题目: ATSENet :Learning Face Image Super-Resolution throughFacial Semantic Attribute Transformation andSelf-Attentive Structure Enhancement
中文;通过面部语义属性转换和自我注意结构增强来学习人脸图像超分辨率

摘要
- 摘要—人脸超分辨率是一个领域特定的超分辨率(SR)问题,该问题会从低分辨率(LR)输入生成高分辨率(HR)面部图像。即使现有的face SR方法在全局区域评估中取得了出色的性能,【缺点】
但大多数方法仍无法合理地恢复局部属性和结构,尤其是将超小LRface图像(16×16像素)超分辨率放大为较大的版本(8x放大系数)时。在本文中,我们提出了一种基于面部语义属性转换和自我关注结构增强的开源面部SR框架。具体而言,提出的框架以连续的两阶段方式引入面部语义信息(即面部属性)和面部结构信息(即面部边界)。在第一阶段,建立属性转换网络(AT-Net)。它将LR面部图像上采样到HR特征图,然后将面部属性与这些特征结合起来以生成具有合理属性的中间HR结果。在第二阶段,构建结构增强网络(SE-Net)。它同时提取面部特征并从输入中估计面部边界热图,然后将它们融合以输出最终的HRface图像。大量的实验表明,我们的方法具有出色的超分辨结果,并且优于最新方法。索引词-面部超分辨率,面部幻觉,面部属性转换,面部结构增强。
背景:多数方法仍无法合理地恢复局部属性和结构,尤其是将超小LRface图像(16×16像素)超分辨率放大为较大的版本(8x放大系数)时
方法:提出了一个两阶段的人脸超分辨率框架,该框架由人脸语义属性转换和自我关注结构增强组成。将人脸语义和结构信息引入框架,以促进人脸超分辨率的推理。
结论:实验表明,我们的方法具有出色的超分辨结果,并且优于最新方法。
引言
略
- 各种多媒体应用程序[1] – [6]都涉及处理人脸图像,因为人脸图像为身份分析和情感理解提供了丰富而关键的信息。不幸的是,现实世界中人脸图像的质量通常会在获取,传输和存储过程中退化,从而导致人脸模糊和低分辨率。此外,低质量的人脸图像引起了一个严重问题,它将严重阻碍人类视觉感知并大大降低与人脸相关的分析技术。例如人脸识别[1],[7],视频监控[8],[9]。因此,最近已经提出并广泛研究了面部超分辨率技术[10]-[14]。
要利用先验信息才能更好的推理更多的像素信息
- 人脸超分辨率(也称为人幻觉)是特定领域的超分辨率(SR)任务,可以从低分辨率(LR)图像推断出相应的高分辨率(HR)图像。与普通图像SR任务类似,人脸超分辨率也是一个固有的不适定问题,因为每个LR人脸图像可能会映射到许多HR人脸候选者,
