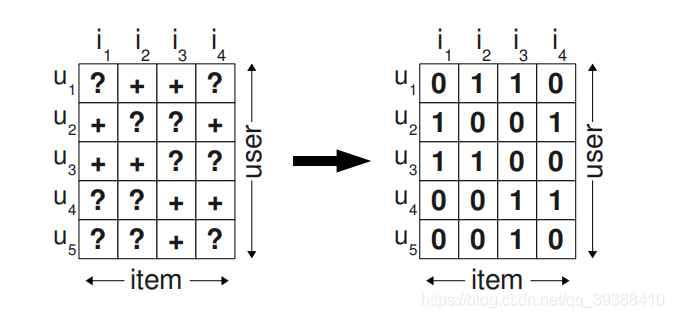
如题,在推荐系统中我们在推荐给用户的商品中一定是需要先后顺序的,即我们需要关心的是用户将会更喜欢我们所推荐的商品,从而得到–个性化排序。但是没错,前几篇所整理的方法目的也是为了预测用户喜好,但往往我们只能通过观察到的正例去估计暗含着负例与缺失值的“?”中,而实际填充也如上图一样,一般用0做填充。然后基于此计算出得分,从某种意义上也可以得到用户优先级的排序,所以首先同样的我们需要解决的问题还是:
对于用户集U和物品集I的对应的 U × I 的预测排序矩阵 X,避免矩阵分解所需要的稠密性,同样采取分解为两个矩阵,即:
然后同样需要寻找最好的W和H,使其与真正X的误差最小,但是与先前的SVD不同,不是尝试对项目打分再排序,而且从整个思想上进行优化,所以作为先验与后验的桥梁----贝叶斯的思想。
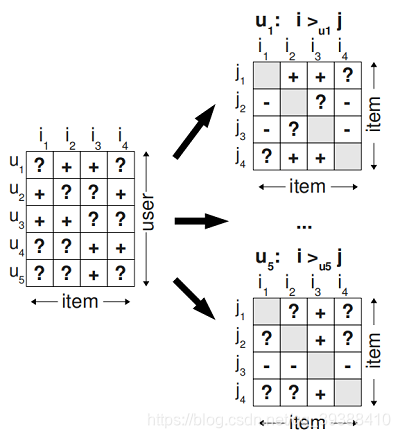
**首先为了排序,引入三元组的概念:即如果用户u在同时有物品 i 和 j 的时候点击了 i,那么定义三元组<u,i,j><u,i,j>,即对用户u来说,i 的排序要比 j 靠前。如上图中,在左侧显示了观测数据和一些未知的“?”数据,三元组处理后,变成在右侧的,“+” 表示用户更喜欢项 i 大于 j 项;“-” 表示更喜欢j而不是i。
基于用户的全序关系的贝叶斯就变成:
其中W和H用
表示,为了得到最好的W,H,即得到最好的
,需要优化后面的这一堆,同样的分母(某用户的全序,对所有的都是物品一样)一样,可以先舍去不考虑。那么对于分子第一项可以有最大似然估计:
其中
P(i >u j | θ)即<u,i,j>,i 排名高于 j。
但是其实,既然是排序–定义使 i 大于 j,那么就使P(i >u j|θ)出现的概率越大越好就行了。那么
而且如果要是一方的概率越大,那么另一方就小就好,那么自然期望他们之间的差异就越大即:
而且这就已经直接是预测矩阵X中的对应位置的值了。即分子第一项变为:
然后分子第二项
,直接使用贝叶斯假设,即
符合正太分布,而总所周知,正太分布的对数形式是跟
成比的!(除了优化式子外,居然还能曲线救国,漂亮的完成了正则化的作用??所以直接假设使用参数符合正太分布的操作设计很巧妙呀)那么整个下来的的式子就直接变成了:
然后同样让我们求导,让我们使用梯度。(不过这里需要使用梯度上升法,因为为了求最大值,即求“上坡”)
所以最后的训练算法为:

def bpr_mf(user_count, item_count, hidden_dim):
u = tf.placeholder(tf.int32, [None])
i = tf.placeholder(tf.int32, [None])
j = tf.placeholder(tf.int32, [None])
with tf.device("/cpu:0"):
user_emb_w = tf.get_variable("user_emb_w", [user_count+1, hidden_dim],
initializer=tf.random_normal_initializer(0, 0.1))
item_emb_w = tf.get_variable("item_emb_w", [item_count+1, hidden_dim],
initializer=tf.random_normal_initializer(0, 0.1))
#矩阵的分解可以理解为embedding的转化
u_emb = tf.nn.embedding_lookup(user_emb_w, u)
i_emb = tf.nn.embedding_lookup(item_emb_w, i)
j_emb = tf.nn.embedding_lookup(item_emb_w, j)
#第一部分的i 和 j的差值计算
x = tf.reduce_sum(tf.multiply(u_emb, (i_emb - j_emb)), 1, keep_dims=True)
mf_auc = tf.reduce_mean(tf.to_float(x > 0))
#第二部分完美的正则项
l2_norm = tf.add_n([
tf.reduce_sum(tf.multiply(u_emb, u_emb)),
tf.reduce_sum(tf.multiply(i_emb, i_emb)),
tf.reduce_sum(tf.multiply(j_emb, j_emb))
])
#整个loss
regulation_rate = 0.0001
bprloss = regulation_rate * l2_norm - tf.reduce_mean(tf.log(tf.sigmoid(x)))
#梯度上升
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(bprloss)
return u, i, j, mf_auc, bprloss, train_op