归网络之间进行迭代协作的深脸超分辨率(FSR)方法,该方法分别专注于面部图像恢复和地标估计。两个过程之间的迭代信息交互会逐步提高彼此的性能。
结论:定量和定性实验结果表明,该建议方法明显优于最新的FSR恢复高质量人脸图像的方法。
引言
人脸超分辨服务于人脸识别等面部分析
- 近年来,人脸超分辨率(FSR),也称为人脸幻觉,引起了计算机视觉界的广泛关注。 FSR旨在从低分辨率(LR)对口恢复高分辨率(HR)人脸图像,这在许多应用中都起着重要作用,此外,包括FSR带来的质量改善在内的面部分析技术(包括面部识别和面部对齐)也可以从中受益匪浅。
人脸超分辨是一种特殊的超分辨领域,可以利用人脸的独特的先验信息。
正式由于先验信息,所以在更大的放大因子情况下,人脸超分辨比起通用图像超分辨效果更好。
- FSR是单图像超分辨率(SISR)任务的一种特例[28,29,34,35,44],这是一个具有挑战性的问题,因为它的模糊性很强,超分辨像素。与SISR相比,FSR仅考虑人脸图像而不是任意场景,因此特定的人脸配置对于生成而言可能是先验知识,因此全局结构和局部细节可以相应的恢复。因此,FSR方法在较高的升频因子(例如8x)上表现优于SISR。最近提出了多种面部超分辨率方法[4、9、11、12、14、22、24、33、38]。此外,由于深度卷积神经网络(DCNN)强大的生成能力,深度学习技术的出现极大地提高了面部幻觉效果。
现有方法中对先验信息使用不充分,只是简单的串联操作,应该探索更加有效的使用方案
- 现有FSR方法中已经使用了面部先验。密集对应字段在[46]中用于捕获面部空间配置信息。在[39]中预测面部成分的热图,以提供面部成分的定位以提高SR质量。端到端训练网络[5]FSRNet同时引入面部地标热图和解析图,以提高恢复性能。但是,这种方法存在一些局限性。一方面,由于将定位和对准处理应用于低质量且远离最终结果的LR输入图像或粗糙SR图像,因此它们难以估计准确的先验信息。因此,
给定不准确的先验,SR的指导可能是错误的。另一方面,大多数方法只是将恢复和先验预测作为多任务学习的问题进行优化,并通过简单的串联操作合并先验信息。然而,由于不同组件的结构变化可能没有被完全捕捉和利用,因此这种指导不够直接和清晰。因此,应该探索更有效的利用面部先验的方案。
提出解决方案,两个分支,一个分支用于面部恢复,另一个分支用于地标估计。提出了一个新的注意力融合模块,以整合地标信息,而不是进行串联操作
- 在本文中,我们提出了一种用于人脸超分辨率的深度迭代协作方法,以缓解上述问题。首先,我们设计了一个新的框架,包括两个分支,一个分支用于面部恢复,另一个分支用于地标估计。与以前的方法不同,我们让面部SR和对齐过程相互促进。这个想法的灵感源于