这意味着需要合理地推断出相当多的像素信息。例如,当将LR面部图像(32×32像素)超分辨率为可能的HR分辨率(128×128像素)时,几乎93.8%的信息是由面部SR模型(包括一些面部语义和结构)得出的。明智的信息。因此,有必要在人脸语义(即人脸属性)和结构(即人脸成分和地标)信息方面利用信息先验,以促进人脸SR任务的推断,这也是与通用图像SR的主要区别任务。
CNN和GAN应用于超分辨。通常,可以将图像超分辨率视为图像生成的过程
- 最近,卷积神经网络(CNN)[35],[36]已在许多计算机视觉领域证明是成功的,并且在图像超分辨率任务中取得了显着进展。一旦训练好了神经网络,就可以以端到端的方式从LR输入端提取图像特征以从中恢复HR图像。通常,可以将图像超分辨率视为图像生成的过程,在视觉感知和内容理解方面,生成的HR图像与LR输入高度一致。生成对抗网络(GAN)[37] – [40]是一个具有开创性和强大功能的框架,可以生成看起来合理的图像,该图像已经大大推进了许多计算机视觉任务,例如图像样式转换[41],[42]和图像inpainting [43],[44]以及图像超分辨率[22]。
人脸先验(人脸语义、结果先验)的作用是:前者可以帮助描述对象的位置和位置,而后者可以学习对象的存在方式
但是人脸超分辨仍然是一个ill_posed的问题。
- 对于人脸超分辨率任务,非常值得吸收特定的人脸信息,即人脸语义和结构先验。它们在理解人脸的这些语义和结构方面的特征方面起着两个基本作用,因为前者可以帮助描述对象的位置和位置,而后者可以学习对象的存在方式。由于人脸很少有歧义和被误解,因此人脸语义与结构先验之间存在很强的相关性。
面部属性信息是最具代表性的面部语义先验之一。已经提出了一些方法[29],[30],[32],[45]通过引入面部语义属性(例如面部表情,胡须等)来超分辨面部。它们通常将二进制属性向量重塑为与LR图像相同的大小,作为附加的输入通道[30],[32]或将LR图像作为与属性[29]连接的向量。他们的属性转换方案已经取得了一些效果,但是仍有改进的空间。此外,一些方法[27],[28],[33]关注面部结构信息。他们通常从LR面部图像中提取结构先验,然后将其连接到网络作为通道[27],[33],或将其用作网络的监控信号[28]。然而,从LR图像估计面部结构信息是一项艰巨的任务,甚至是一个不适定的问题。
提出方案
-
为了克服上述方法的不足,本文提出了一种新的超分辨LR人脸图像框架,以连续两阶段的方式介绍了人脸语义和结构先验,以提高人脸SR任务的性能。
