Improving neural networks by preventing co-adaptation of feature detectors
arXiv preprint arXiv: 1207.0580, 2012
G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
JMLR(Journal of Machine Learning Research), 2014
G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov
解决什么问题
很大的神经网络在小数据集上训练,往往会导致过拟合
对每个训练样本,采用dropout的方法,随机删除一半的神经元,可以有效减少过拟合
模型结合通常能够提高机器学习方法的表现。但是,训练大网络的计算代价太高,又要训练一些不同的大网络,代价就更高了,而且还需要大量的数据,现实中往往没有足够的数据。就算训练了那么多大网络,用来实际应用也是不可行的,因为模型太大导致了很慢的响应速度。
可以使用dropout来防止过拟合,它起到了一个(和结合多个不同网络)近似的效果
为什么能解决
因为dropout防止了复杂的共适应co-adaptation,co-adaptation的意思是每个神经元学到的特征,必须结合其它的特定神经元作为上下文,才能提供对训练的帮助。
减小co-adaptation,就是要使每个神经元学到的特征,能更通用地提供帮助,它必须组合大量的内部上下文信息。
具体做法
每次更新参数之前,每个神经元有一定的概率被丢弃,假设为p%,p可以设为50或者根据验证集的表现来选取,输入层的p比较小,保留概率接近于1
测试阶段不dropout,保留所有单元的权重,而且要乘以保留概率1-p%,为了保证输出期望一致
dropout不只用于前馈神经网络,还可以用于图模型,比如玻尔兹曼机。
对dropout的直观解释
对每个样本都随机地丢弃一半的单元,使得每个单元不能依赖其它单元来做出决策(这样学到的特征更独立)
训练阶段对于每个mini-batch网络的结构是不一样的(因为随机丢弃了一半的单元),测试阶段每个单元乘以保留概率。这样的效果近似于对多个不同的瘦网络做平均(类似集成的效果,能提供更准确的预测)
可以视作一种正则方法,通过给隐藏单元增加噪音
生物学上的motivation
有性生殖取一半父亲基因,一半母亲基因,还有低概率的基因突变,产生后代
无性生殖直接取父代的基因,加低概率的基因突变,产生后代
直觉上无性生殖更好,因为它把父代的优秀基因直接传给了后代。但是有性生殖是物种演化中最重要的方式,一个可能的解释是自然选择的准则并不是保持个体健康,而是基本的混合交流。基因不能依赖于当前已存在的基因,它需要和其它的基因共同协同学习有用的东西。
基于这个理论,使用dropout可以减小和固有神经元之间的依赖,使得它们可以随机地和其它神经元来共同学习,这可以使得神经元更加鲁棒,能够学到更多有用的特征。
权重约束
使用权重约束(也叫Max-norm),大的学习率衰减,高动量可以提升模型表现
用w表示任一隐藏单元的输入向量,当w的l2范式要大于某个阈值c时,把它约束为c。
这样可以使用更大的学习率,因为不用担心w的范式太大导致权重爆炸
dropout提供的噪音允许优化探索不同区域的权重空间(原先难以抵达的区域),所以可以使用较大的学习率衰减,从而做更少的探索,最后陷入最小值
MNIST实验
28*28的手写数字图像,10分类,6万训练集,1万测试集

SVHN(Street View House Number)实验
32323的房子门牌号图像,识别房子门牌号,60万训练集,2万6测试集
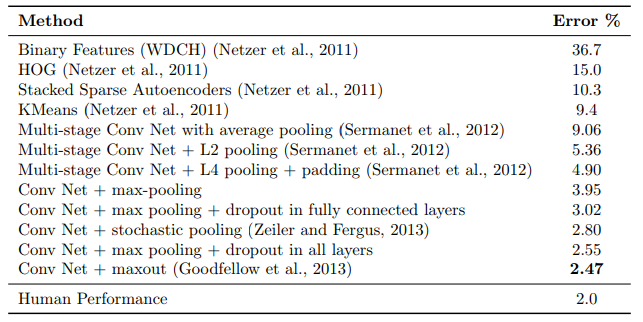
CIFAR-10和CIFAR-100实验
32323的现实图像,10分类和100分类,5万训练集,1万测试集

ImageNet实验
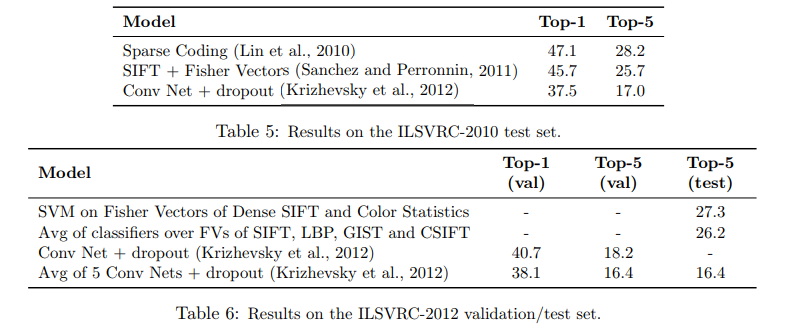
和其它正则化方法的比较

其它
- 和贝叶斯神经网络的比较
- 做了相关实验,发现dropout网络的特征更具有多样性,更稀疏。
- 做了相关实验,讨论了dropout rate和数据集大小对模型表现的影响
- 在测试阶段,通常使用Weight Scaling来预测(前面说的乘以1-p%),但是也可以使用另外一种方法Monte-Carlo来预测。
- 通常使用伯努利分布(p的概率为1,1-p的概率为0)来dropout,但是也可以使用高斯分布来dropout
- 阐述了Dropout RBM的构建和学习