SR分支可以在精确地标地图的指导下生成高保真人脸图像,并且对齐分支也从高质量输入图像中受益匪浅。设计当前的沙漏网络以进行人脸对齐时,可以使用非常深的SR生成模型,而不是传统的堆叠沙漏网络[25]。在每个循环步骤中,每个分支的先前输出将在后续步骤中馈送到另一个分支,以便两个分支相互协作以实现更好的性能。此外,在两个分支中实施的反馈方案都提高了整个框架的效率。其次,我们提出了一个新的注意力融合模块,以整合地标信息,而不是进行串联操作。具体来说,**我们利用估算的地标图生成多个注意图,每个注意图都揭示了一个面部组件的几何配置。受益于特定于组件的注意力机制,每个组件的特征都可以单独提取,这可以通过组卷积轻松实现。**在两个流行的基准数据集CelebA [23]和Helen [19]上的实验结果表明,与最新的FSR方法相比,我们的方法具有超分辨率的高质量人脸图像优势。 - 此处使用地标图的方法可以借鉴一下。
2、相关工作
- Face Super-Resolution
- 近年来,基于深度学习的方法在包括面部超分辨率在内的各种计算机视觉任务中均取得了显着进步。 [41]介绍了一种深度判别式生成网络,可以超分辨非常低的人脸图像。[10]转向小波域,并提出了一个预测HR图像的小波系数的网络。此外,Yuet al。 [40]在人脸超分辨率过程中嵌入属性。[43]引入了超身份损失来衡量身份差异。一些面部SR方法还将解决方案分为全局部分和局部部分。 Tuzeletal。 [32]设计一个包含两个子网的网络:第一个基于全局约束重建人脸图像,而第二个则增强局部细节。曹等人[3]提出使用强化学习来指定有人参与的区域,并使用局部强化网络进行恢复。
- 由于幻觉是特定领域的任务,因此在某些FSR方法中使用了人脸先验。悦尔。 [39]将面部组件热图与网络中间的特征连接起来。 Chenet al。 [5]串联面部特征热图并解析具有特征的图。 Kimetal。 [15]基于面部地标热图设计面部注意力损失,并使用它来训练渐进生成器。 [46]提出了一种深双向网络,该双向网络进行人脸幻觉和人脸对应,以逐步完善这两个过程。但是,级联框架的体系结构是多余且不灵活的,从而限制了模型的效率。此外,缺乏估计准确的密集对应场的能力也可能导致严重的失真。
- Single Image Super-Resolution作为在单图像超分辨率(SISR)中使用深度网络的先驱,Donget等人。 [6]提出SRCNN以学习从双三次插值图像到HR图像的映射。基米[16]通过使用20层VGG-net [30]提出VDSR,以学习LR和HR图像的残差。上面提到的方法主要集中在PSNR和SSIM上。他们的结果大部分是模糊的。近来,SR图像的感知质量越来越受到关注。 SRGAN等。 [20]是第一个生成具有对抗损失和知觉损失的逼真的图像的人[13]。 Radet al。 [27]用目标知觉损失扩大知觉损失。