显式的面部属性被用作面部语义信息,面部边界热图被用作面部结构信息。具体来说,我们介绍了一个属性转换网络(AT-Net)和一个结构增强网络(SE-Net)。AT-Net首先将LR面部图像上采样到与目标图像大小相同的HR特征地图,然后将面部属性信息纳入上采样的HR特征中以生成中间HR面部图像。接下来,**将中间体输入到SE-Net中,该SE-Net联合提取深层面部特征并估计面部边界热图,并通过空间关注机制将它们融合以生成最终的HR面部图像。**此外,还利用了基于图像内容,颜色和纹理的几种不同的聚焦对抗损失函数来改善视觉质量。这项工作的主要贡献如下: -
主要贡献:
- 1)人脸语义和结构信息对于人脸超分辨率都是至关重要的。现有的方法[27]-[29],[32]倾向于只关注其中一种方法,但在语义理解和视觉感知上却未能取得令人满意的结果。我们提出了一种新颖的人脸超分辨率框架,该框架充分利用语义和结构信息(即人脸属性和人脸边界热图)以连续的两阶段方式生成逼真的HR人脸图像。
- 2)不是直接编码LR人脸图像和人脸属性[29],[32]一起,我们建立了一个属性转换网络(AT-Net),该网络首先将LR面部图像上采样到HR特征图,然后将这些特征图与面部属性集成在一起。 AT-Net不仅可以将LR脸部图像超分辨为具有清晰合理属性的HR图像,而且还可以灵活地操纵面部语义属性表示。
- 3)一般情况下,人脸的结构信息是通过一个通道串联组合起来的[27],或者在训练过程中用作监督[28],这不能充分发挥稀缺结构信息的潜力。提出了一种基于空间注意机制的特征融合单元,将人脸边界热图和人脸特征进行融合的结构增强网络(SE-Net),以提高人脸结构信息的重要性。
- 4)我们的方法在多个放大因子(例如4倍和8倍)中产生了显着的可伸缩性。广泛的实验证明了其在视觉结果和客观评估方面的领先优势。
相关工作
B、深度学习的方法
-
得益于CNN强大的学习能力和生成对抗网络(GAN)出色的图像生成性能,基于深度学习的人脸超分辨率方法近来引起了广泛关注。如图2所示,根据是否采用对抗性训练策略,基于深度学习的方法可以大致分为两类:基于CNN的方法和基于GAN的方法。
-
基于CNN的方法在图像超分辨率任务中已经取得了重大进展[17],[18],[52]。 Donget等人[17]首先提出了超分辨率卷积神经网络(SRCNN),以学习LR和HR图像之间的端到端映射。至于人脸超分辨率方法[19],[24],[26],[53],Zhouet等人[53]。使用双通道CNN从LR输入中提取面部特征以预测HR输出。 Caoet等人[24]提出了一种能够引起注意的面部幻觉框架,以恢复面部细节。Zhuet等[19]结合了密集的人脸对应字段估计值和深度级联双网络(CBN)来逐步对人脸图像进行采样。不幸的是,它过于复杂,有效的模型训练需要大量的手动预处理。由于在处理人脸图像时人脸超分辨率和图像生成之间的高度相似性,基于GAN的方法[20],[21],[23],[27],[28],[45],[54]越来越多受欢迎的。伊尼亚托维特人[55]通过设计基于图像到图像GAN的网络将演示文稿转换成高质量的照片。月等[20]构造了一个简单的GAN来超分辨LR人脸图像(URDGN),而无需考虑任何人脸先验。后续工作[23]提出了一种变换-判别式音频编码器(TDAE),以使微小的未对准和嘈杂的人脸图像产生幻觉。如表1所示,详细总结了以前的最新超分辨率方法和相关论文,包括所涉及的面部先验类型。
-
与我们最相关的著作是[29],[32],[27]和[28],其中他们都使用面部语义或结构先验作为辅助来改善面部超分辨率任务。特别是,Yuet等人。 29]将人脸属性嵌入到上采样网络中,并构造一个判别器以区分真实和超分辨的人脸。另外,Luet等人[32]采用条件CycleGAN [42]生成具有目标所需属性的上采样人脸图像。但是,他们将具有属性向量的LR人脸图像连接起来作为一个融合方案。在最终结果中导致失真和幻影伪影。 Chenet等人[27]除了利用面部特征外。估计面部地标热图和解析图,然后将它们连接到由粗到精网络提取的面部特征,生成HR面部图像。然而,在低质量和模糊的面部上检测面部标志是相当困难的,并且比较容易犯错误。此外,预测的人脸解析图还包含许多缺陷,这些缺陷主要表现为不合理的孔洞和模棱两可的区域。信息不完善会导致算法的健壮性降低,同时会产生不可预测的不合逻辑的结果。 Bulat和Tzimiropoulos [28]提出了Super-FAN,它在训练过程中建立了超分辨脸部与地面真相之间的脸部地标热图约束。由于测试时不直接使用脸部结构先验,因此该方法有时会产生负面结果,但结果却很奇怪。姿势和谬误的属性。
-
1)结构增强网络:结构增强网络用于预测人脸边界热图并同时提取人脸特征,然后将其组合以重建HR人脸图像。如图5所示,SE-Net由几个级联的特征提取单元(FEU),边界提取单元(BEU)和FeatureFusion单元(FFU)组成。 FEU用于提取脸部特征,同时通过跳过连接来集成以前的单元的功能。 BEU旨在估计面部边界热图。为了提高边界提取的性能,我们使用了堆叠的BEU的级联,并且在训练过程中对每个中间单元进行了监督。提出了通过空间关注机制融合面部特征和面部边界热图的FFU。实际上,对于每种类型的单元,我们实际上都使用6个来构建SE-Net。
-