- 最近,递归网络也被用于单一图像超分辨,基米[17]提出了DRCN,一种深度递归CNN,与先前的工作相比,获得了出色的性能。 [31]使用残差单元构建具有递归块的深度和简洁网络。张格塔尔。 [45]遵循DenseNet [8]的想法,并设计了一个剩余的密集块来融合分层功能。 Hanet al。 [7]设计了一种双重状态的递归网络,可以共同利用LR和HR信号。等等。 [21]引入了一个新的反馈块,其中对要素进行了反复的上采样和下采样。尽管递归网络促进了SISR的发展,但很少有方法将其生成能力用于人脸超分辨率。因此,利用FSR复发机制的潜在能力仍然是一个吸引人的方向。
3、方法
- 在人脸超分辨率中,我们旨在恢复输入的LR人脸图像ILR的面部细节,并获得SR重新结果ISR。我们设计了一个深层的迭代协作网络,该网络可以根据输入的LR图像逐步和逐步地估算出高质量的SR图像和地标图。为了增强SR和对齐过程之间的协作,我们设计了一个新颖的注意力融合模块,该模块有效地集成了两个信息源。最后,我们采用对抗性损失来监督框架的训练,并生成具有高保真度细节的增强型SR人脸。
3.1 深度迭代协作
超分辨和地标检测同时递归进行,相互促进。
-
给定LR面部图像ILR,面部标志对于恢复过程很重要。然而由于缺少很多细节,因此无法通过LR估计先验信息。这样的信息可能无法为SR效果提供准确的指导。因此,我们的方法通过如图2所示的迭代协作方案来缓解此问题。在此框架中,
人脸恢复和界标定位同时并递归地执行。我们可以通过准确的地标图获得更好的SR图像,因为如果输入面具有更高的质量,则可以更正确地估计地标。这两个过程可以互相促进,并逐步实现更好的性能。最后,通过足够的步骤,我们可以获得准确的SR结果和地标性热图。 -
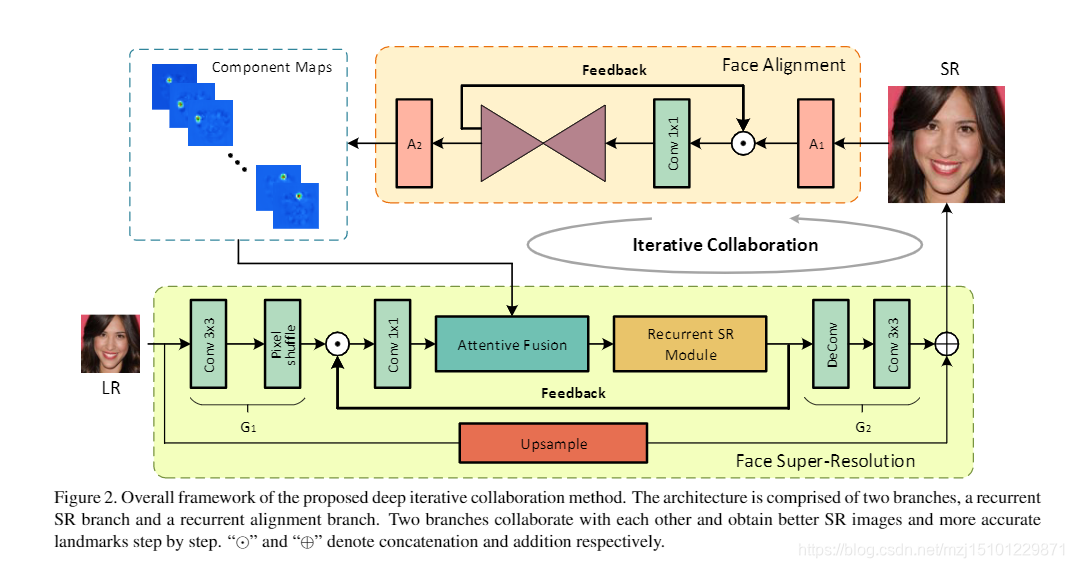
循环SR分支G由低分辨率特征提取器G1,递归块GR和高分辨率生成层G2组成。GR包括注意融合模块和循环SR模块。类似于SR分支,递归对齐分支包括一个预处理块A1,一个递归沙漏块AR和一个后处理块A2。对于随后的n = 1,…,N的步骤,SR分支通过使用对准结果和来自先前步骤n-1的分别表示为Ln-1和fGRn-1的反馈信息来恢复SR图像ISRn。此外,LR输入在每个步骤中也很重要。因此,由G1提取的LR特征也被输入到递归块中。因此,可以通过以下方式来计算面部SR过程:
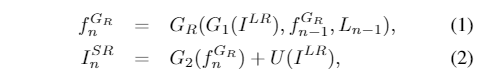
-
U表示升采样操作。同样,人脸对齐分支利用先前步骤fARn-1中的循环特征和由
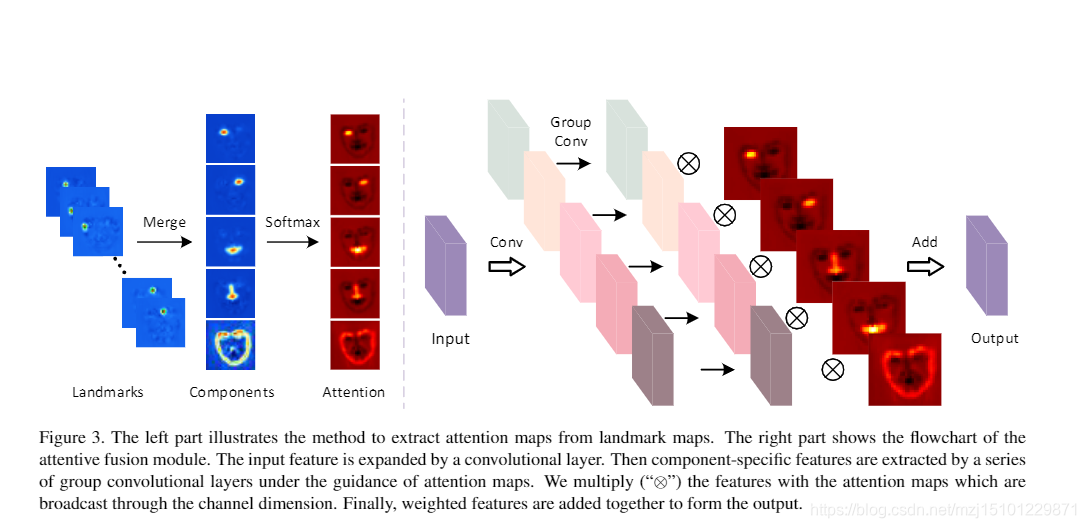
图3.左侧部分说明了从地标地图中提取注意力地图的方法。右侧部分显示了注意融合模块的流程图。输入特征由卷积层扩展。然后在注意图的引导下,由一系列的卷积层提取特定于组件的特征。我们将特征与通过频道维度广播的注意力图相乘(“⊗”)。最后,将加权特征加在一起以形成输出。
3.2 注意力融合模块
不能简单的将先验知识和特征连接起来。