4)特征融合单元:为融合人脸特征和人脸结构先验,先前的工作[27],[33]采用了通道级联。然而,与脸部特征相比,提取的脸部先验在数量上相对稀缺,这容易导致脸部先验不堪重负。为了缓解这种情况,我们提出了一种特征融合单元,通过空间关注机制将输入的人脸特征和人脸边界热图结合起来,如图8所示。具体来说,我们首先将从BEU提取的面部边界热图上采样到与从FEU获得的HR面部特征相同的大小。然后,我们获得特定部位的面部边界热图,包括眉毛,眼睛,鼻子,嘴唇和面部外轮廓。特定的人脸边界热图可以集成到整个人脸热图中,它不仅包含人脸语义信息,还包含人脸结构信息。图9示出了人脸边界热图的一些样本。接下来,我们探索一种空间关注机制来融合人脸特征和人脸边界热图。假设F和B分别表示人脸特征和整合的人脸边界热图。细化的特征R定义为
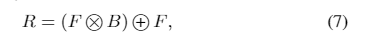
- 其中×和+分别表示元素乘积和元素和的运算。集成的面部边界热图用作蒙版,以关注空间域中面部边界周围的详细纹理,从而易于采用基于元素的乘积。`此外,按元素求和可确保不忽略大多数背景和面对非边界区域的有价值部分。`
- 在SE-Net中,我们提出了三种类型的单元,包括特征提取单元,边界提取单元和特征融合单元。 FEU构成了基本的骨干网。 BEU用于先提取面部边界热图作为面部结构。 FFU确定如何融合先验信息。为了研究单元是否有用和合理,我们在SE-Net中采用了三种不同的配置。第一种是仅使用FEU,这是类似于DenseNet [36]的骨干网络。第二种是使用FEU和BEU,通过通道级联直接组合面部边界热图和面部特征,与[27]相同。 ]。第三是通过使用FFU在空间关注机制中融合面部边界热图和面部特征的标准SE-Net。如表IV所示,仅使用FEU的骨干网会产生较低的PSNR和SSIM。当采用FEU和BEU时,PSNR从25.21 dB增加到25.39 dB。这表明人脸结构先验对人脸超分辨率有积极影响。此外,带有FFU的普通SE-Net将PSNR从25.39 dB提高到25.74 dB,将SSIM从0.6734提高到0.6779。验证了FFU先于融合人脸结构优于粗糙级联特征图的方法。此外,与BEU相比,FFU大大提高了PSNR和SSIM。一种合理的解释是,使用FFU的融合方法可以将结构信息应用于所有特征图,而另一种使用通道级联的融合方法则导致特征图中的结构信息所占比例很小。
提出方法
- 我们的目标是学习从LR面部图像到HR的映射,其中特定的面部语义和结构先验可以促进推理。因此,为面部超分辨率提出了一个两阶段的框架,如图2所示。 3.在第一阶段,将面部语义属性信息嵌入到属性转换网络(AT-Net)中,以确保超分辨的面部图像具有明确的属性和合理的外观。在第二阶段,将面部结构表示为多个面部边界热图。此外,我们提出了一种结构增强网络(SE-Net),该网络同时提取深层面部特征并估计面部边界热图,然后将它们组合以通过空间关注来生成HR面部图像另外,一些评估网络被用来提高框架的性能,这些评估网络侧重于面部图像的感知上重要的属性,例如身份相似度,属性准确性和图像质量。在训练过程中,我们受益于生成的对抗性学习,以使最终的超分辨面孔在视觉上令人愉悦。在本节中,我们将详细介绍拟议的框架,包括相关的网络和培训细节
结论
- 本文提出了一个两阶段的人脸超分辨率框架,该框架由人脸语义属性转换和自我关注结构增强组成。将人脸语义和结构信息引入框架,以促进人脸超分辨率的推理。实验结果表明,人脸语义和结构信息对人脸超分辨率有明显的好处,我们提出的方法优于目前的状态。准确性和真实性方面的替代技术。

图1:使用所提出的方法对真实世界的低分辨率人脸图像进行超分辨率的示例结果。最大的图片是真实世界的降级图像。右列是从前者提取的低质量面部图像(32×32像素)。最下面的一行是我们方法的相应超分辨结果(128×128像素)。
图2:基于深度学习的方法(包括基于CNN和GAN的方法)的示意图。 (a)基于CNN的方法,未引入对抗训练策略。 (b)基于GAN的方法,其中包括通过添加鉴别器进行对抗训练的过程。 (c)为(a)和(b)中的方法构造LR / HR人脸图像对
图3:建议的人脸超分辨率框架。该框架主要通过构建一个AT-Net和SE-Net以及一些评估网络来实现面部语义属性的转换和自我关注结构的增强。
图4:与面部语义属性转换有关的拟议网络。 (a)属性转换网络(AT-Net)。 (b)辨别器网络。 (c)属性预测网络。
图5:结构增强网络的示意图。结构增强网络由级联的特征提取单元(FEU),边界提取单元(BEU)和特征融合单元(FFU)组成。
图6:特征提取单元(FEU)的体系结构
图7:边界提取单元(BEU)的体系结构。
图8:功能融合单元(FFU)的体系结构
图9:人脸边界热图的可视化样本。从左到右:HR脸部图像,脸部边界热图(即眉毛,眼睛,鼻子,嘴唇和脸部外部轮廓),集成脸部热图和叠加了热图的脸部图像。
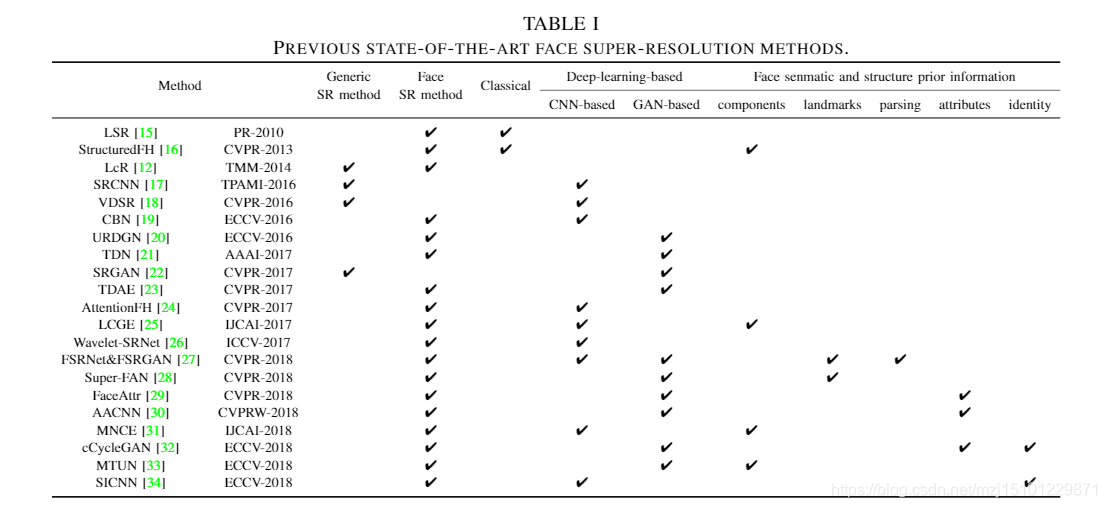


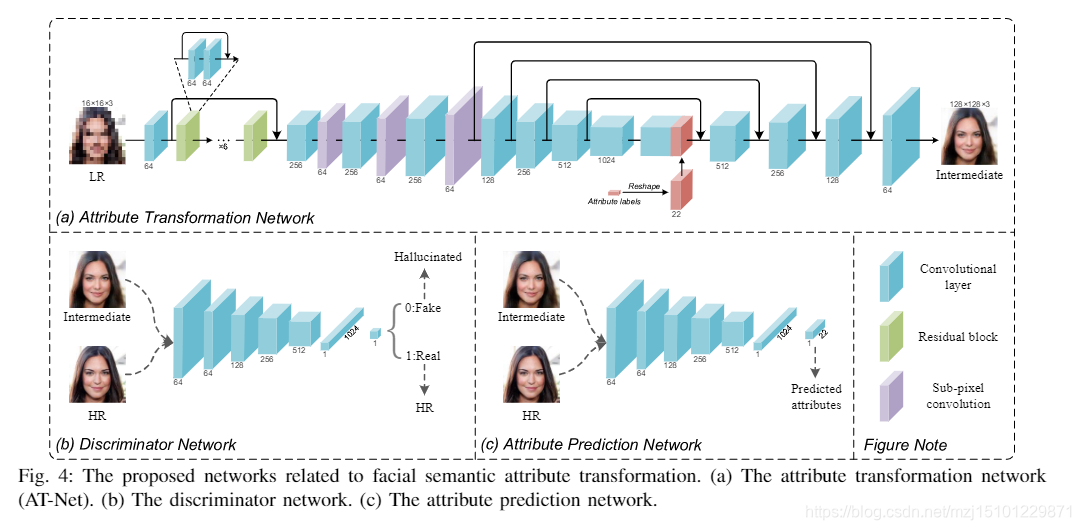
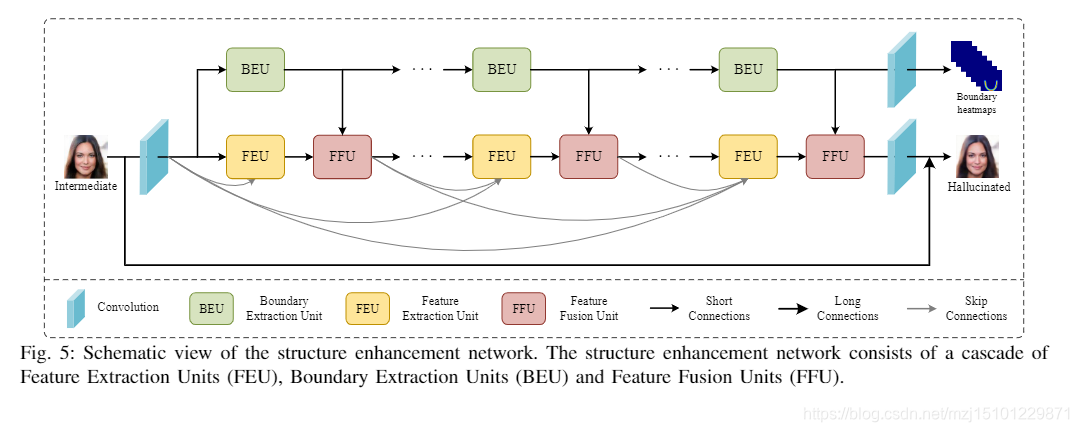
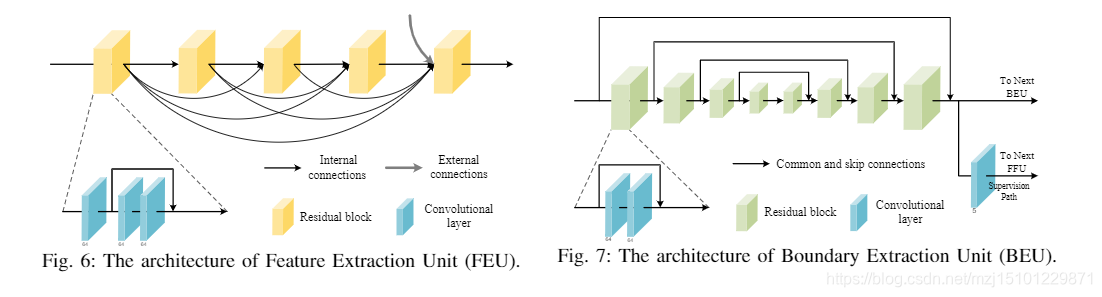
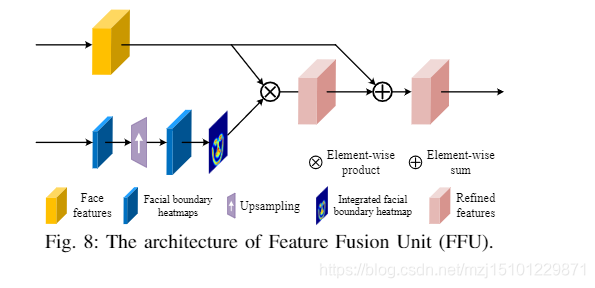


图10:真面面部边界热图的生成过程。 (a)人力资源面部图像。 (b)面对地标。 (c)面界线。 (d)以热图形式的脸部边界。(e)真实的脸部边界热图。

图11:操作属性转换的效果左侧的文本注释是对原始属性的操纵。 (一)LR图像。 (b)人力资源图像。 (c)具有原始属性的结果。 (d)具有操纵属性的结果