- 在现有方法中,利用面部先验知识的直接方法是将具有SR特征的面部先验连接起来,并将整个优化过程视为多任务学习的问题。但是,由于通常通过共享网络提取不同面部的特征,因此面部结构可能无法得到充分利用。因此,网络可能会忽略存在于不同面部组件中的特定结构构型。**因此,应单独恢复不同的面部部分,以实现更好的性能。**文献[3]通过强化学习来充分利用面部局部的相互依赖关系。然而,连续斑块的重建不能明确有效地利用面部先验,这也限制了不同面部成分的专业化。
- 不同的是,我们通过感知新结构的注意力融合模块实现了上述目标,从而充分利用了地标L的指导。我们假定每个地标热图都有K个通道,用于指示Klandmarks的位置。地标可以分为P个子集,属于面部组件,包括左眼,右眼,鼻子,嘴巴和下巴。将每组中的通道加在一起以形成相应面部组件的热图,表示为{Cp} Pp = 1,如图3所示。这样做而不是直接融合学习过的地标的原因有两个方面:(1)我们明确强调每个面部的局部结构以进行差异恢复; (2)通过分组过程大大减少了通道的数量,从而提高了框架的效率。然后我们可以通过softmax函数沿着这些热图的通道维数来计算相应的注意力图,如下所示:
结论
- 在本文中,我们提出了一种用于人脸超分辨率的深度迭代协作网络。具体而言,**循环SR分支与循环对齐分支协作以迭代和渐进方式恢复高质量的人脸SR图像。**在每个步骤中,SR过程都使用来自对齐分支的估算界标来生成更好的人脸图像,这对于对齐分支估算更准确的界标至关重要。此外,我们提出了一种新的注意力融合模块,以利用注意力图并根据估计的地标提取每个面部成分的个体特征。在两个广泛使用的基准数据集上对人脸SR的定量和定性结果证明了该方法的有效性。
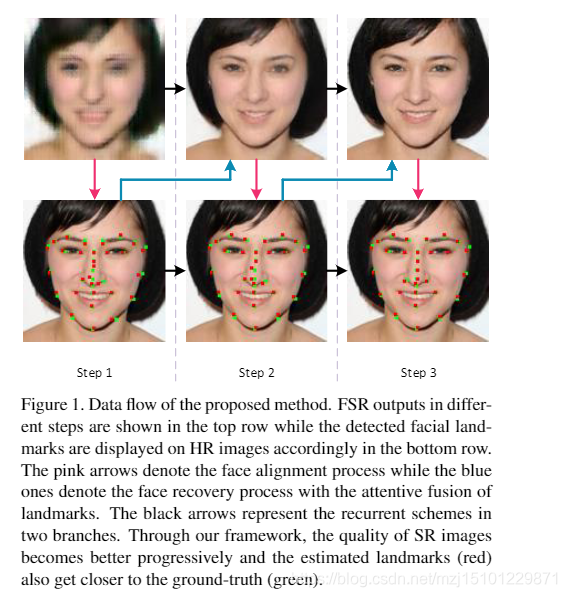
图1.所提出方法的数据流。 FSR输出以不同的步骤显示在顶部行中,而检测到的面部地标则相应地显示在HR图像上的底部行中。粉红色箭头表示面部对齐过程,而蓝色箭头表示具有专心的面部恢复过程地标的融合。黑色箭头表示两个分支中的循环方案。通过我们的框架,SR图像的质量逐渐提高,估计的地标(红色)也越来越接近地面真相(绿色)
图2.提议的深度迭代协作方法的总体框架。该体系结构由两个分支组成,即循环SR分支和递归对齐分支。两个分支机构相互协作,逐步获得更好的SR图像和更准确的地标。 “”和“⊕”分别表示串联和加法
图4.与最新的FSR方法的视觉比较。其他FSR方法可能会在关键的面部部位产生结构变形,也可能会出现不良的假象。我们提出的DIC和DICGAN方法在处理较大的姿势和旋转变化方面具有显着优势。定性比较表明,所提出的方法优于其他FSR方法。最好在屏幕上观看。
图5.不同步骤的视觉比较。通过迭代协作,视觉质量和定量测量都将逐步改善。
图6.所提议的注意力融合模块的视觉效果。第一行显示注意力图和真实图像。第二行显示通过相应面部组件的特征恢复的SR输出。专门针对组件的一代展示了拟议的细心融合模块的有效性。